Как я могу автоматически настроить метки на графике рассеяния, чтобы они не перекрывались с другими метками в python?
Так что я немного поработал над этим и просто хотел посмотреть, сможет ли кто-нибудь взглянуть на то, почему я могу автоматически настраивать метки графика рассеяния. Когда я искал решение, я наткнулся на библиотеку AdjustText, найденную здесь https://github.com/Phlya/adjustText и похоже, что она должна работать, но я просто пытаюсь найти пример, который строит графики из кадра данных. Когда я попытался воспроизвести примеры AdjustText, он выдает ошибку. Это мой текущий код.
df["category"] = df["category"].astype(int)
df2 = df.sort_values(by=['count'], ascending=False).head()
ax = df.plot.scatter(x="category", y="count")
a = df2['category']
b = df2['count']
texts = []
for xy in zip(a, b):
texts.append(plt.text(xy))
adjust_text(texts, arrowprops=dict(arrowstyle="->", color='r', lw=0.5))
plt.title("Count of {column} in {table}".format(**sql_dict))
Но потом я получил этот TypeError: TypeError: text(), пропустив 2 обязательных позиционных аргумента: 'y' и 's' Это то, из чего я пытался преобразовать его для поворота координат, он работает, но координаты просто перекрываются.
df["category"] = df["category"].astype(int)
df2 = df.sort_values(by=['count'], ascending=False).head()
ax = df.plot.scatter(x="category", y="count")
a = df2['category']
b = df2['count']
for xy in zip(a, b):
ax.annotate('(%s, %s)' % xy, xy=xy)
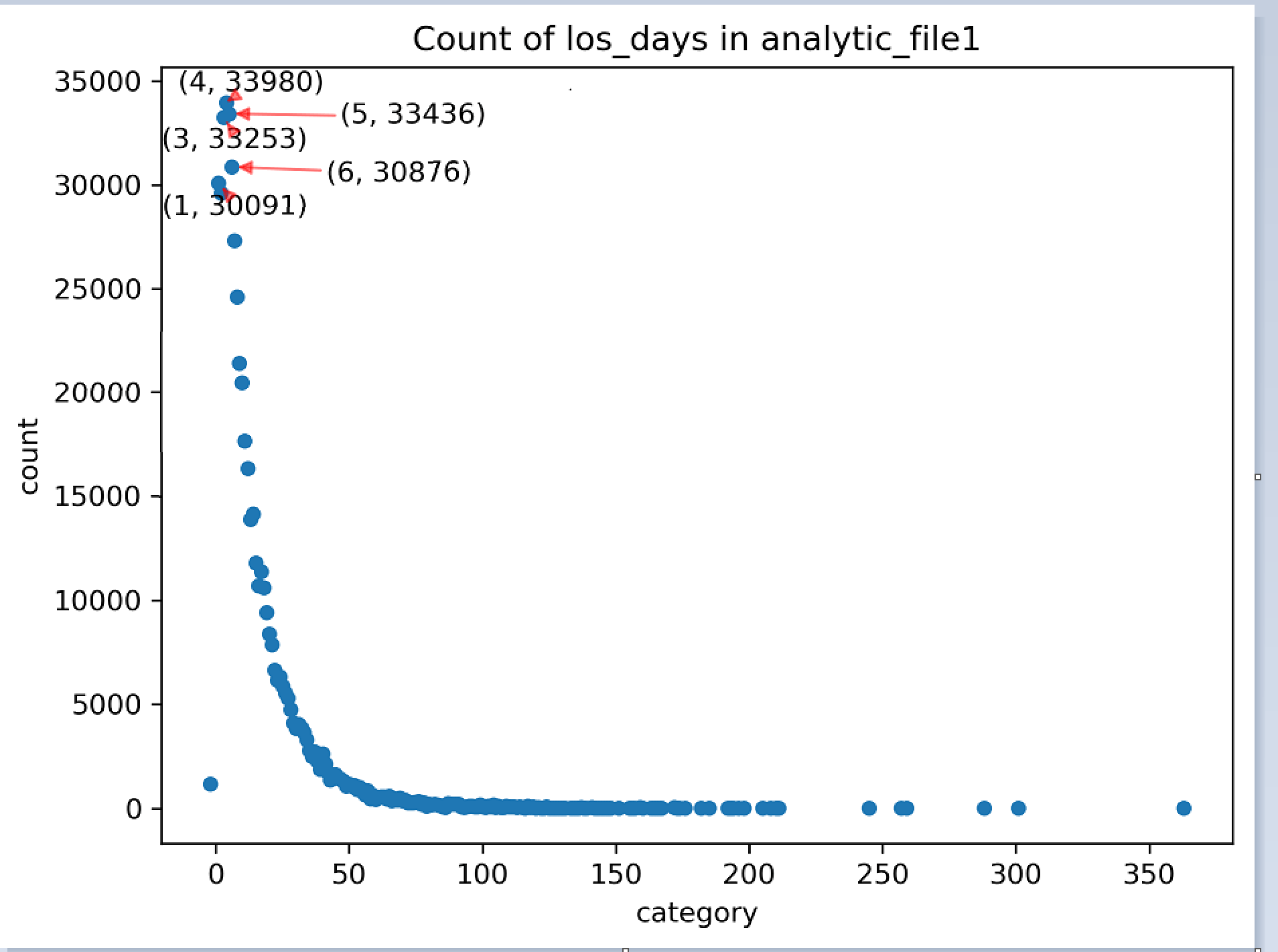
Как вы можете видеть здесь, я создаю свой df из таблиц в sql и предоставлю вам, как эта конкретная таблица должна выглядеть здесь. В этой конкретной таблице это продолжительность пребывания в днях по сравнению с тем, сколько людей оставалось так долго. Так как образец данных может выглядеть так. Я сделал второй кадр данных выше, чтобы пометить только самые высокие значения на графике. Это один из моих первых опытов с графической визуализацией в python, поэтому любая помощь будет принята с благодарностью.
[![picture of a graph of overlapping items][1]][1]
 [los_days count]
3 350
1 4000
15 34
[los_days count]
3 350
1 4000
15 34
и так далее. Спасибо. Позвольте мне знать, если вам нужно что-нибудь еще.
Вот пример дф
category count
0 2 29603
1 4 33980
2 9 21387
3 11 17661
4 18 10618
5 20 8395
6 27 5293
7 29 4121
1 ответ
После некоторого реверс-инжиниринга с примером из библиотеки AdjustText и моим собственным примером мне просто пришлось изменить цикл for для создания меток, и он работал фантастически.
labels = ['{}'.format(i) for i in zip(a, b)]
texts = []
for x, y, text in zip(a, b, labels):
texts.append(ax.text(x, y, text))
adjust_text(texts, force_text=0.05, arrowprops=dict(arrowstyle="-|>",
color='r', alpha=0.5))