Как загрузить URL-адрес Google Диска с помощью curl или wget
Есть ли способ загрузить общедоступный URL-адрес Google Диска с помощью curl или wget? Например, возможность сделать что-то вроде:
curl -O myfile.xls https://drive.google.com/uc?export=download&id=1Wb2NfKTQr_dLoFJH0GfM0cx-t4r07IVl
Обратите внимание, что я делаю это в общедоступном файле без необходимости входить в мою учетную запись Google (или чтобы кто-то еще входил в свою учетную запись и т. Д.).
Если это полезно, у меня есть следующие заголовки:
"kind": "drive#file",
"id": "1Wb2NfKTQr_dLoFJH0GfM0cx-t4r07IVl",
13 ответов
Вам нужно использовать -L переключатель, чтобы сделать curl следовать перенаправлениям, и правильный переключатель для имени файла -o, Вы также должны процитировать URL:
curl -L -o myfile.xls "https://drive.google.com/uc?export=download&id=0B4fk8L6brI_eX1U5Ui1Lb1FpVG8"
Как насчет этого метода? Когда файл имеет такой большой размер, Google возвращает код для загрузки файла. Вы можете скачать файл, используя код. Когда такой большой файл загружается с помощью curl, вы можете увидеть код следующим образом.
<a id="uc-download-link" class="goog-inline-block jfk-button jfk-button-action" href="/uc?export=download&confirm=ABCD&id=### file ID ###">download</a>
Запрос с confirm=ABCD важно для скачивания файла. Этот код также включен в файл cookie. На куки вы можете увидеть это следующим образом.
#HttpOnly_.drive.google.com TRUE /uc TRUE ##### download_warning_##### ABCD
В данном случае "ABCD" - это код. Чтобы извлечь код из файла cookie и загрузить файл, вы можете использовать следующий скрипт.
Пример скрипта:
#!/bin/bash
fileid="### file id ###"
filename="MyFile.csv"
curl -c ./cookie -s -L "https://drive.google.com/uc?export=download&id=${fileid}" > /dev/null
curl -Lb ./cookie "https://drive.google.com/uc?export=download&confirm=`awk '/download/ {print $NF}' ./cookie`&id=${fileid}" -o ${filename}
Если это не было полезно для вас, извините.
Самый простой и лучший способ (с реальным примером файла Google Drive)
Установите gdown используя
pip- Команда -
pip install gdown
- Команда -
Допустим, я хочу скачать cnn_stories.tgz с Google Диска
- Ссылка для скачивания:
https://drive.google.com/uc?export=download&id=0BwmD_VLjROrfTHk4NFg2SndKcjQ
- Ссылка для скачивания:
Пожалуйста, обратите внимание
idПараметр URL0BwmD_VLjROrfTHk4NFg2SndKcjQв ссылкеЭто оно! Загрузите файл, используя
gdowngdown --id 0BwmD_VLjROrfTHk4NFg2SndKcjQ --output cnn_stories.tgz
TLDR: gdown --id {gdrive_file_id} --output {file_name}
Аргументы командной строки:
--id : Google drive file ID
--output: Output File name
Просто
wget --no-check-certificate -r 'https://docs.google.com/uc?export=download&id=FILEID' -O DESTINEATION_FILENAME
Нет необходимости устанавливать какие-либо внешние инструменты.
- Сделать файл общедоступным на Google Диске
- Открыть общую ссылку в режиме инкогнито
- Нажмите кнопку загрузки
- Скопировать как запрос загрузки curl из вкладки сети
- Вставить скопированный запрос на сервер и добавить флаг вывода (- output)
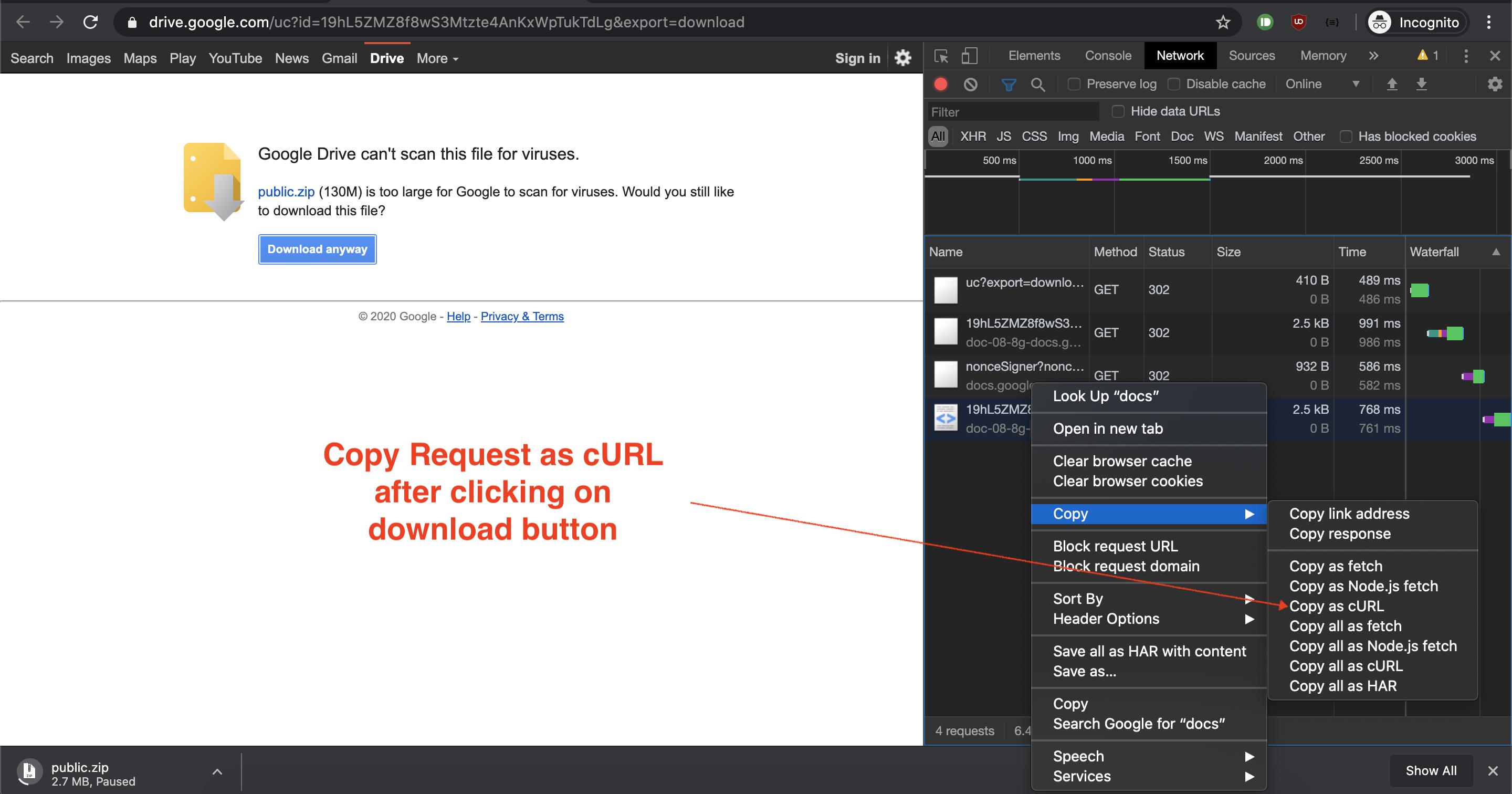
Я только что проверил ответ @tanaike, и он работает как шарм. Но решение, предложенное @Martin Broadhurst и принятое автором темы, не дает.
Поскольку гугл показывает предупреждение о проверке на вирусы, которое необходимо обработать, необходим скрипт soc.
Я бы хотел проголосовать за ответ @ tanaike, но у меня недостаточно репутации, чтобы сделать это:)
Кроме того, для тех, кто не знает, как получить и идентифицировать файл на диске Google, я хотел бы поделиться этими довольно простыми знаниями.
- перейти к вашему gDrive
- щелкните по нему правой кнопкой мыши и выберите "Поделиться"
- выбрать публичный общий доступ для всех, у кого есть ссылка без входа в систему
скопировать URL-адрес https://drive.google.com/file/d/1FNUZiDDDDDDSSSSSSAAAAAdv42Qgzb6n8d/view?usp=sharing
вставьте его в блокнот
- ID является частью URL: 1FNUZiDDDDDDSSSSSSAAAAAdv42Qgzb6n8d
Наслаждайтесь!
По состоянию на 18 ноября 2019 года, чтобы использовать wget для загрузки файла с Google Диска, я использовал следующий метод. Для этого метода нам нужно знать, относится ли размер нашего файла к категории small или large. Я не мог определить точное число, которое различает маленькие и большие размеры, но я полагаю, что это где-то около 100 МБ. Но вы всегда можете использовать любой из двух методов, упомянутых для ваших файлов, так как один будет работать только для малых, а другой - для больших.
Основные шаги, которым необходимо следовать
Шаг 1 Сделайте свой файл "доступным для всех, у кого есть Интернет". Это можно сделать, щелкнув файл правой кнопкой мыши -> нажмите кнопку "Поделиться" -> щелкните переключатель "Достижения" -> измените доступ к "Общедоступному в Интернете".
Шаг 2 Сохраните его и нажмите Готово.Шаг 3 Еще раз щелкните файл правой кнопкой мыши и выберите "Получить ссылку для совместного использования". Это скопирует ссылку в буфер обмена.
Шаг 4 Скопируйте все после ? Id= до конца и сохраните в файл блокнота. Это ваш FILE_ID, который используется ниже.
Шаг 4 Выполните указанные ниже шаги в зависимости от размера файла после выполнения вышеуказанных общих шагов.
Маленькие файлы
Шаг 1 Используйте команду:
wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILE_ID' -O FILE_NAME_ALONG_WITH_SUFFIX
FILE_ID должен быть скопирован с шага выше, а FILE_NAME_ALONG_WITH_SUFFIX - это имя файла, который вы хотите сохранить в своей системе / сервере. Обратите внимание, что не забудьте добавить суффикс, например (.zip,.txt и т. Д.)
Шаг 2 Запустите команду. Он может показать ошибку "Не применять HSTS", но это нормально. Ваш файл будет скопирован.
Большие файлы
Шаг 1 Используйте команду
wget --no-check-certificate --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=FILE_ID" -O FILE_NAME_ALONG_WITH_SUFFIX && rm -rf /tmp/cookies.txt
Измените FILE_ID в 2 местах и FILE_NAME_WITH_SUFFIX один раз.
Шаг 2 Выполните команду, она может выдать ту же ошибку, что и упомянутая выше, но это нормально.
Надеюсь, это поможет..
Вы можете использовать инструмент под названием gdrive вместо wget / curl. По сути, это инструмент для доступа к учетной записи Google Drive из командной строки. Следуйте этому примеру, чтобы настроить его для машины Linux:
- Сначала загрузите исполняемый файл gdrive здесь.
- Распакуйте его и получите исполняемый файл
gdrive. Теперь измените права доступа к файлу, выполнив командуchmod +x gdrive. - Запустить
./gdrive aboutи вы получите URL-адрес с просьбой ввести код подтверждения. В соответствии с инструкциями в приглашении скопируйте ссылку и перейдите по URL-адресу в своем браузере, затем войдите в свою учетную запись Google Диска и предоставьте разрешение. Наконец-то вы получите код подтверждения. Скопируйте это. - Вернитесь к своему предыдущему терминалу и вставьте код подтверждения, который вы только что скопировали. Затем проверьте свою информацию там.
Теперь, после успешного завершения процесса аутентификации, описанного выше, вы можете перемещаться по файлам на вашем диске с помощью команд, упомянутых ниже.
./gdrive list # List all files' information in your account
./gdrive list -q "name contains 'University'" # serch files by name
./gdrive download fileID # Download some file. You can find the fileID from the 'gdrive list' result.
./gdrive upload filename # Upload a local file to your google drive account.
./gdrive mkdir # Create new folder
Процесс нужно выполнить только один раз, и он работает без сбоев.
Это решение работает даже для больших файлов без файлов cookie.
Хитрость заключается в параметре запроса &confirm=yes . Затем:
wget "drive.google.com/u/3/uc?id=FILEID&export=download&confirm=yes"
For small file
Run following command on your terminal:
wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILEID' -O FILENAME
In the above command change the FILEID by above id extracted and rename FILENAME for your own simple use.
For large file
Run the following command with necessary changes in FILEID and FILENAME:
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILEID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=FILEID" -O FILENAME && rm -rf /tmp/cookies.txt
You can also use this single purpose website to generate this command for you.
Вот лучший способ сделать это с помощью CURL, шаг за шагом:
Windows 10 имеет CURL по умолчанию, но ниже относится к любым машинам.
Сначала создайте прямую ссылку на свой файл. Простой инструмент , как этого поможет, я перечислил некоторые из того, что я здесь в случае , если один здесь войдет когда - нибудь.
Или просто замените XXX ниже на свой идентификатор файла.
https://drive.google.com/uc?export=download&id=XXXXXXXXXXXXXXXXXXXXXXXX
Примечание. Файл на Диске должен быть доступен всем, у кого есть ссылка. инструкции здесь .
Теперь откройте новую вкладку и вставьте новые сгенерированные ссылки, и файл будет автоматически загружен.
Однако, если он показывает печально известную страницу «сканирование на наличие вирусов / невозможно сканирование на наличие вирусов», то мы пока не можем использовать его с CURL.
Вам необходимо создать API-интерфейс Google Drive и вместо этого использовать приведенную ниже структуру ссылок:
https://www.googleapis.com/drive/v3/files/XXXXXXXXX?alt=media&key=YYYYYYYYY
XXXXX - это идентификатор вашего файла, а YYYYY - это КЛЮЧ API (в настоящее время версия 3). В качестве альтернативы вы можете использовать этот генератор в качестве вспомогательного средства.
Но опять же, вам сначала понадобится API, поэтому зайдите ЗДЕСЬ, чтобы узнать, как это сделать.
Теперь, когда прямая ссылка готова, самое важное - убедиться, что у вас установлен USER AGENT в вашей команде CURL, потому что без него вы получите сообщение об ошибке, говорящее, что вы достигли пределов. Вот последняя команда:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" -L "https://www.googleapis.com/drive/v3/files/XXXXXXXXXXXXXXXXXXX?alt=media&key=YYYYYYYYYYYYYYYYYYYY" -o filename.zip
Вышеуказанное установлено для версии но должно работать на любых машинах в любом случае. Он только имитирует браузер, думая, что это Chrome для Windows 10 и более поздних версий. см. последнейздесьChrome на пользовательских агентах Windows, последнюю версию, так как использование СТАРОГО UA также вызывает ошибку.
Если вы сочтете это полезным, дайте мне знать,
Чтобы wget успешно работал с большими файлами, используйте ссылку с запросом подтверждения для загрузки.
Сначала получите информацию по этой ссылке на Google Диске с идентификатором. В вашем случае идентификатор - 1Wb2NfKTQr_dLoFJH0GfM0cx-t4r07IVl.
А затем получите имя файла, который хотите скачать.
Затем используйте это: """wget --load-cookies /tmp/cookies.txt" https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies / tmp / cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILEID' -O- | sed -rn 's /.confirm =([0-9A-Za-z_]+)./\1\ n / p ')& id =FILEID "-O FILENAME && rm -rf /tmp/cookies.txt" "" и замените FILEID идентификатором, который вы получить по ссылке и переменную FILENAME с именем вашего файла
Для получения любой справки терпеливо просмотрите эту ветку https://gist.github.com/iamtekeste/3cdfd0366ebfd2c0d805. Вы можете получить много полезных методов.
curl gdrive.sh | bash -s 0B4fk8L6brI_eX1U5Ui1Lb1FpVG8
0B4fk8L6brI_eX1U5Ui1Lb1FpVG8 - это идентификатор файла.