Производительность Floyd-Warshall в Haskell - Устранение космической утечки
Я хотел написать эффективную реализацию алгоритма Floyd-Warshall для всех пар по кратчайшему пути в Haskell, используя Vectorс надеждой получить хорошую производительность.
Реализация довольно проста, но вместо использования трехмерного |V|×|V|×|V| матрица, используется 2-мерный вектор, так как мы только когда-либо читали предыдущий k значение.
Таким образом, алгоритм на самом деле представляет собой просто последовательность шагов, в которые передается двумерный вектор и генерируется новый двумерный вектор. Конечный 2D-вектор содержит кратчайшие пути между всеми узлами (i,j).
Моя интуиция сказала мне, что было бы важно убедиться, что предыдущий 2D вектор был оценен перед каждым шагом, поэтому я использовал BangPatterns на prev аргумент fw функция и строгий foldl':
{-# Language BangPatterns #-}
import Control.DeepSeq
import Control.Monad (forM_)
import Data.List (foldl')
import qualified Data.Map.Strict as M
import Data.Vector (Vector, (!), (//))
import qualified Data.Vector as V
import qualified Data.Vector.Mutable as V hiding (length, replicate, take)
type Graph = Vector (M.Map Int Double)
type TwoDVector = Vector (Vector Double)
infinity :: Double
infinity = 1/0
-- calculate shortest path between all pairs in the given graph, if there are
-- negative cycles, return Nothing
allPairsShortestPaths :: Graph -> Int -> Maybe TwoDVector
allPairsShortestPaths g v =
let initial = fw g v V.empty 0
results = foldl' (fw g v) initial [1..v]
in if negCycle results
then Nothing
else Just results
where -- check for negative elements along the diagonal
negCycle a = any not $ map (\i -> a ! i ! i >= 0) [0..(V.length a-1)]
-- one step of the Floyd-Warshall algorithm
fw :: Graph -> Int -> TwoDVector -> Int -> TwoDVector
fw g v !prev k = V.create $ do -- ← bang
curr <- V.new v
forM_ [0..(v-1)] $ \i ->
V.write curr i $ V.create $ do
ivec <- V.new v
forM_ [0..(v-1)] $ \j -> do
let d = distance g prev i j k
V.write ivec j d
return ivec
return curr
distance :: Graph -> TwoDVector -> Int -> Int -> Int -> Double
distance g _ i j 0 -- base case; 0 if same vertex, edge weight if neighbours
| i == j = 0.0
| otherwise = M.findWithDefault infinity j (g ! i)
distance _ a i j k = let c1 = a ! i ! j
c2 = (a ! i ! (k-1))+(a ! (k-1) ! j)
in min c1 c2
Однако при запуске этой программы с графом из 1000 узлов с 47978 ребрами все выглядит не очень хорошо. Использование памяти очень велико, и выполнение программы занимает слишком много времени. Программа была составлена с ghc -O2,
Я перестроил программу для профилирования и ограничил количество итераций до 50:
results = foldl' (fw g v) initial [1..50]
Затем я запустил программу с +RTS -p -hc а также +RTS -p -hd:
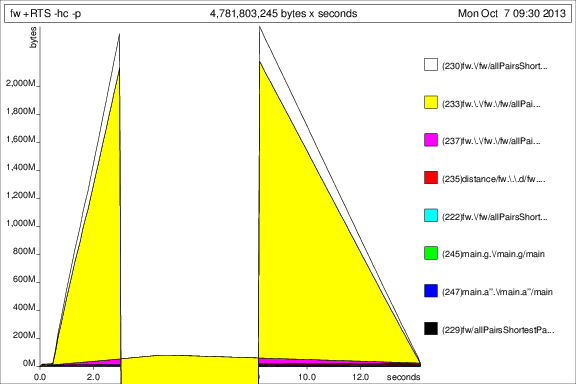
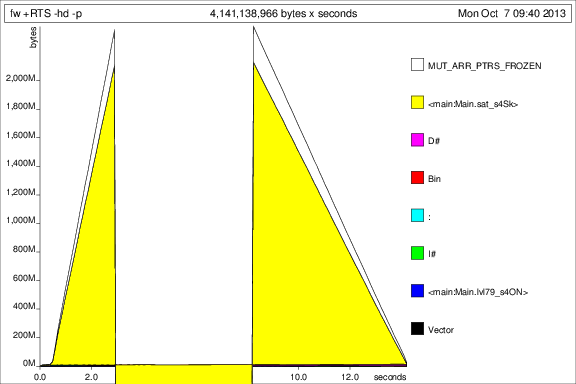
Это... интересно, но я думаю, это показывает, что он накапливает тонны громад. Нехорошо.
Итак, после нескольких снимков в темноте я добавил deepseq в fw Чтобы убедиться prev действительно оценивается:
let d = prev `deepseq` distance g prev i j k
Теперь все выглядит лучше, и я действительно могу запустить программу до конца с постоянным использованием памяти. Очевидно, что удар по prev аргумента было недостаточно.
Для сравнения с предыдущими графиками, вот использование памяти для 50 итераций после добавления deepseq:
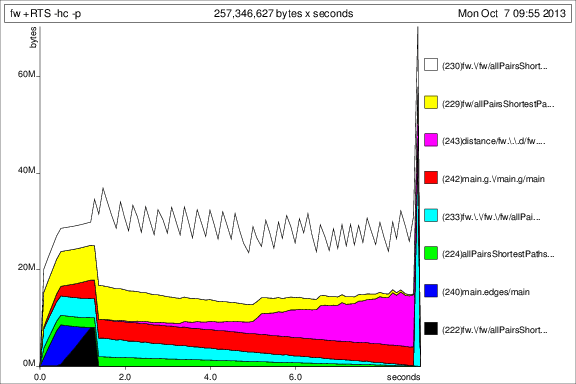
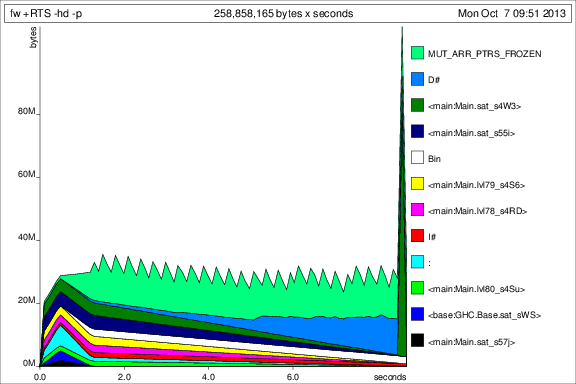
Хорошо, так что все лучше, но у меня все еще есть несколько вопросов:
- Это правильное решение для этой утечки пространства? Я ошибаюсь, чувствуя, что вставка
deepseqнемного некрасиво? - Является ли мое использование
Vectorздесь идиоматический / правильный? Я строю совершенно новый вектор для каждой итерации и надеюсь, что сборщик мусора удалит старыйVectors. - Есть ли что-то еще, что я мог бы сделать, чтобы это работало быстрее с таким подходом?
Для справки, вот graph.txt: http://sebsauvage.net/paste/?45147f7caf8c5f29
Вот main:
main = do
ls <- fmap lines $ readFile "graph.txt"
let numVerts = head . map read . words . head $ ls
let edges = map (map read . words) (tail ls)
let g = V.create $ do
g' <- V.new numVerts
forM_ [0..(numVerts-1)] (\idx -> V.write g' idx M.empty)
forM_ edges $ \[f,t,w] -> do
-- subtract one from vertex IDs so we can index directly
curr <- V.read g' (f-1)
V.write g' (f-1) $ M.insert (t-1) (fromIntegral w) curr
return g'
let a = allPairsShortestPaths g numVerts
case a of
Nothing -> putStrLn "Negative cycle detected."
Just a' -> do
putStrLn $ "The shortest, shortest path has length "
++ show ((V.minimum . V.map V.minimum) a')
1 ответ
Сначала немного общей очистки кода:
В вашем fw функция, вы явно выделяете и заполняете изменяемые векторы. Однако для этой конкретной цели есть готовая функция, а именно generate, fw поэтому может быть переписан как
V.generate v (\i -> V.generate v (\j -> distance g prev i j k))
Аналогично, код генерации графа можно заменить на replicate а также accum:
let parsedEdges = map (\[f,t,w] -> (f - 1, (t - 1, fromIntegral w))) edges
let g = V.accum (flip (uncurry M.insert)) (V.replicate numVerts M.empty) parsedEdges
Обратите внимание, что это полностью устраняет необходимость мутации без потери производительности.
Теперь к актуальным вопросам:
По моему опыту,
deepseqЭто очень полезно, но только для быстрого устранения утечек, подобных этой. Основная проблема не в том, что вам нужно форсировать результаты после того, как вы их произвели. Вместо этого использованиеdeepseqподразумевает, что вы должны были строить структуру более строго в первую очередь. На самом деле, если вы добавите шаблон взрыва в код для создания вектора следующим образом:let !d = distance g prev i j kТогда проблема устранена без
deepseq, Обратите внимание, что это не работает сgenerateкод, потому что по какой-то причине (я мог бы создать запрос функции для этого),vectorне предоставляет строгих функций для штучных векторов. Однако, когда я отвечаю на вопрос 3, который является строгим, я получаю распакованные векторы, оба подхода работают без аннотаций строгости.Насколько я знаю, схема многократного генерирования новых векторов идиоматична. Единственное, что не является идиоматическим, - это использование изменчивости - за исключением случаев, когда они строго необходимы, изменяемые векторы обычно не рекомендуется.
Есть несколько вещей, которые нужно сделать:
Проще всего, вы можете заменить
Map IntсIntMap, Поскольку это не очень медленная точка функции, это не имеет большого значения, ноIntMapможет быть намного быстрее для тяжелых рабочих нагрузок.Вы можете переключиться на использование незарегистрированных векторов. Хотя внешний вектор должен оставаться в штучной упаковке, поскольку векторы векторов не могут быть распакованы, внутренний вектор может быть. Это также решает вашу проблему строгости - поскольку неупакованные векторы являются строгими по своим элементам, вы не получите утечку пространства. Обратите внимание, что на моей машине это улучшает производительность с 4,1 до 1,3 секунд, поэтому распаковка очень полезна.
Вы можете объединить вектор в один и использовать умножение и деление для переключения между двумерными и одномерными знаками. Я не рекомендую этого, так как это немного сложно, довольно уродливо и из-за разделения фактически замедляет код на моей машине.
Ты можешь использовать
repa, Это имеет огромное преимущество автоматического распараллеливания вашего кода. Обратите внимание, что, так какrepaвыравнивает свои массивы и, по-видимому, не избавляет должным образом от делений, необходимых для хорошего заполнения (это можно сделать с помощью вложенных циклов, но я думаю, что он использует один цикл и деление), у него такое же снижение производительности, как я упоминал выше, увеличив время выполнения с 1,3 до 1,8. Однако, если вы включите параллелизм и используете многоядерный компьютер, вы начнете видеть некоторые преимущества. К сожалению, ваш текущий тестовый набор слишком мал, чтобы увидеть много пользы, поэтому на моем 6-ядерном компьютере я вижу его снижение до 1,2 секунды. Если я вернусь к размеру[1..v]вместо[1..50]Параллелизм увеличивает его с 32 до 13 секунд. Предположительно, если вы дадите этой программе больший ввод, вы можете увидеть больше преимуществ.Если вы заинтересованы, я разместил свой
repaверсия здесь.РЕДАКТИРОВАТЬ: использовать
-fllvm, Тестирование на моем компьютере, используяrepaЯ получаю 14,7 секунды без параллелизма, что почти так же хорошо, как и без-fllvmи с параллелизмом. В общем, LLVM может очень хорошо обрабатывать код на основе массива.