Нахождение первого и последнего индекса некоторого значения в списке в Python
Есть ли какие-либо встроенные методы, которые являются частью списков, которые дали бы мне первый и последний индекс некоторого значения, например:
verts.IndexOf(12.345)
verts.LastIndexOf(12.345)
10 ответов
У последовательностей есть метод index(value) который возвращает индекс первого появления - в вашем случае это будет verts.index(value),
Вы можете запустить его на verts[::-1] узнать последний индекс. Здесь это будет len(verts) - 1 - verts[::-1].index(value)
Пожалуй, два наиболее эффективных способа найти последний индекс:
def rindex(lst, value):
lst.reverse()
i = lst.index(value)
lst.reverse()
return len(lst) - i - 1
def rindex(lst, value):
return len(lst) - operator.indexOf(reversed(lst), value) - 1
Оба занимают только O(1) дополнительного места, а два реверсирования на месте первого решения намного быстрее, чем создание обратной копии. Давайте сравним его с другими решениями, опубликованными ранее:
def rindex(lst, value):
return len(lst) - lst[::-1].index(value) - 1
def rindex(lst, value):
return len(lst) - next(i for i, val in enumerate(reversed(lst)) if val == value) - 1
Результаты тестов, мои решения - красный и зеленый: 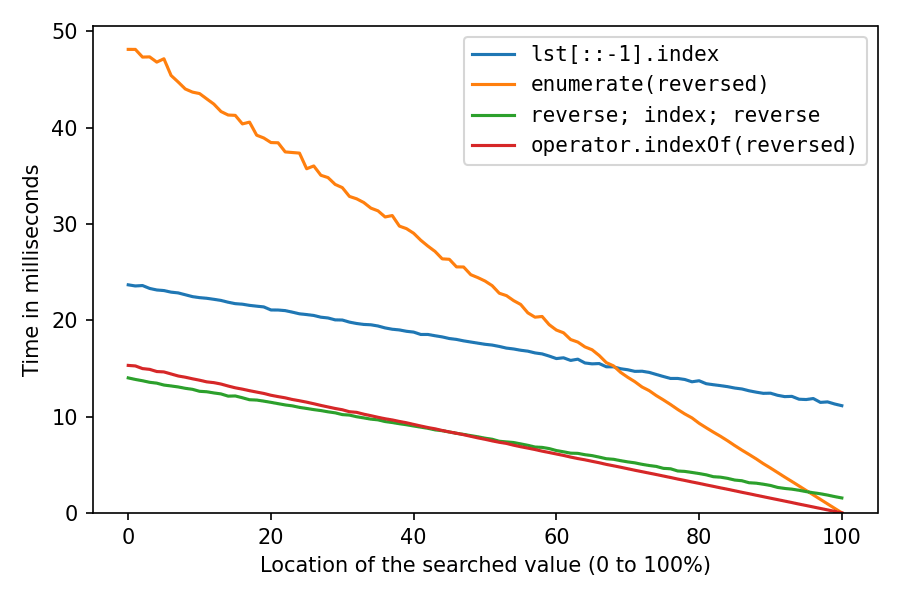
Это для поиска числа в списке из миллиона чисел. Ось x соответствует местоположению искомого элемента: 0% означает, что он находится в начале списка, 100% означает, что он находится в конце списка. Все решения работают быстрее всего на 100%, с двумя
reversed решения, не требующие для этого времени, решение с двойным реверсом занимает немного времени, а обратное копирование занимает много времени.
Присмотритесь к правому концу: 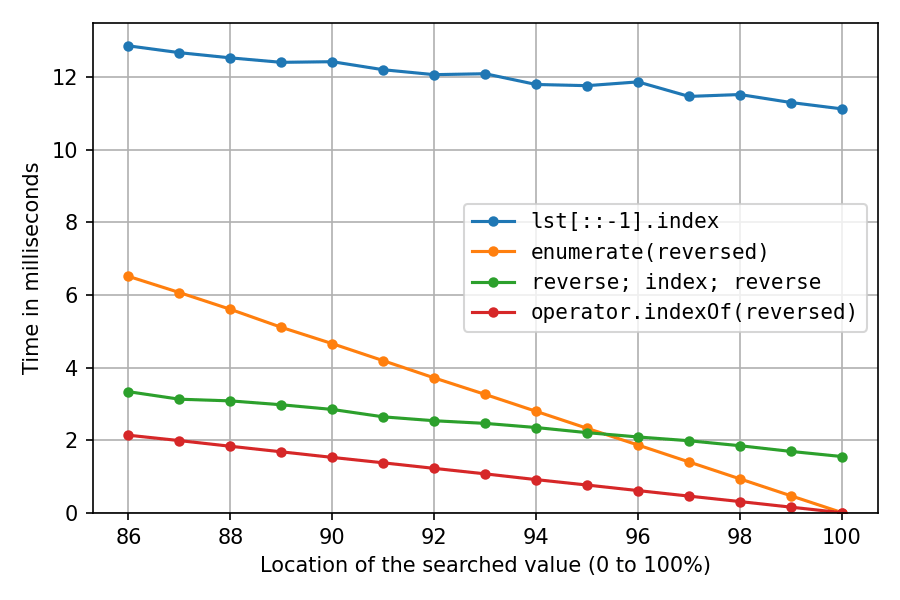
В точке 100% решение с обратным копированием и решение с двойным реверсом тратят все свое время на разворот (index() мгновенно), поэтому мы видим, что два разворота на месте примерно в семь раз быстрее, чем создание обратной копии.
Вышеупомянутое было с
lst = list(range(1_000_000, 2_000_001)), который в значительной степени последовательно создает объекты int в памяти, что чрезвычайно удобно для кеширования. Давайте сделаем это еще раз после перетасовки списка с помощью
random.shuffle(lst) (возможно менее реалистично, но интересно):
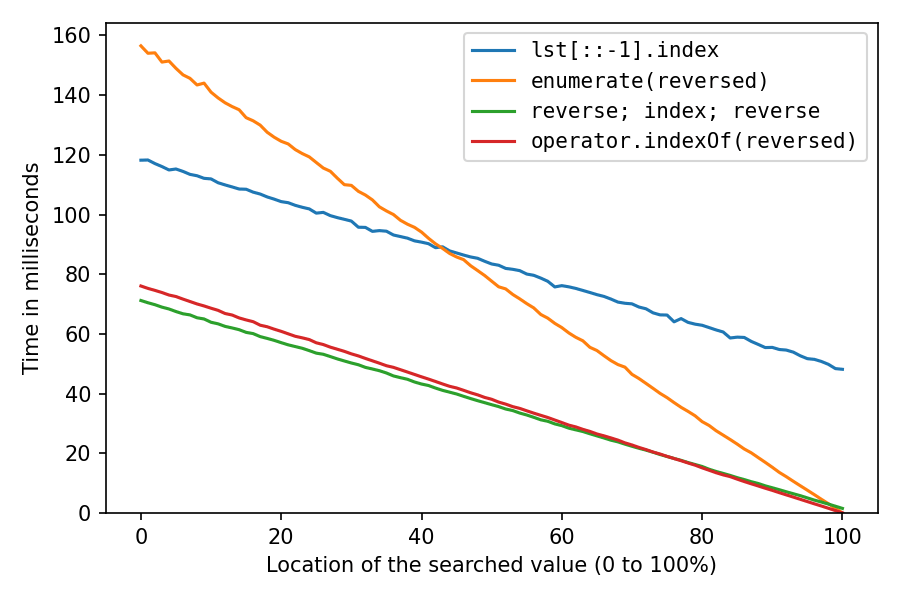
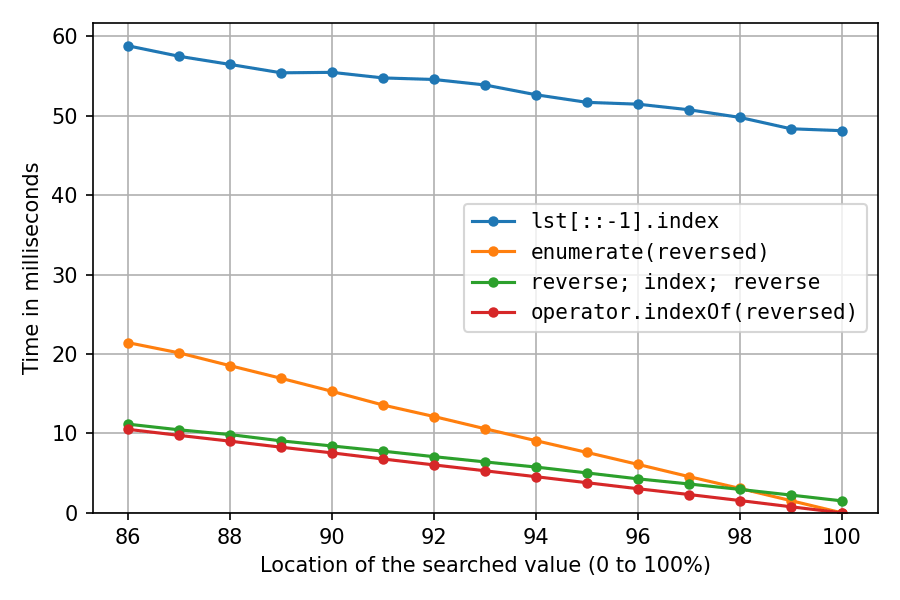
Как и ожидалось, все стало намного медленнее. Решение с обратным копированием страдает больше всего, на 100% оно теперь занимает примерно в 32 раза (!) Больше времени, чем решение с двойным реверсом. И
enumerate-решение теперь второе по скорости только после локации 98%.
В целом мне нравится
operator.indexOf лучшее решение, так как оно является самым быстрым за последнюю половину или четверть всех локаций, которые, возможно, являются наиболее интересными локациями, если вы действительно делаете
rindexдля чего-то. И это только немного медленнее, чем решение с двойным реверсом в более ранних местах.
Все тесты выполнены с использованием 64-разрядной версии CPython 3.9.0 в 64-разрядной версии Windows 10 Pro 1903.
Если вы ищете индекс последнего вхождения myvalue в mylist:
len(mylist) - mylist[::-1].index(myvalue) - 1
Использование i1 = yourlist.index(yourvalue) а также i2 = yourlist.rindex(yourvalue).
В качестве небольшой вспомогательной функции:
def rindex(mylist, myvalue):
return len(mylist) - mylist[::-1].index(myvalue) - 1
Списки Python имеют index() метод, который вы можете использовать, чтобы найти позицию первого вхождения элемента в списке. Обратите внимание, что list.index() повышения ValueError когда значение не найдено в списке, вы можете заключить его в try / except:
def index(lst, value):
try:
return lst.index(value)
except ValueError:
return None
print(index([1, 2, 3], 2)) # 1
print(index([1, 2, 3], 4)) # None
Чтобы эффективно найти позицию последнего вхождения элемента в список, вы можете использовать эту функцию:
def rindex(lst, value):
for i, v in enumerate(reversed(lst)):
if v == value:
return len(lst) - i - 1 # return the index in the original list
return None
print(rindex([1, 2, 3], 3)) # 2
print(rindex([3, 2, 1, 3], 3)) # 3
print(rindex([3, 2, 1, 3], 4)) # None
С использованием
max+
enumerateчтобы получить последнее вхождение элемента
rindex = max(i for i, v in enumerate(your_list) if v == your_value)
Этот метод может быть более оптимизирован, чем выше
def rindex(iterable, value):
try:
return len(iterable) - next(i for i, val in enumerate(reversed(iterable)) if val == value) - 1
except StopIteration:
raise ValueError
Правильным решением является то, которое выполняет «сопоставление обратной петли уровня C».
В псевдо-коде C:
for (int i = len(list) -1; i >= 0; i--)
if list[i] == value:
return i
raise NotFound
В Python правильным решением должно быть:
def rindex(lst, value):
# reversed is a buitin backward iterator
# operator.indexOf can handle this iterator
# if value is not Found it raises
# ValueError: sequence.index(x): x not in sequence
_ = operator.indexOf(reversed(lst), value)
# we must fix the resersed index
return len(lst) - _ - 1
Но было бы лучше иметь встроенный обратный индекс.
s.index(x[, i[, j]])
индекс первого появления x в s (в индексе i или после него и перед индексом j)