SELECT [все столбцы] занимает 1:02 для таблицы с 163 020 строками
Это база данных SQL Azure. Это маленький столик, правда. Я не делаю SELECT * FROM. Я называю все столбцы в таблице.
Таблица имеет PK с кластерным индексом. Он также имеет некластеризованный индекс с двумя столбцами.
Первоначально инструкция SELECT выполнялась за 39 секунд. Но после того, как я сделал REORGANIZE для обоих индексов, теперь это занимает 1:02. Итак, я сделал все намного хуже. (К счастью, это таблица DEV.)
Как я могу по крайней мере вернуться к 39 секундам, с которых я начал? И что еще я должен искать, чтобы объяснить медлительность?
Если это поможет, вот план выполнения.
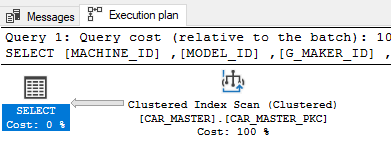
Я также запустил SQL Profiler и запустил трассировку, но она вернула столько данных, и, честно говоря, я не знаю, что я ищу в результатах.
Вот результат SELECT @@Version
Microsoft SQL Azure (окончательная первоначальная версия) - 12.0.2000.8
3 января 2019 00:14:33
Авторское право (C) 2018 Microsoft Corporation
2 ответа
Возможно перестроить индекс? Создание индекса покрытия, содержащего все выбранные столбцы, позволит выполнить запрос мгновенно. Кроме того, есть ли в каких-то столбцах очень большие капли? Я бы также посмотрел на производительность дискового ввода-вывода. Это кажется необычайно медленным.
Что касается комментария BoCoKeith, я думаю, что задержка в сети, кажется, проблема. Это пятнистый и не соответствует. Но этот запрос будет последовательно выполняться в 00:00 секунд:
SELECT * INTO #sometemptable FROM MyTable
Хотя это занимает от 00:20 до 01:40
SELECT * FROM MyTable