Что такое алгоритм Hi/Lo?
Что такое алгоритм Hi/Lo?
Я нашел это в документации NHibernate (это один из способов генерирования уникальных ключей, раздел 5.1.4.2), но я не нашел хорошего объяснения того, как это работает.
Я знаю, что Nhibernate справляется с этим, и мне не нужно знать изнутри, но мне просто любопытно.
5 ответов
Основная идея заключается в том, что у вас есть два числа для составления первичного ключа - "высокое" число и "низкое" число. Клиент может в основном увеличивать последовательность "high", зная, что затем он может безопасно генерировать ключи из всего диапазона предыдущего "high" значения с помощью множества "low" значений.
Например, предположим, что у вас есть "высокая" последовательность с текущим значением 35, а "низкое" число находится в диапазоне 0-1023. Затем клиент может увеличить последовательность до 36 (чтобы другие клиенты могли генерировать ключи при использовании 35) и знать, что ключи 35/0, 35/1, 35/2, 35/3... 35/1023 все доступно.
Может быть очень полезно (особенно с ORM) иметь возможность устанавливать первичные ключи на стороне клиента, вместо того, чтобы вставлять значения без первичных ключей и затем возвращать их обратно на клиент. Помимо всего прочего, это означает, что вы можете легко установить родительские и дочерние отношения и иметь все ключи на месте, прежде чем делать какие-либо вставки, что упрощает их пакетирование.
В дополнение к ответу Джона:
Он используется, чтобы иметь возможность работать автономно. Затем клиент может запросить у сервера число hi и создать объекты, увеличивающие число lo. Нет необходимости связываться с сервером, пока не будет исчерпан диапазон lo.
Алгоритмы hi/lo разбивают область последовательностей на группы "hi". "Привет" значение назначается синхронно. Каждой группе "hi" дается максимальное количество записей "lo", которые могут быть назначены в автономном режиме, не беспокоясь о параллельных повторяющихся записях.
- Токен "hi" назначается базой данных, и два одновременных вызова гарантированно видят уникальные последовательные значения
- После получения токена "hi" нам нужен только "incrementSize" (количество записей "lo")
Диапазон идентификаторов задается следующей формулой:
[(hi -1) * incrementSize) + 1, (hi * incrementSize) + 1)и значение "lo" будет в диапазоне:
[0, incrementSize)применяется от начального значения:
[(hi -1) * incrementSize) + 1)Когда используются все значения "lo", выбирается новое значение "hi" и цикл продолжается
Вы можете найти более подробное объяснение в этой статье:
И за этой визуальной презентацией также легко следить:
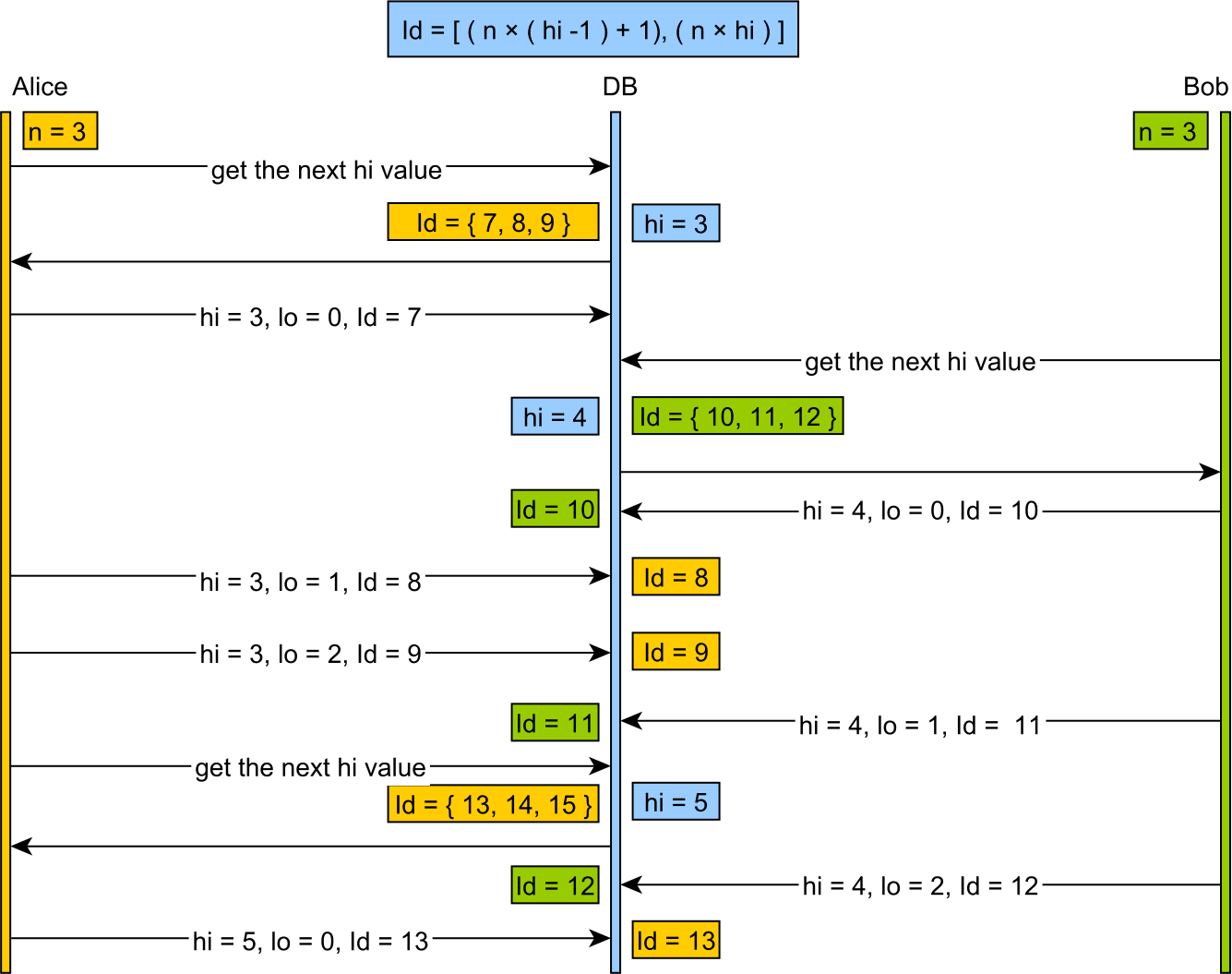
Хотя hi/lo оптимизатор хорош для оптимизации генерации идентификаторов, он не очень хорошо работает с другими системами, вставляющими строки в нашу базу данных, ничего не зная о нашей стратегии идентификаторов.
Hibernate предлагает оптимизатор pooled-lo, который сочетает в себе стратегию генератора hi/lo с механизмом распределения последовательностей взаимодействия. Этот оптимизатор эффективен и совместим с другими системами, являясь лучшим кандидатом, чем предыдущая стратегия идентификаторов hi/lo.
Лучше, чем распределитель Hi-Lo, является распределителем "Линейный блок". При этом используется аналогичный принцип, основанный на таблицах, но выделяются небольшие фрагменты удобного размера и генерируются приятные для человека значения.
create table KEY_ALLOC (
SEQ varchar(32) not null,
NEXT bigint not null,
primary key (SEQ)
);
Чтобы выделить следующие, скажем, 20 ключей (которые затем хранятся в качестве диапазона на сервере и используются по мере необходимости):
select NEXT from KEY_ALLOC where SEQ=?;
update KEY_ALLOC set NEXT=(old value+20) where SEQ=? and NEXT=(old value);
При условии, что вы можете совершить эту транзакцию (используйте повторные попытки для обработки конфликта), вы выделили 20 ключей и можете распределять их по мере необходимости.
При размере фрагмента всего 20 эта схема в 10 раз быстрее, чем выделение из последовательности Oracle, и на 100% переносима среди всех баз данных. Выделение производительности эквивалентно привет-ло.
В отличие от идеи Амблера, он рассматривает пространство клавиш как непрерывную линейную числовую линию.
Это позволяет избежать стимула для составных ключей (что никогда не было хорошей идеей) и позволяет не тратить целые слова при перезапуске сервера. Он генерирует "дружественные", ключевые человеческие ценности.
Идея г-на Амблера, для сравнения, выделяет старшие 16- или 32-битные значения и генерирует большие значения, недружелюбные к человеку, в качестве приращения высоких слов.
Сравнение выделенных ключей:
Linear_Chunk Hi_Lo
100 65536
101 65537
102 65538
.. server restart
120 131072
121 131073
122 131073
.. server restart
140 196608
Я фактически переписывался с мистером Амблером еще в 90-х, чтобы предложить ему эту улучшенную схему, но он был слишком застрял и упрям, чтобы признать преимущества и очевидную простоту использования линейной числовой линии.
Что касается дизайна, его решение существенно сложнее в отношении числовых линий (составные ключи, большие продукты hi_word), чем Linear_Chunk, но при этом не дает сравнительного преимущества. Его конструкция, таким образом, математически доказана несовершенной.
Я обнаружил, что алгоритм Hi/Lo идеально подходит для нескольких баз данных со сценариями репликации, основанными на моем опыте. Представь себе это. у вас есть сервер в Нью-Йорке (псевдоним 01) и другой сервер в Лос-Анджелесе (псевдоним 02), тогда у вас есть таблица PERSON... так что в Нью-Йорке, когда человек создает... вы всегда используете 01 в качестве значения HI и значение LO является следующей последовательной. Пример.
- 010000010 Джейсон
- 010000011 Дэвид
- 010000012 Тео
в Лос-Анджелесе вы всегда используете HI 02. например:
- 020000045 Руперт
- 020000046 Освальд
- 020000047 Марио
Таким образом, при использовании репликации базы данных (независимо от марки) все первичные ключи и данные легко и естественно объединяются, не беспокоясь о дублировании первичных ключей, коллизиях и т. Д.
Это лучший способ пойти по этому сценарию.