SQL - разделить поток данных запроса на 2 отдельные таблицы [Теоретическая оптимизация]
Я пишу некоторый код SQL для запуска в MapBasic (язык программирования MapInfo). Лучший способ описать вопрос с помощью примера:
Я хочу выделить все записи, в которых ShipType="Barge", в запрос с именем Barges и хочу, чтобы все оставшиеся записи были помещены в запрос OtherShips.
Я мог бы просто использовать следующие команды SQL:
select * from ShipsTable where ShipType = "Barge" into Barges
select * from ShipsTable where ShipType <> "Barge" into OtherShips
Это нормально, и все, но я не могу не чувствовать, что это неэффективно. Разве SQL не будет искать через базу данных дважды? Разве он не найдет строки данных, которые соответствуют второму запросу во время обработки первого?
Вместо этого было бы быстрее, если бы была такая команда:
select * from ShipsTable where ShipType = "Barge" into Barges ELSE into OtherShips
Мой вопрос, вы можете это сделать? Есть команда, которая соответствует этой спецификации?
Спасибо,
2 ответа
MapBasic действительно предоставляет вам доступ к "Invert Selection" MapInfo, который даст вам все, что не было выбрано из вашего первого запроса (при условии, что ваш первый запрос действительно возвращает результаты). Вы можете вызвать его, используя его идентификатор меню (находится в Menu.def), который равен 311, или, если вы включите menu.def вверху файла, вы можете ссылаться на него через константу M_QUERY_INVERTSELECT,
например.
Select * from ShipsTable where ShipType = "Barge" into Barges
Run Menu Command 311
или же Run Menu Command M_QUERY_INVERTSELECT если вы включили файл определений меню.
Я считаю, что это даст вам лучшую производительность, чем выполнение второго выбора в соответствии с вашим примером, но вы не сможете затем назвать таблицу результатов псевдонимом без выполнения другого выбора. Зависит от вашего варианта использования, стоит ли это использовать или нет, для большого запроса, который занимает много времени, он может сэкономить некоторое время на обработку.
Вы могли бы сделать это довольно легко в SSIS с условным разделением и двумя различными пунктами назначения.
Но не совсем в TSQL.
Однако для "развлечения" некоторые возможности рассматриваются ниже.
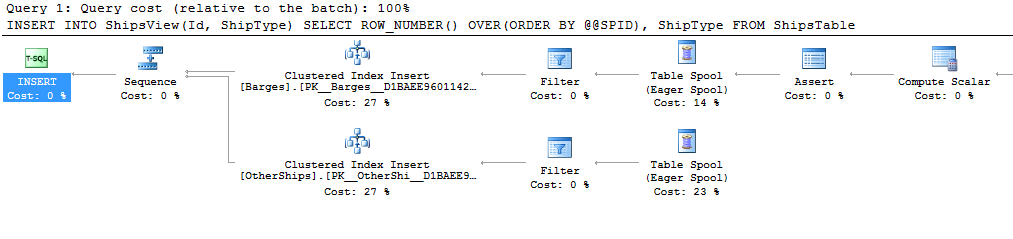
Вы можете создать секционированное представление, но требования, которые вам необходимо выполнить для этого, довольно трудны, и план выполнения просто загружает все это в спул, а затем в любом случае дважды читает спул с двумя разными фильтрами.
CREATE TABLE Barges
(
Id INT,
ShipType VARCHAR(50) NOT NULL CHECK (ShipType = 'Barge'),
PRIMARY KEY (Id, ShipType)
)
CREATE TABLE OtherShips
(
Id INT,
ShipType VARCHAR(50) NOT NULL CHECK (ShipType <> 'Barge'),
PRIMARY KEY (Id, ShipType)
)
CREATE TABLE ShipsTable
(
ShipType VARCHAR(50) NOT NULL
)
go
CREATE VIEW ShipsView
AS
SELECT *
FROM Barges
UNION ALL
SELECT *
FROM OtherShips
GO
INSERT INTO ShipsView(Id, ShipType)
SELECT ROW_NUMBER() OVER(ORDER BY @@SPID), ShipType
FROM ShipsTable
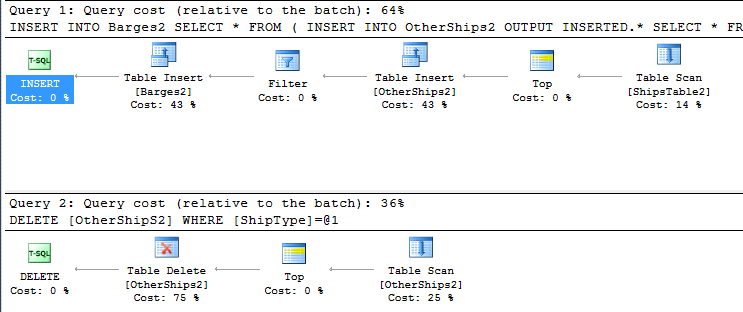
Или вы могли бы использовать OUTPUT и составляемый DML, но для этого потребуется вставить оба набора строк в первую таблицу, а затем удалить ненужные строки (вторая таблица будет получать только правильные строки и не будет нуждаться в очистке).
CREATE TABLE Barges2
(
ShipType VARCHAR(50) NOT NULL
)
CREATE TABLE OtherShips2
(
ShipType VARCHAR(50) NOT NULL
)
CREATE TABLE ShipsTable2
(
ShipType VARCHAR(50) NOT NULL
)
INSERT INTO Barges2
SELECT *
FROM
(
INSERT INTO OtherShips2
OUTPUT INSERTED.*
SELECT *
FROM ShipsTable2
) D
WHERE D.ShipType = 'Barge';
DELETE FROM OtherShips2 WHERE ShipType = 'Barge';