Что именно является точкой зрения на память в Python
Проверка документации на память:
объекты memoryview позволяют коду Python получать доступ к внутренним данным объекта, который поддерживает буферный протокол, без копирования.
класс памяти(объект)
Создайте представление памяти, которое ссылается на объект. obj должен поддерживать протокол буфера. Встроенные объекты, которые поддерживают буферный протокол, включают байты и байтовый массив.
Затем нам дается пример кода:
>>> v = memoryview(b'abcefg')
>>> v[1]
98
>>> v[-1]
103
>>> v[1:4]
<memory at 0x7f3ddc9f4350>
>>> bytes(v[1:4])
b'bce'
Цитата закончена, теперь давайте рассмотрим подробнее:
>>> b = b'long bytes stream'
>>> b.startswith(b'long')
True
>>> v = memoryview(b)
>>> vsub = v[5:]
>>> vsub.startswith(b'bytes')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'memoryview' object has no attribute 'startswith'
>>> bytes(vsub).startswith(b'bytes')
True
>>>
Итак, что я собираю из вышесказанного:
Мы создаем объект memoryview для предоставления внутренних данных объекта буфера без копирования, однако, чтобы сделать что-нибудь полезное с объектом (вызывая методы, предоставляемые объектом), мы должны создать копию!
Обычно представление памяти (или старый буферный объект) понадобится, когда у нас большой объект, а срезы тоже могут быть большими. Потребность в большей эффективности возникнет, если мы будем делать большие кусочки или делать маленькие кусочки, но большое количество раз.
С вышеупомянутой схемой я не вижу, как это может быть полезно для любой ситуации, если кто-то не может объяснить мне, что мне здесь не хватает.
Edit1:
У нас есть большой кусок данных, мы хотим обработать его, продвигаясь по нему от начала до конца, например извлекая токены из начала строкового буфера до тех пор, пока буфер не будет использован. В терминах C это продвигает указатель через буфер, и указатель может быть передан любой функции, ожидающей тип буфера. Как можно сделать что-то подобное в python?
Люди предлагают обходные пути, например, многие строковые и регулярные выражения принимают аргументы позиции, которые можно использовать для эмуляции продвижения указателя. С этим есть две проблемы: во-первых, это обходной путь, вы вынуждены изменить свой стиль кодирования, чтобы преодолеть недостатки, и, во-вторых, не все функции имеют аргументы позиции, например, функции регулярного выражения и startswith делать, encode()/decode() нет.
Другие могут предложить загружать данные кусками или обрабатывать буфер небольшими сегментами, превышающими максимальный токен. Итак, мы знаем об этих возможных обходных путях, но мы должны работать более естественным образом в Python, не пытаясь изменить стиль кодирования, чтобы соответствовать языку - не так ли?
Edit2:
Пример кода прояснит ситуацию. Это то, что я хочу сделать, и то, что я предположил, просмотр памяти позволил бы мне сделать на первый взгляд. Давайте используем pmview (правильный просмотр памяти) для функциональности, которую я ищу:
tokens = []
xlarge_str = get_string()
xlarge_str_view = pmview(xlarge_str)
while True:
token = get_token(xlarge_str_view)
if token:
xlarge_str_view = xlarge_str_view.vslice(len(token))
# vslice: view slice: default stop paramter at end of buffer
tokens.append(token)
else:
break
7 ответов
Одна причина memoryviews полезны, потому что они могут быть разрезаны без копирования основных данных, в отличие от bytes/str,
Например, возьмите следующий игрушечный пример.
import time
for n in (100000, 200000, 300000, 400000):
data = 'x'*n
start = time.time()
b = data
while b:
b = b[1:]
print 'bytes', n, time.time()-start
for n in (100000, 200000, 300000, 400000):
data = 'x'*n
start = time.time()
b = memoryview(data)
while b:
b = b[1:]
print 'memoryview', n, time.time()-start
На моем компьютере я получаю
bytes 100000 0.200068950653
bytes 200000 0.938908100128
bytes 300000 2.30898690224
bytes 400000 4.27718806267
memoryview 100000 0.0100269317627
memoryview 200000 0.0208270549774
memoryview 300000 0.0303030014038
memoryview 400000 0.0403470993042
Вы можете ясно видеть квадратичную сложность повторяющегося среза строки. Даже с 400000 итерациями это уже невозможно. Между тем версия с обзором памяти имеет линейную сложность и молниеносна.
Изменить: Обратите внимание, что это было сделано в CPython. В Pypy до 4.0.1 была ошибка, из-за которой представления памяти имели квадратичную производительность.
memoryview объекты хороши, когда вам нужны подмножества двоичных данных, которые должны поддерживать только индексацию. Вместо того, чтобы брать кусочки (и создавать новые, потенциально большие) объекты для передачи в другой API, вы можете просто взять memoryview объект.
Одним из таких примеров API будет struct модуль. Вместо того, чтобы передать кусочек большого bytes объект для анализа упакованных значений C, вы передаете в memoryview только региона, из которого нужно извлечь значения.
memoryview объекты, по сути, поддерживают struct родная распаковка; Вы можете выбрать целевой регион bytes объект с ломтиком, затем используйте .cast() интерпретировать нижележащие байты как длинные целые числа, или значения с плавающей запятой, или n-мерные списки целых чисел. Это обеспечивает очень эффективную интерпретацию двоичного формата файла без необходимости создавать больше копий байтов.
Позвольте мне прояснить, в чем здесь проблема в понимании.
Спрашивающий, как и я, ожидал, что сможет создать представление памяти, которое выбирает фрагмент существующего массива (например, байты или байтовый массив). Поэтому мы ожидали что-то вроде:
desired_slice_view = memoryview(existing_array, start_index, end_index)
Увы, такого конструктора не существует, и в документах не указано, что делать вместо этого.
Ключ заключается в том, что вы должны сначала сделать просмотр памяти, который покрывает весь существующий массив. Из этого обзора памяти вы можете создать второй просмотр памяти, который покрывает фрагмент существующего массива, например:
whole_view = memoryview(existing_array)
desired_slice_view = whole_view[10:20]
Короче говоря, цель первой строки - просто предоставить объект, реализация слайса которого (dunder-getitem) возвращает представление памяти.
Это может показаться неопрятным, но это можно объяснить несколькими способами:
Наш желаемый результат - это просмотр памяти, который является частью чего-то. Обычно мы получаем нарезанный объект от объекта того же типа, используя оператор слайса [10:20]. Таким образом, есть некоторые основания ожидать, что нам нужно получить требуемый_изображение_в просмотре из памяти и, следовательно, первый шаг - получить представление о памяти всего базового массива.
Наивное ожидание конструктора вида памяти с аргументами start и end не учитывает, что спецификации слайса действительно нужна вся выразительность обычного оператора слайса (включая такие вещи, как [3::2] или [:-4] и т. Д.). Невозможно просто использовать существующий (и понятный) оператор в этом однострочном конструкторе. Вы не можете присоединить его к аргументу Существующий_аррэй, так как это сделает срез этого массива вместо того, чтобы сообщать конструктору памяти некоторые параметры среза. И вы не можете использовать сам оператор в качестве аргумента, потому что это оператор, а не значение или объект.
Возможно, конструктор вида памяти мог бы взять объект слайса:
desired_slice_view = memoryview(existing_array, slice(1, 5, 2) )
... но это не очень удовлетворительно, так как пользователи должны были бы узнать об объекте среза и о том, что означают параметры его конструктора, когда они уже думают с точки зрения записи оператора среза.
Вот код Python3.
#!/usr/bin/env python3
import time
for n in (100000, 200000, 300000, 400000):
data = 'x'*n
start = time.time()
b = data
while b:
b = b[1:]
print ('bytes {:d} {:f}'.format(n,time.time()-start))
for n in (100000, 200000, 300000, 400000):
data = b'x'*n
start = time.time()
b = memoryview(data)
while b:
b = b[1:]
print ('memview {:d} {:f}'.format(n,time.time()-start))
Отличный пример сурьмы. На самом деле, в Python3 вы можете заменить data = 'x'*n на data = bytes(n) и поставить круглые скобки в операторы вывода, как показано ниже:
import time
for n in (100000, 200000, 300000, 400000):
#data = 'x'*n
data = bytes(n)
start = time.time()
b = data
while b:
b = b[1:]
print('bytes', n, time.time()-start)
for n in (100000, 200000, 300000, 400000):
#data = 'x'*n
data = bytes(n)
start = time.time()
b = memoryview(data)
while b:
b = b[1:]
print('memoryview', n, time.time()-start)
Следующий код может объяснить это лучше. Предположим, у вас нет никакого контроля над тем, какforeign_funcреализуется. Вы можете либо вызвать его с помощьюbytesнапрямую или с помощьюmemoryviewиз этих байтов:
from pandas import DataFrame
from timeit import timeit
def foreign_func(data):
def _foreign_func(data):
# Did you know that memview slice can be compared to bytes directly?
assert data[:3] == b'xxx'
_foreign_func(data[3:-3])
# timeit
bytes_times = []
memoryview_times = []
data_lens = []
for n in range(1, 10):
data = b'x' * 10 ** n
data_lens.append(len(data))
bytes_times.append(timeit(
'foreign_func(data)', globals=globals(), number=10))
memoryview_times.append(timeit(
'foreign_func(memoryview(data))', globals=globals(), number=10))
# output
df = DataFrame({
'data_len': data_lens,
'memoryview_time': memoryview_times,
'bytes_time': bytes_times
})
df['times_faster'] = df['bytes_time'] / df['memoryview_time']
print(df)
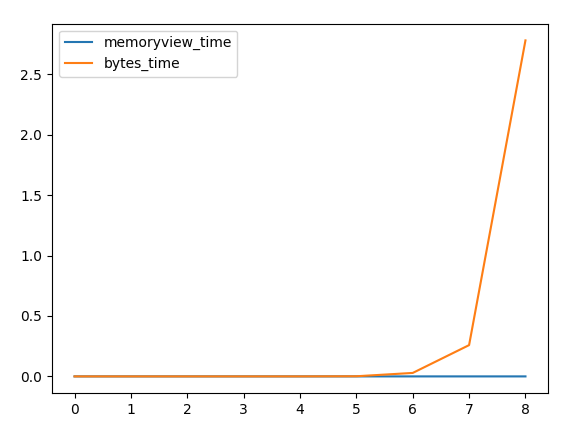
df[['memoryview_time', 'bytes_time']].plot()
Результат:
data_len memoryview_time bytes_time times_faster
0 10 0.000019 0.000012 0.672033
1 100 0.000016 0.000011 0.690320
2 1000 0.000016 0.000013 0.833314
3 10000 0.000016 0.000037 2.387100
4 100000 0.000016 0.000086 5.300594
5 1000000 0.000018 0.001134 63.357466
6 10000000 0.000009 0.028672 3221.528855
7 100000000 0.000009 0.258822 28758.547214
8 1000000000 0.000009 2.779704 292601.789177
Кстати, спасибо за это, memoryview - это как раз то, что мне нужно.
#!/usr/bin/env python3
import time
for stuff in [bytes, bytearray, memoryview, str ]:
for n in (100000, 200000, 300000, 400000):
start = time.time()
data = b'x'*n
b = stuff(data)
while b:
b=b[1:]
print(f'{str(stuff)} : {n} in {time.time()-start}')