Сохранить вывод PL/pgSQL из PostgreSQL в файл CSV
Какой самый простой способ сохранить вывод PL/pgSQL из базы данных PostgreSQL в файл CSV?
Я использую PostgreSQL 8.4 с плагином pgAdmin III и PSQL, откуда я запускаю запросы.
22 ответа
Вы хотите получить полученный файл на сервере или на клиенте?
Серверная сторона
Если вы хотите что-то простое для повторного использования или автоматизации, вы можете использовать встроенную в Postgresql команду COPY. например
Copy (Select * From foo) To '/tmp/test.csv' With CSV DELIMITER ',';
Этот подход полностью работает на удаленном сервере - он не может записывать на локальный компьютер. Он также должен быть запущен как "суперпользователь" Postgres (обычно называемый "root"), потому что Postgres не может остановить его, делая неприятные вещи с локальной файловой системой этого компьютера.
Это на самом деле не означает, что вы должны быть подключены как суперпользователь (автоматизация, которая будет представлять угрозу безопасности другого типа), потому что вы можете использовать SECURITY DEFINER возможность CREATE FUNCTION сделать функцию, которая работает так, как если бы вы были суперпользователем.
Важнейшей частью является то, что ваша функция предназначена для выполнения дополнительных проверок, а не просто для обхода защиты - так что вы можете написать функцию, которая экспортирует точные данные, которые вам нужны, или вы можете написать что-то, что может принимать различные параметры, если они встретить строгий белый список. Вам нужно проверить две вещи:
- Какие файлы должны быть разрешены пользователю для чтения / записи на диске? Например, это может быть определенный каталог, а имя файла может иметь подходящий префикс или расширение.
- Какие таблицы должен иметь пользователь для чтения / записи в базе данных? Обычно это определяется
GRANTнаходится в базе данных, но функция теперь работает как суперпользователь, поэтому таблицы, которые обычно бывают "вне границ", будут полностью доступны. Вы, вероятно, не хотите, чтобы кто-то вызывал вашу функцию и добавлял строки в конец вашей таблицы "users"...
Я написал сообщение в блоге, расширяющее этот подход, включая некоторые примеры функций, которые экспортируют (или импортируют) файлы и таблицы, отвечающие строгим условиям.
Сторона клиента
Другой подход заключается в обработке файлов на стороне клиента, то есть в вашем приложении или скрипте. Серверу Postgres не нужно знать, в какой файл вы копируете, он просто выплевывает данные, а клиент помещает их куда-то.
Основной синтаксис для этого является COPY TO STDOUT команда, и графические инструменты, такие как pgAdmin, обернут его для вас в хороший диалог.
psql клиент командной строки имеет специальную "мета-команду" \copy, который принимает все те же варианты, что и "настоящий" COPY, но запускается внутри клиента:
\copy (Select * From foo) To '/tmp/test.csv' With CSV
Обратите внимание, что нет окончания ; потому что мета-команды заканчиваются символом новой строки, в отличие от команд SQL.
Из документов:
Не путайте COPY с инструкцией psql \copy. \copy вызывает COPY FROM STDIN или COPY TO STDOUT, а затем извлекает / сохраняет данные в файле, доступном для клиента psql. Таким образом, доступность файла и права доступа зависят от клиента, а не от сервера при использовании \ copy.
Ваш язык прикладного программирования также может иметь поддержку для извлечения или извлечения данных, но вы не можете обычно использовать COPY FROM STDIN / TO STDOUT в пределах стандартного оператора SQL, потому что нет способа соединить поток ввода-вывода. PHP-обработчик PostgreSQL (не PDO) включает в себя очень простой pg_copy_from а также pg_copy_to функции, которые копируют в / из массива PHP, что может быть неэффективно для больших наборов данных.
Есть несколько решений:
1 psql команда
psql -d dbname -t -A -F"," -c "select * from users" > output.csv
Это имеет большое преимущество, что вы можете использовать его через SSH, как ssh postgres@host command - позволяет вам получить
2 постгрес copy команда
COPY (SELECT * from users) To '/tmp/output.csv' With CSV;
3 psql интерактивный (или нет)
>psql dbname
psql>\f ','
psql>\a
psql>\o '/tmp/output.csv'
psql>SELECT * from users;
psql>\q
Все они могут быть использованы в сценариях, но я предпочитаю # 1.
4 пгадмина но это не в сценарии.
В терминале (при подключении к БД) установите вывод в файл cvs
1) Установите полевой разделитель на ',':
\f ','
2) Установите формат вывода без выравнивания:
\a
3) Показывать только кортежи:
\t
4) Установите выход:
\o '/tmp/yourOutputFile.csv'
5) Выполните ваш запрос:
:select * from YOUR_TABLE
6) Выход:
\o
После этого вы сможете найти свой CSV-файл в этом месте:
cd /tmp
Скопируйте его, используя scp команда или редактирование с помощью nano:
nano /tmp/yourOutputFile.csv
CSV Экспорт унификации
Эта информация не очень хорошо представлена. Поскольку это второй раз, когда мне нужно было получить это, я помещу это здесь, чтобы напомнить себе, если ничего больше.
Действительно лучший способ сделать это (получить CSV из Postgres) является использование COPY ... TO STDOUT команда. Хотя вы не хотите делать это так, как показано в ответах здесь. Правильный способ использования команды:
COPY (select id, name from groups) TO STDOUT WITH CSV HEADER
Запомните только одну команду!
Это отлично подходит для использования поверх ssh:
$ ssh psqlserver.example.com 'psql -d mydb "COPY (select id, name from groups) TO STDOUT WITH CSV HEADER"' > groups.csv
Он отлично подходит для использования в докере по ssh:
$ ssh pgserver.example.com 'docker exec -tu postgres postgres psql -d mydb -c "COPY groups TO STDOUT WITH CSV HEADER"' > groups.csv
Это даже здорово на локальной машине:
$ psql -d mydb -c 'COPY groups TO STDOUT WITH CSV HEADER' > groups.csv
Или внутри докера на локальной машине?
docker exec -tu postgres postgres psql -d mydb -c 'COPY groups TO STDOUT WITH CSV HEADER' > groups.csv
Или в кластере kubernetes, в докере, через HTTPS??
kubectl exec -t postgres-2592991581-ws2td 'psql -d mydb -c "COPY groups TO STDOUT WITH CSV HEADER"' > groups.csv
Так универсально, много запятых!
Ты когда-нибудь?
Да, вот мои заметки:
КОПЫ
С помощью /copy эффективно выполняет файловые операции в любой системе psql команда запущена, как пользователь, который ее выполняет 1. Если вы подключаетесь к удаленному серверу, просто скопировать файлы данных в систему, выполнив psql с / на удаленный сервер.
COPY выполняет файловые операции на сервере в качестве учетной записи пользователя внутреннего процесса (по умолчанию postgres), пути к файлам и разрешения проверяются и применяются соответственно. При использовании TO STDOUT тогда проверки прав доступа к файлам обходятся.
Обе эти опции требуют последующего перемещения файла, если psql не выполняется в системе, где вы хотите, чтобы результирующий CSV в конечном итоге находился. По моему опыту, это наиболее вероятный случай, когда вы в основном работаете с удаленными серверами.
Сложнее настроить что-то вроде туннеля TCP/IP через ssh на удаленную систему для простого вывода CSV, но для других форматов вывода (двоичный) может быть лучше /copy через туннельное соединение, выполняя локальный psql, Аналогичным образом, для больших импортов, перемещение исходного файла на сервер и использование COPY это, пожалуй, самый высокопроизводительный вариант.
Параметры PSQL
С параметрами psql вы можете отформатировать вывод как CSV, но есть и недостатки, такие как необходимость помнить, чтобы отключить пейджер и не получать заголовки:
$ psql -P pager=off -d mydb -t -A -F',' -c 'select * from groups;'
2,Technician,Test 2,,,t,,0,,
3,Truck,1,2017-10-02,,t,,0,,
4,Truck,2,2017-10-02,,t,,0,,
Другие инструменты
Нет, я просто хочу вывести CSV из моего сервера без компиляции и / или установки инструмента.
Новая версия - PSQL 12 - будет поддерживать --csv,
--csv
Переключение в режим вывода CSV (значения, разделенные запятыми). Это эквивалентно формату \ pset csv.
csv_fieldsep
Определяет разделитель полей, который будет использоваться в выходном формате CSV. Если символ-разделитель появляется в значении поля, это поле выводится в двойных кавычках, следуя стандартным правилам CSV. По умолчанию используется запятая.
Использование:
psql -c "SELECT * FROM pg_catalog.pg_tables" --csv postgres
psql -c "SELECT * FROM pg_catalog.pg_tables" --csv -P csv_fieldsep='^' postgres
psql -c "SELECT * FROM pg_catalog.pg_tables" --csv postgres > output.csv
Если вас интересуют все столбцы определенной таблицы вместе с заголовками, вы можете использовать
COPY table TO '/some_destdir/mycsv.csv' WITH CSV HEADER;
Это немного проще, чем
COPY (SELECT * FROM table) TO '/some_destdir/mycsv.csv' WITH CSV HEADER;
которые, насколько мне известно, эквивалентны.
Мне пришлось использовать \COPY, потому что я получил сообщение об ошибке:
ERROR: could not open file "/filepath/places.csv" for writing: Permission denied
Поэтому я использовал:
\Copy (Select address, zip From manjadata) To '/filepath/places.csv' With CSV;
и это функционирует
Я работаю над AWS Redshift, который не поддерживает COPY TO особенность.
Мой инструмент BI поддерживает CSV с разделителями табуляции, поэтому я использовал следующее:
psql -h dblocation -p port -U user -d dbname -F $'\t' --no-align -c " SELECT * FROM TABLE" > outfile.csv
psql можем сделать это для вас:
edd@ron:~$ psql -d beancounter -t -A -F"," \
-c "select date, symbol, day_close " \
"from stockprices where symbol like 'I%' " \
"and date >= '2009-10-02'"
2009-10-02,IBM,119.02
2009-10-02,IEF,92.77
2009-10-02,IEV,37.05
2009-10-02,IJH,66.18
2009-10-02,IJR,50.33
2009-10-02,ILF,42.24
2009-10-02,INTC,18.97
2009-10-02,IP,21.39
edd@ron:~$
Увидеть man psql за помощь в опциях, используемых здесь.
В pgAdmin III есть возможность экспортировать в файл из окна запроса. В главном меню это Query -> Execute to file или есть кнопка, которая делает то же самое (это зеленый треугольник с синим гибким диском в отличие от простого зеленого треугольника, который просто выполняет запрос). Если вы не запускаете запрос из окна запроса, я бы сделал то, что предложил IMSoP, и использовал бы команду копирования.
Я написал небольшой инструмент под названием psql2csv который заключает в капсулу COPY query TO STDOUT шаблон, в результате чего правильный CSV. Это интерфейс похож на psql,
psql2csv [OPTIONS] < QUERY
psql2csv [OPTIONS] QUERY
Предполагается, что запрос представляет собой содержимое STDIN, если оно есть, или последний аргумент. Все остальные аргументы перенаправляются в psql, кроме следующих:
-h, --help show help, then exit
--encoding=ENCODING use a different encoding than UTF8 (Excel likes LATIN1)
--no-header do not output a header
Я попробовал несколько вещей, но немногие из них смогли дать мне желаемый CSV с подробностями заголовка.
Вот что сработало для меня.
psql -d dbame -U username \
-c "COPY ( SELECT * FROM TABLE ) TO STDOUT WITH CSV HEADER " > \
OUTPUT_CSV_FILE.csv
Начиная с Postgres 12, вы можете изменить формат вывода:
\pset format csv
Допускаются следующие форматы:
aligned, asciidoc, csv, html, latex, latex-longtable, troff-ms, unaligned, wrapped
Если вы хотите экспортировать результат запроса, вы можете использовать\o filenameособенность.
Пример :
\pset format csv
\o file.csv
SELECT * FROM table LIMIT 10;
\o
\pset format aligned
Если у вас более длинный запрос и вы хотите использовать psql, поместите ваш запрос в файл и используйте следующую команду:
psql -d my_db_name -t -A -F";" -f input-file.sql -o output-file.csv
Чтобы загрузить CSV-файл с именами столбцов в качестве HEADER, используйте следующую команду:
Copy (Select * From tableName) To '/tmp/fileName.csv' With CSV HEADER;
я нашел это
Чтобы исправить это, я разработал следующий скрипт:
# Define a connection to the Postgres database through environment variables
export PGHOST=your.pg.host
export PGPORT=5432
export PGDATABASE=your_pg_database
export PGUSER=your_pg_user
# Place credentials in $HOME/.pgpass with the format:
# ${PGHOST}:${PGPORT}:${PGUSER}:master:${PGPASSWORD}
# Populate long SQL query in a text file:
cat > /tmp/query.sql <<EOF
SELECT item.item_no,item_descrip,
invoice.invoice_no,invoice.sold_qty
FROM item
LEFT JOIN invoice
ON item.item_no=invoice.item_no;
EOF
# Generate CSV report with UTF8 BOM mark
printf '\xEF\xBB\xBF' > report.csv
psql -f /tmp/query.sql --csv | tee -a report.csv
Таким образом, я могу написать сценарий процесса создания CSV для автоматизации и кратко сохранить сценарий в одном исходном файле.
JackDB, клиент базы данных в вашем веб-браузере, делает это действительно легко. Особенно, если ты на Heroku.
Это позволяет вам подключаться к удаленным базам данных и выполнять SQL-запросы к ним.
Источник http://static.jackdb.com/assets/img/blog/jackdb-heroku-oauth-connect.gif
Как только ваша БД подключена, вы можете выполнить запрос и экспортировать в CSV или TXT (см. Справа внизу).

Примечание: я никоим образом не связан с JackDB. В настоящее время я пользуюсь их бесплатными услугами и считаю, что это отличный продукт.
Я очень рекомендую DataGrip, IDE для базы данных JetBrains. Вы можете сохранить SQL-запрос в CSV-файл и с легкостью настроить ssh-туннелирование.
Я не связан с DataGrip, я просто люблю продукт!
Если ваш запрос слишком длинный и вы не можете записать его в строку, вы можете использовать такую временную таблицу:
CREATE TABLE tmp_table as (
SELECT *
FROM my_table mt
WHERE ...
);
\COPY tmp_table TO '~/Desktop/tmp_table.csv' DELIMITER ';' CSV HEADER;
DROP TABLE tmp_table;
Если вы используете AWS, например AWS RDS, вы можете использовать PGAdmin. Я создаю временную таблицу с желаемым результатом:
CREATE TABLE export_descriptions AS SELECT description FROM products WHERE id = 406;
Затем в PGAdmin есть опция экспорта в CSV:
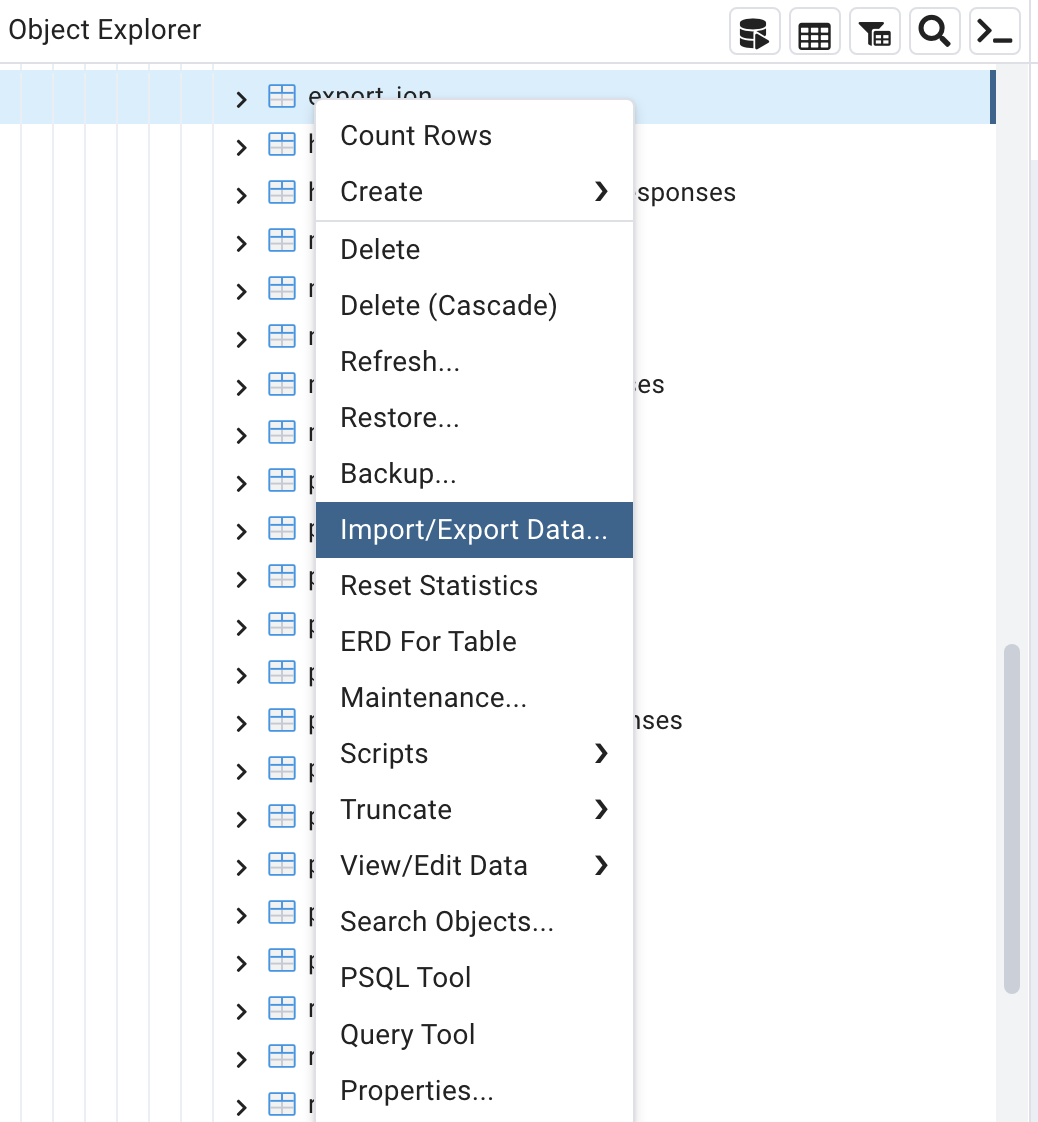
Там вы можете указать, куда его сохранить и в каком формате:
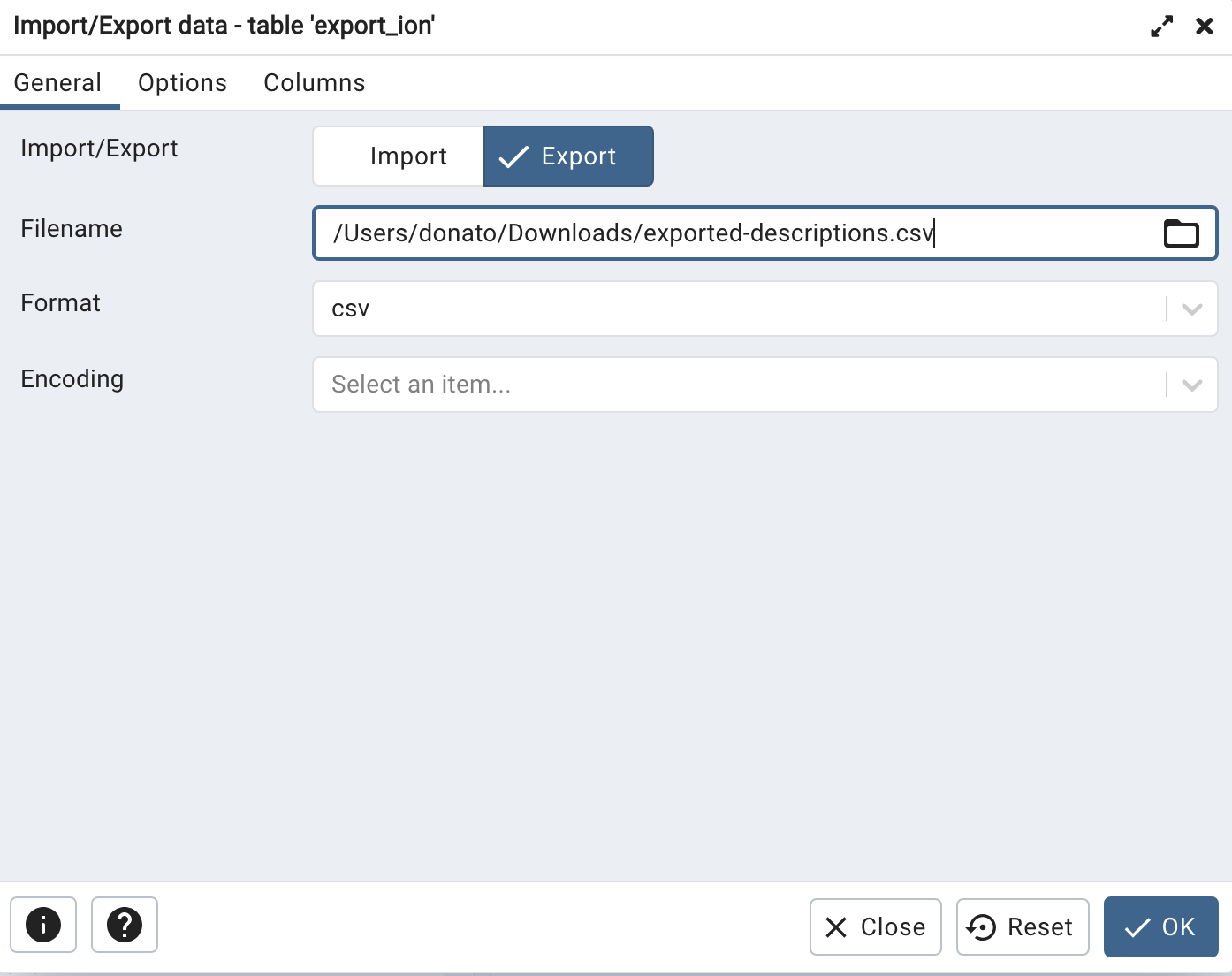
И затем он сохраняется прямо на ваш компьютер. Помните, что AWS RDS скрывает от вас базовые вычисления, на которых он работает, поэтому у вас нет доступа к базовому серверу (экземпляру EC2 или Fargate). Другими словами, вы не можете подключиться к нему по ssh. Однако вы можете получить доступ к командной строке postgres и подключиться к нему из PGAdmin, а новый интерфейс PGAdmin упрощает экспорт в CSV.
По запросу @skeller88 я репостю свой комментарий как ответ, чтобы его не потеряли люди, которые не читают каждый ответ...
Проблема с DataGrip в том, что он держит ваш кошелек под контролем. Это не бесплатно. Попробуйте версию DBeaver для сообщества на dbeaver.io. Это многоплатформенный инструмент базы данных FOSS для программистов SQL, администраторов баз данных и аналитиков, который поддерживает все популярные базы данных: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, MS Access, Teradata, Firebird, Hive, Presto и т. Д.
DBeaver Community Edition упрощает подключение к базе данных, выполнение запросов для извлечения данных, а затем загрузку набора результатов для сохранения в CSV, JSON, SQL или других распространенных форматах данных. Это жизнеспособный конкурент FOSS для TOAD для Postgres, TOAD для SQL Server или Toad для Oracle.
Я не имею отношения к DBeaver. Мне нравится цена и функциональность, но я бы хотел, чтобы они открывали приложение DBeaver/Eclipse больше и упрощали добавление виджетов аналитики в DBeaver / Eclipse, вместо того, чтобы требовать от пользователей оплаты годовой подписки для создания графиков и диаграмм непосредственно в приложение. Мои навыки программирования на Java заржавели, и мне не хочется тратить недели на повторное изучение того, как создавать виджеты Eclipse, только чтобы обнаружить, что DBeaver отключил возможность добавления сторонних виджетов в DBeaver Community Edition.
Есть ли у пользователей DBeaver представление о шагах по созданию виджетов аналитики для добавления в Community Edition DBeaver?
import json
cursor = conn.cursor()
qry = """ SELECT details FROM test_csvfile """
cursor.execute(qry)
rows = cursor.fetchall()
value = json.dumps(rows)
with open("/home/asha/Desktop/Income_output.json","w+") as f:
f.write(value)
print 'Saved to File Successfully'