Повторяющиеся строки data.frame в dplyr
У меня проблема с повторением строк моих реальных данных с использованием dplyr, Здесь уже есть еще один пост, где есть повторяющиеся строки данных, но нет решения для dplyr,
Вот мне просто интересно как могло быть решение для dplyr но не удалось с ошибкой:
Ошибка: неверный размер результата (16), ожидаемый 4 или 1
library(dplyr)
df <- data.frame(column = letters[1:4])
df_rep <- df%>%
mutate(column=rep(column,each=4))
Ожидаемый результат
>df_rep
column
#a
#a
#a
#a
#b
#b
#b
#b
#*
#*
#*
2 ответа
Это опасно, если в data.frame есть другие столбцы (там, я это сказал!), Но do Блок позволит вам генерировать производные data.frame в пределах dplyr труба (хотя, ceci n'est pas un pipe):
library(dplyr)
df <- data.frame(column = letters[1:4], stringsAsFactors = FALSE)
df %>%
do( data.frame(column = rep(.$column, each = 4), stringsAsFactors = FALSE) )
# column
# 1 a
# 2 a
# 3 a
# 4 a
# 5 b
# 6 b
# 7 b
# 8 b
# 9 c
# 10 c
# 11 c
# 12 c
# 13 d
# 14 d
# 15 d
# 16 d
С использованием uncount Функция решит и эту проблему. Колонка count указывает, как часто строка должна повторяться
library(tidyverse)
df <- tibble(letters = letters[1:4])
df
# A tibble: 4 x 1
letters
<chr>
1 a
2 b
3 c
4 d
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
uncount(count)
# A tibble: 11 x 1
letters
<chr>
1 a
2 a
3 b
4 b
5 b
6 c
7 c
8 d
9 d
10 d
11 d
Я искал похожее (но немного другое) решение. Размещать здесь на случай, если это пригодится кому-либо еще.
В моем случае мне нужно было более общее решение, позволяющее повторять каждую букву произвольное количество раз. Вот что я придумал:
library(tidyverse)
df <- data.frame(letters = letters[1:4])
df
> df
letters
1 a
2 b
3 c
4 d
Допустим, я хочу 2 A, 3 B, 2 C и 4 D:
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
group_by(letters) %>%
expand(count = seq(1:count))
# A tibble: 11 x 2
# Groups: letters [4]
letters count
<fctr> <int>
1 a 1
2 a 2
3 b 1
4 b 2
5 b 3
6 c 1
7 c 2
8 d 1
9 d 2
10 d 3
11 d 4
Если вы не хотите сохранять столбец count:
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
group_by(letters) %>%
expand(count = seq(1:count)) %>%
select(letters)
# A tibble: 11 x 1
# Groups: letters [4]
letters
<fctr>
1 a
2 a
3 b
4 b
5 b
6 c
7 c
8 d
9 d
10 d
11 d
Если вы хотите, чтобы число отражало количество повторений каждой буквы:
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
group_by(letters) %>%
expand(count = seq(1:count)) %>%
mutate(count = max(count))
# A tibble: 11 x 2
# Groups: letters [4]
letters count
<fctr> <dbl>
1 a 2
2 a 2
3 b 3
4 b 3
5 b 3
6 c 2
7 c 2
8 d 4
9 d 4
10 d 4
11 d 4
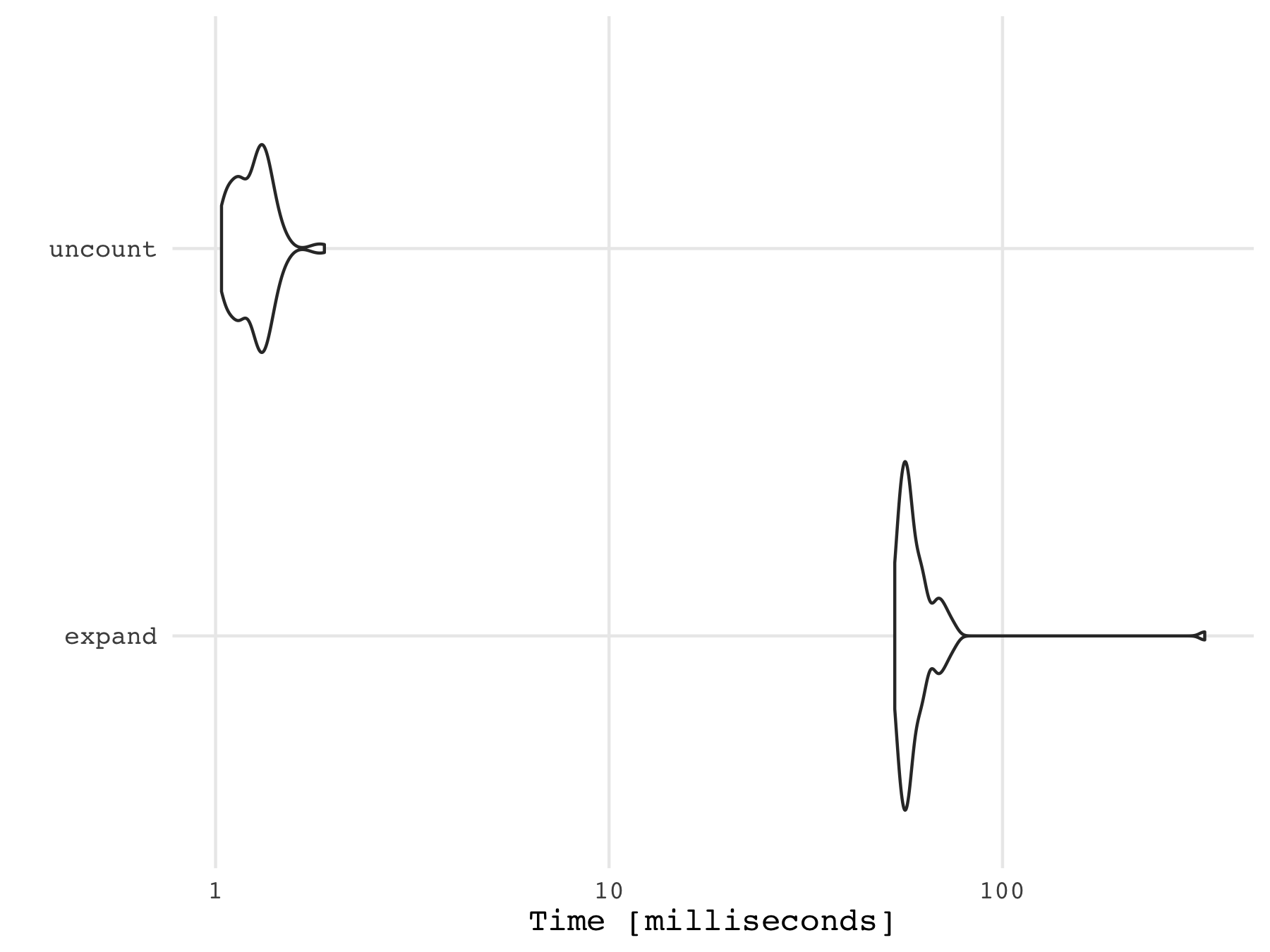
Я провел быстрый тест, чтобы показать, что uncount() намного быстрее, чем expand()
# for the pipe
library(magrittr)
# create some test data
df_test <-
tibble::tibble(
letter = letters,
row_count = sample(1:10, size = 26, replace = TRUE)
)
# benchmark
bench <- microbenchmark::microbenchmark(
expand = df_test %>%
dplyr::group_by(letter) %>%
tidyr::expand(row_count = seq(1:row_count)),
uncount = df_test %>%
tidyr::uncount(row_count)
)
# plot the benchmark
ggplot2::autoplot(bench)