WebRtc Акустическое эхоподавление3 (AEC3), дающее плоский MicOutPut после эхоподавления
Позвольте мне начать эту тему, заявив, что я совершенно новичок в WebRtc, и если я упомяну что-нибудь полу-остроумное, пожалуйста, потерпите меня.
Я пишу приложение, которое выполняет сравнение производительности эхоподавления между Speex и Web RTC AEC3. [База кодов WebRtc AEC3 (новейшая ветка): https://webrtc.googlesource.com/src/+/branch-heads/72]
Приложение читает WAV-файлы и передает образцы в модуль AEC, а WAV-модуль записи сохраняет результаты эхоподавления,
У меня есть 2 входа: 1) Вход динамика или визуализированный сигнал или сигнал FarEnd 2) Микрофонный вход или захваченный сигнал или сигнал ближнего конца
И один выход: 1) MicOutput- который является результатом эхоподавления.
Теперь для модулей Speex, я вижу хорошо себя вести. Пожалуйста, посмотрите на следующий файл, он хорошо справляется с отменой обработанного сигнала из Захваченного сигнала.
Тем не менее, когда я передаю те же файлы с WebRtc Aec3, я получаю сигнал. Ниже приведен результат AEC3.
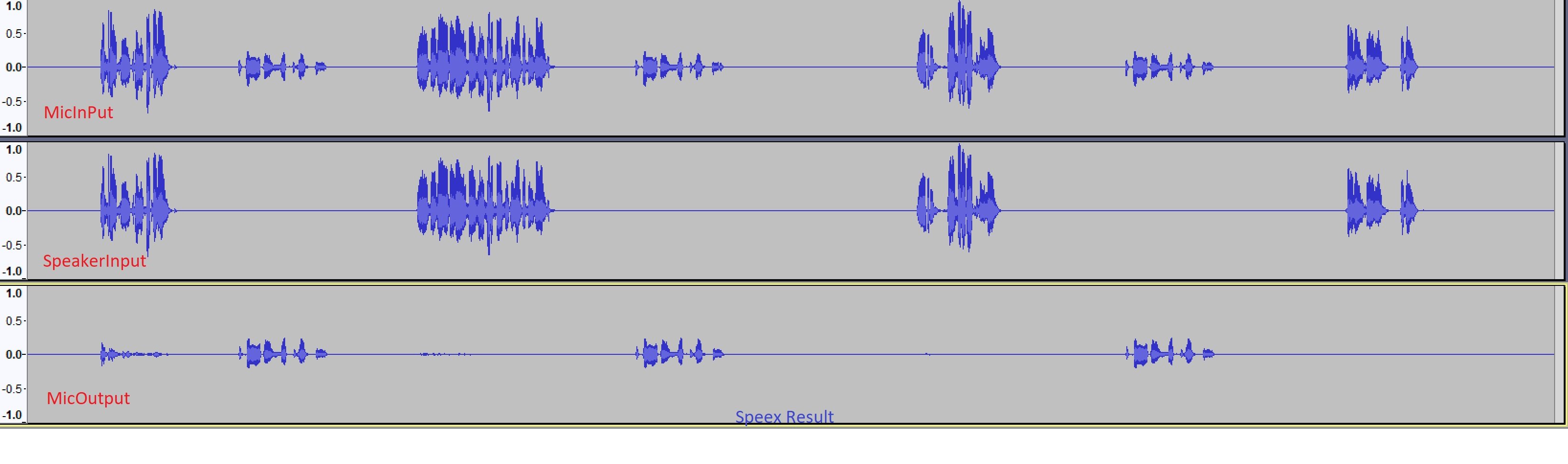
Кажется, что он также подавляет оригинальный микрофонный сигнал.
Я использую следующие параметры (извлеченные из программы чтения файлов Wav): Частота дискретизации: 8000 Канал: 1 бит / Образец: 16 Количество образцов: 270399 Образцы, поданные в AEC за раз: (10 * SampleRate)/1000 = 80
Это инициализация:
m_streamConfig.set_sample_rate_hz(sampleRate);
m_streamConfig.set_num_channels(CHANNEL_COUNT);
// Create a temporary buffer to convert our RTOP input audio data into the webRTC required AudioBuffer.
m_tempBuffer[0] = static_cast<float*> (malloc(sizeof(float) * m_samplesPerBlock));
// Create AEC3.
m_echoCanceller3.reset(new EchoCanceller3(m_echoCanceller3Config, sampleRate, true)); //use high pass filter is true
// Create noise suppression.
m_noiseSuppression.reset(new NoiseSuppressionImpl(&m_criticalSection));
m_noiseSuppression->Initialize(CHANNEL_COUNT, sampleRate);
И вот как я называю API:
auto renderAudioBuffer = CreateAudioBuffer(spkSamples);
auto capturedAudioBuffer = CreateAudioBuffer(micSamples);
// Analyze capture buffer
m_echoCanceller3->AnalyzeCapture(capturedAudioBuffer.get());
// Analyze render buffer
m_echoCanceller3->AnalyzeRender(renderAudioBuffer.get());
// Cancel echo
m_echoCanceller3->ProcessCapture(
capturedAudioBuffer.get(), false);
// Assuming the analog level is not changed.
//If we want to detect change, need to use gain controller and remember the previously rendered audio's analog level
// Copy the Captured audio out
capturedAudioBuffer->CopyTo(m_streamConfig, m_tempBuffer);
arrayCopy_32f(m_tempBuffer[0], micOut, m_samplesPerBlock);
А также в отношении параметров (задержка, echoModel, реверберация, noisefloor и т. Д.), Я использую все значения по умолчанию.
Может кто-нибудь сказать мне, что я делаю не так? Или как я могу сделать это лучше, настроив соответствующие параметры?
UpDate: (22/02/2019) Выяснил, почему звук эха отключен. Похоже, Webrtc AEC3 не может обработать частоту дискретизации 8k и 16k, хотя в исходном коде есть указания, что они поддерживают 4 различные частоты дискретизации: 8k, 16k, 32k и 48k. Я получил вывод с эхоподавлением после того, как дал ввод сэмплов 32k и 48k. Однако я не вижу никакой эхоподавления. Он просто выплевывает точные сэмплы, как он был подан на вход NearEnd/Mic/Captured. Так что да, возможно, мне не хватает настроек ключевых параметров. Все еще ищу помощь.
2 ответа
Вы должны разделить входные сигналы на полосы частот, прежде чем передавать их в AEC3:
renderAudioBuffer->SplitIntoFrequencyBands();
m_echoCanceller3->AnalyzeRender(renderAudioBuffer.get());
renderAudioBuffer->MergeFrequencyBands();
capturedAudioBuffer->SplitIntoFrequencyBands();
m_echoCanceller3->ProcessCapture(capturedAudioBuffer.get(), false);
capturedAudioBuffer->MergeFrequencyBands();
- AudioBuffer
наиболее важным является то, что называется "задержка", вы можете найти ее определение в audio_processing.h
Устанавливает | задержку | в мс между ProcessReverseStream(), получающим фрейм на дальнем конце, и ProcessStream(), получающим фрейм на ближнем конце, содержащий соответствующее эхо. На стороне клиента это может быть выражено как delay = (t_render - t_analyze) + (t_process - t_capture), где,
- t_analyze is the time a frame is passed to ProcessReverseStream() and
t_render is the time the first sample of the same frame is rendered by
the audio hardware.
- t_capture is the time the first sample of a frame is captured by the
audio hardware and t_process is the time the same frame is passed to
ProcessStream().
2. EchoCanceller3 задержка
SetAudioBufferDelay(int dealy);