Добавьте параметры набора данных в столбец, чтобы позже использовать их в BigQuery с DataPrep
Я импортирую несколько файлов из Google Cloud Storage (GCS) через Google DataPrep и сохраняю результаты в таблицах Google BigQuery. Структура в GCS выглядит примерно так:
//source/user/me/datasets/{month}/2017-01-31-file.csv
//source/user/me/datasets/{month}/2017-02-28-file.csv
//source/user/me/datasets/{month}/2017-03-31-file.csv
Мы можем создать набор данных с параметрами, описанными на этой странице. Это все работает нормально, и я смог импортировать его правильно.
Однако в этой таблице BigQuery (выходной) у меня нет средств для извлечения только строк, например, с параметром month в этом.
Как я могу поэтому добавить эти параметры набора данных (здесь: {month}) в мою таблицу BigQuery, используя DataPrep?
1 ответ
В настоящее время нет доступа к расположению источника данных или значениям соответствия параметров в потоке. Вам доступны только данные в наборе данных. (Кроме SOURCEROWNUMBER())
Частичное решение
Один метод, который я использовал, чтобы имитировать вставку параметров в конечную таблицу, состоит в том, чтобы иметь несколько импортов наборов данных по параметрам и затем объединять их перед запуском преобразований в финальную таблицу.
Для каждого известного набора данных поиска параметров есть рецепт, который заполняет столбец этим параметром для каждого набора данных, а затем объединяет результаты каждого из них.
Очевидно, что это настолько масштабируемо, то есть работает, если вы знаете набор значений параметров, которые будут совпадать. как только вы доберетесь до степени детализации отметки времени в исходном файле, это не будет возможно.
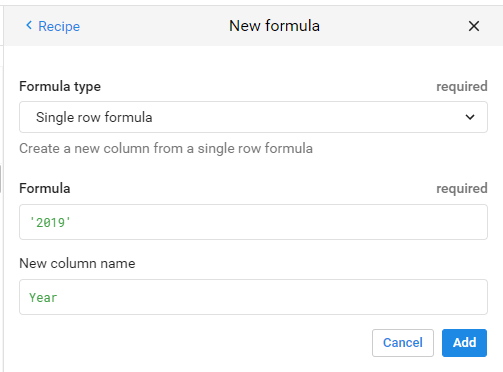 В этом примере только значение года является отфильтрованным параметром.
В этом примере только значение года является отфильтрованным параметром.
Более долгое решение (в стороне)
Альтернативой этому я, в конечном итоге, стал кататься, чтобы определить задания потока данных с использованием Dataprep, использовать их в качестве шаблонов потока данных, а затем запустить функцию оркестрации, которая выполняла задание потока данных (не dataprep) и изменила параметры для ввода И вывода через API. Затем была трансформация BigQuery Job, которая выполняла функцию добавления округления.
Это того стоит, если поток довольно устоявшийся, но не для adhoc; все зависит от вашего масштаба.
Хотя первоначальные ответы были верны на момент публикации, на прошлой неделе было выпущено обновление, в которое добавлен ряд функций, которые не были специально рассмотрены в примечаниях к выпуску, включая еще одно решение этого вопроса.
В дополнение к SOURCEROWNUMBER() (который теперь также может быть выражен как $sourcerownumber), теперь есть также ссылка на метаданные источника, называемая $filepath- который, как и следовало ожидать, хранит локальный путь к файлу в облачном хранилище.
Здесь есть ряд предостережений, например, он не возвращает значение для источников BigQuery и не доступен, если вы pivot, join, или же unnest,,, но в вашем сценарии вы можете легко перенести его в столбец и выполнить любое необходимое сопоставление или удаление, используя его.
ПРИМЕЧАНИЕ. Если образец источника данных был создан до этой функции, вам нужно создать новый образец, чтобы увидеть его в интерфейсе (а не только значения NULL).
Полные примечания для этих полей метаданных доступны здесь: https://cloud.google.com/dataprep/docs/html/Source-Metadata-References_136155148