Построить документ tfidf 2D график
Я хотел бы построить двухмерный график с осью X в качестве термина и осью Y в качестве оценки TFIDF (или идентификатора документа) для моего списка предложений. Я использовал fit_transform() scikit learn, чтобы получить матрицу scipy, но я не знаю, как использовать эту матрицу для построения графика. Я пытаюсь составить сюжет, чтобы увидеть, насколько хорошо мои предложения могут быть классифицированы с помощью kmeans.
Вот вывод fit_transform(sentence_list):
(идентификатор документа, номер термина) оценка tfidf
(0, 1023) 0.209291711271
(0, 924) 0.174405532933
(0, 914) 0.174405532933
(0, 821) 0.15579574484
(0, 770) 0.174405532933
(0, 763) 0.159719994016
(0, 689) 0.135518787598
Вот мой код:
sentence_list=["Hi how are you", "Good morning" ...]
vectorizer=TfidfVectorizer(min_df=1, stop_words='english', decode_error='ignore')
vectorized=vectorizer.fit_transform(sentence_list)
num_samples, num_features=vectorized.shape
print "num_samples: %d, num_features: %d" %(num_samples,num_features)
num_clusters=10
km=KMeans(n_clusters=num_clusters, init='k-means++',n_init=10, verbose=1)
km.fit(vectorized)
PRINT km.labels_ # Returns a list of clusters ranging 0 to 10
Спасибо,
3 ответа
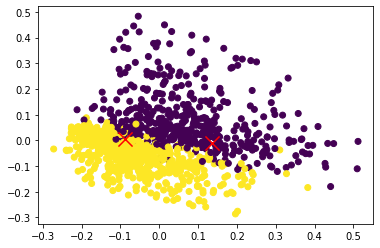
Когда вы используете Bag of Words, каждое из ваших предложений представляется в многомерном пространстве длины, равном словарному запасу. Если вы хотите представить это в 2D, вам нужно уменьшить размер, например, используя PCA с двумя компонентами:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
import matplotlib.pyplot as plt
newsgroups_train = fetch_20newsgroups(subset='train',
categories=['alt.atheism', 'sci.space'])
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
])
X = pipeline.fit_transform(newsgroups_train.data).todense()
pca = PCA(n_components=2).fit(X)
data2D = pca.transform(X)
plt.scatter(data2D[:,0], data2D[:,1], c=data.target)
plt.show() #not required if using ipython notebook

Теперь вы можете, например, рассчитать и построить кластерный вход по этим данным:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2).fit(X)
centers2D = pca.transform(kmeans.cluster_centers_)
plt.hold(True)
plt.scatter(centers2D[:,0], centers2D[:,1],
marker='x', s=200, linewidths=3, c='r')
plt.show() #not required if using ipython notebook
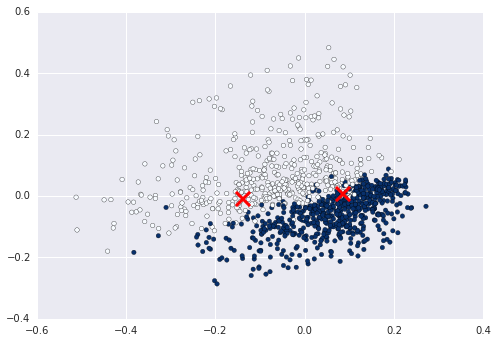
Просто назначьте переменную меткам и используйте ее для обозначения цвета. бывший km = Kmeans().fit(X)
clusters = km.labels_.tolist()затем c=clusters
В предыдущем ответе есть некоторые вопросы. Поэтому я исправляю эти проблемы и помещаю код сюда.
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
newsgroups_train = fetch_20newsgroups(subset='train',
categories=['alt.atheism', 'sci.space'])
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
])
X = pipeline.fit_transform(newsgroups_train.data).todense()
pca = PCA(n_components=2).fit(X)
data2D = pca.transform(X)
plt.scatter(data2D[:,0], data2D[:,1], c=newsgroups_train.target)
plt.show()
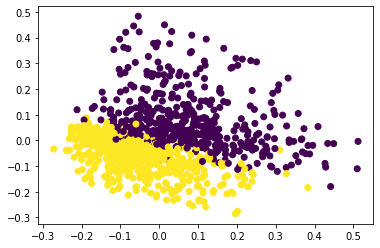
## Nearest neighbour
kmeans = KMeans(n_clusters=2).fit(X)
centers2D = pca.transform(kmeans.cluster_centers_)
# plt.hold(True)
plt.scatter(data2D[:,0], data2D[:,1], c=newsgroups_train.target)
plt.scatter(centers2D[:,0], centers2D[:,1],
marker='x', s=200, linewidths=3, c='r')
plt.show()