Как суммировать отдельные значения, объединяющие другие значения
У меня есть эта таблица:
Family_ID Person_ID Weight Spent_amount category
A 1 10 500 flight
A 2 10 500 flight
A 1 10 200 Hotel
A 2 10 200 Hotel
B 3 20 250 flight
B 3 20 300 Hotel
как мы видим здесь, в каждой семье есть член, а расходы на категорию рассчитаны для семьи, а не для человека. И, как мы видим, не каждая семья равна другой, но имеет вес, поэтому каждую потраченную сумму следует умножить на вес семьи. Теперь моя цель - написать меру расходов на каждую семью
Я написал уравнение, но я вижу его очень сложным, и я думаю, что оно дает неправильное значение. Уравнение Дакса, которое я написал,
cash_wieght:=SUMX (
SUMMARIZE (
s2g516_full,
s2g516_full[DIM_HOUSEHOLD_REF_ID],
"cash", CALCULATE ( MAXX ( SUMMARIZE (
s2g516_full,
s2g516_full[Persons],
s2g516_full[DIM_HOUSEHOLD_REF_ID] ,"cash1", CALCULATE ( Sum(s2g516_full[SPENT_PER_REASON])*MAX ( s2g516_full[Weight] ) )
/distinctcount(s2g516_full[person]) ),[Cash1] ) )
),
[cash]
)
Когда я взял образец, отфильтровав его по family_ID, он дал мне правильные цифры для тестов образцов, но, возможно, их нет. Так как я могу узнать, получил ли я правильные результаты или нет?
В результате я хочу это weight * spent_amount суммироваться и фильтроваться с помощью family_ID, как будто person_ID отсутствует в таблице, например: "если я отфильтровал по Family_ID"
A 700*10
B 550 *20
1 ответ
Во-первых, DAX Formatter - твой друг.
cash_wieght :=
SUMX (
SUMMARIZE (
s2g516_full,
s2g516_full[DIM_HOUSEHOLD_REF_ID],
"cash", CALCULATE (
MAXX (
SUMMARIZE (
s2g516_full,
s2g516_full[Persons],
s2g516_full[DIM_HOUSEHOLD_REF_ID],
"cash1", CALCULATE (
SUM ( s2g516_full[SPENT_PER_REASON] ) * MAX ( s2g516_full[Weight] )
)
/ DISTINCTCOUNT ( s2g516_full[person] )
),
[Cash1]
)
)
),
[cash]
)
После этого, я думаю, у вас есть правильная интуиция с SUMMARIZE(), но это может быть намного проще, чем то, что вы делаете. SUMMARIZE() группирует по полям таблицы, которую вы ей передаете. Поскольку члены с одинаковым [Family_ID] имеют одинаковые значения для [Spent_Amount] в данном [Category], все, что нам нужно сделать, это сгруппировать все из таблицы, кроме [Person_ID].
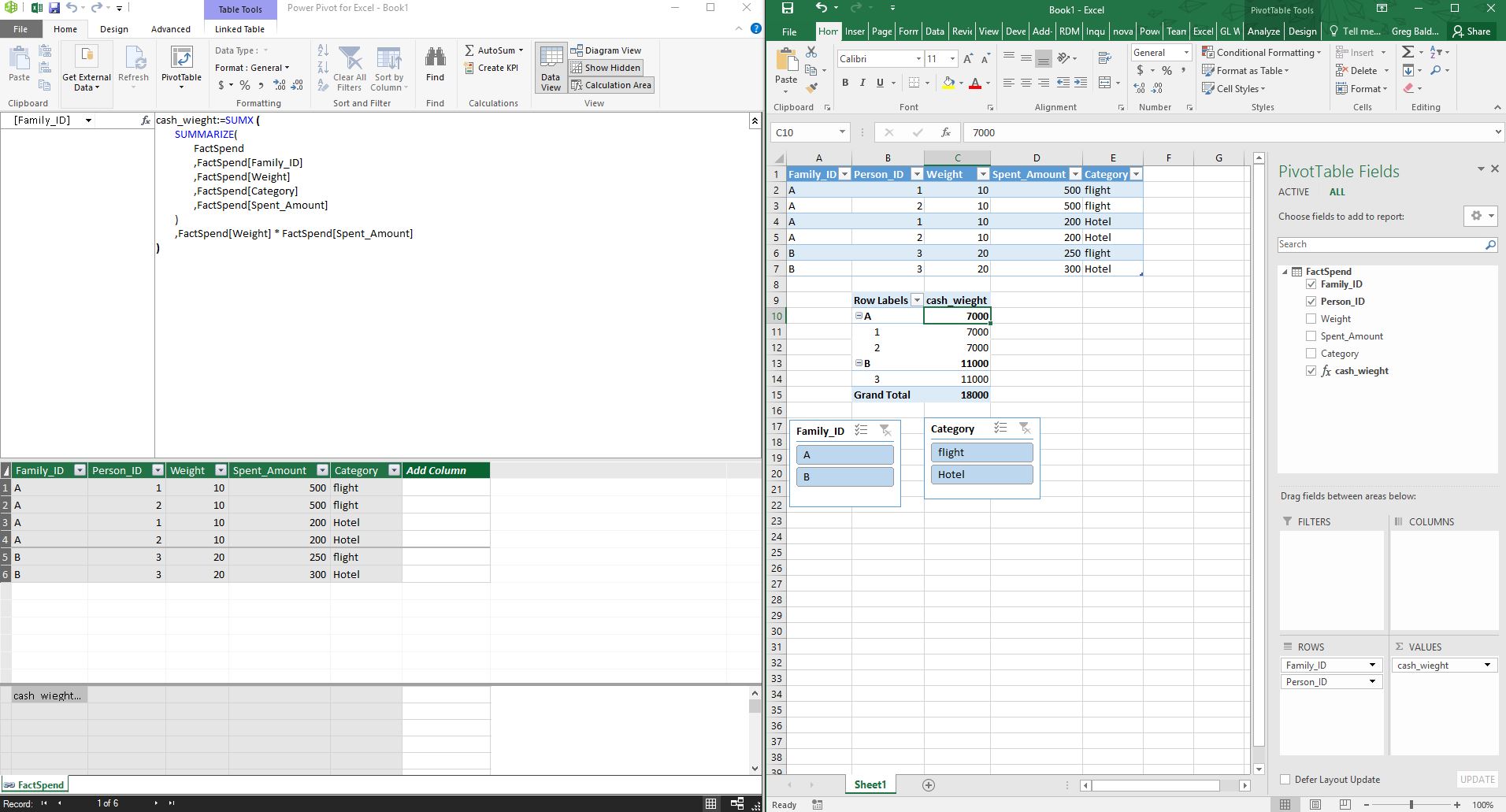
cash_wieght:=
SUMX (
SUMMARIZE(
FactSpend
,FactSpend[Family_ID]
,FactSpend[Weight]
,FactSpend[Category]
,FactSpend[Spent_Amount]
)
,FactSpend[Weight] * FactSpend[Spent_Amount]
)
Здесь мы используем SUMMARIZE () для группировки по [Family_ID], [Weight], [Category] и [Spent_Amount]. Поскольку сложение и умножение являются коммутативными, не имеет значения, добавляем ли мы сначала или сначала умножаем.
Поэтому мы используем SUMX() для итерации по каждой строке, возвращаемой нашим SUMMARIZE(), и накапливаем в сумму значения [Weight] * [Spent_Amount] для каждой строки в этой сгруппированной таблице.
Вот изображение моей выборки данных и сводной таблицы, основанной на соответствующем выполнении этой меры. Это также работает при добавлении любых атрибутов из таблицы в контекст фильтра. Если один [Person_ID] находится в контексте, мера вернет значение для семьи, а на уровне семьи вернет значение для семьи. Мы можем изменить меру, чтобы при необходимости дать только одну [Person_ID] часть целого [Family_ID].