Hive / Tez работа не начнется
Я пытаюсь создать ORC table в Hive путем импорта из текстового файла в HDFS. Я пробовал несколько разных способов, искал в Интернете помощь, и независимо от того, задание вставки не запустится.
Я могу получить текстовый файл в HDFS, я могу прочитать текстовый файл в Hive, но я не могу преобразовать его в ORC.
Я пробовал много разных вариантов, в том числе этот, который можно использовать как ссылку на этот вопрос:
У меня есть одноузловой кластер HDP (используется для разработки) - версия:
HDP-2.3.2.0
(2.3.2.0-2950)
И вот соответствующие версии сервиса:
Сервисная версия Статус Описание
HDFS 2.7.1.2.3 Установленная распределенная файловая система Apache Hadoop
MapReduce2 2.7.1.2.3 Установленный Apache Hadoop NextGen MapReduce (YARN)
YARN 2.7.1.2.3 Установленный Apache Hadoop NextGen MapReduce (YARN)
Tez 0.7.0.2.3 Установлено Tez - это инфраструктура Hadoop Query Processing следующего поколения, написанная поверх YARN.
Hive 1.2.1.2.3 Установленная система хранилища данных для специальных запросов и анализа больших наборов данных и службы управления таблицами и хранилищами
Что происходит, когда я запускаю такой SQL-код (опять же, я пробовал много вариантов, в том числе непосредственно из онлайн-уроков):
ВСТАВИТЬ ПЕРЕЗАПИСАТЬ СТОЛ mycars SELECT * ИЗ автомобилей;
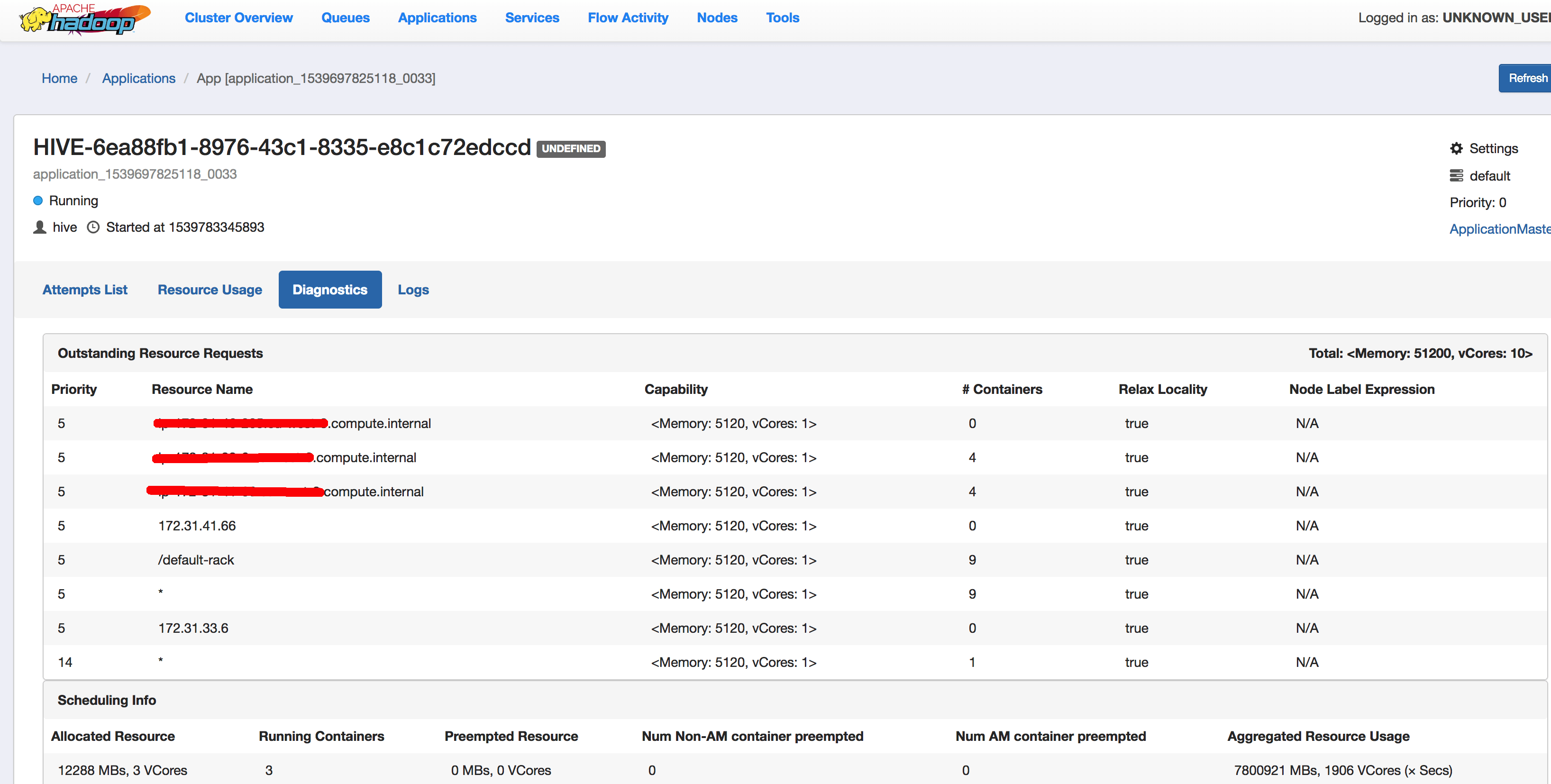
Моя работа остается такой:
Общее количество приложений (типы приложений: [] и состояния:
[ПРЕДОСТАВЛЕНО, ПРИНЯТО, РАБОТАЕТ]):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1455989658079_0002 HIVE-3f41161c-b806-4e7d-974e-c18e028d683f TEZ hive root.hive ACCEPTED UNDEFINED 0% N/A
И это просто висит там. (Буквально, я попробовал таблицу с 20 строками и оставил ее работать на несколько часов, прежде чем убить ее).
Я ни в коем случае не эксперт по Hadoop (пока), и я уверен, что это, вероятно, проблема с конфигурацией, но я не смог понять это.
Все другие операции Hive, которые я пробовал, такие как создание отбрасываемых таблиц, загрузка файла в текстовую таблицу, выбор, все работают нормально. Это просто, когда я создаю таблицу ORC, это делает это. И мне нужен стол ORC для моего требования.
Любые советы будут полезны.
1 ответ
В большинстве случаев это связано с увеличением емкости планирования пряжи, но если ваши ресурсы уже ограничены, вы также можете уменьшить объем памяти, запрашиваемый отдельными задачами TEZ, путем настройки следующего свойства в конфигурации TEZ:
task.resource.memory.mb
Для увеличения емкости Кластера вы можете сделать это в настройках конфигурации YARN или напрямую через Ambari или Cloudera Manager.
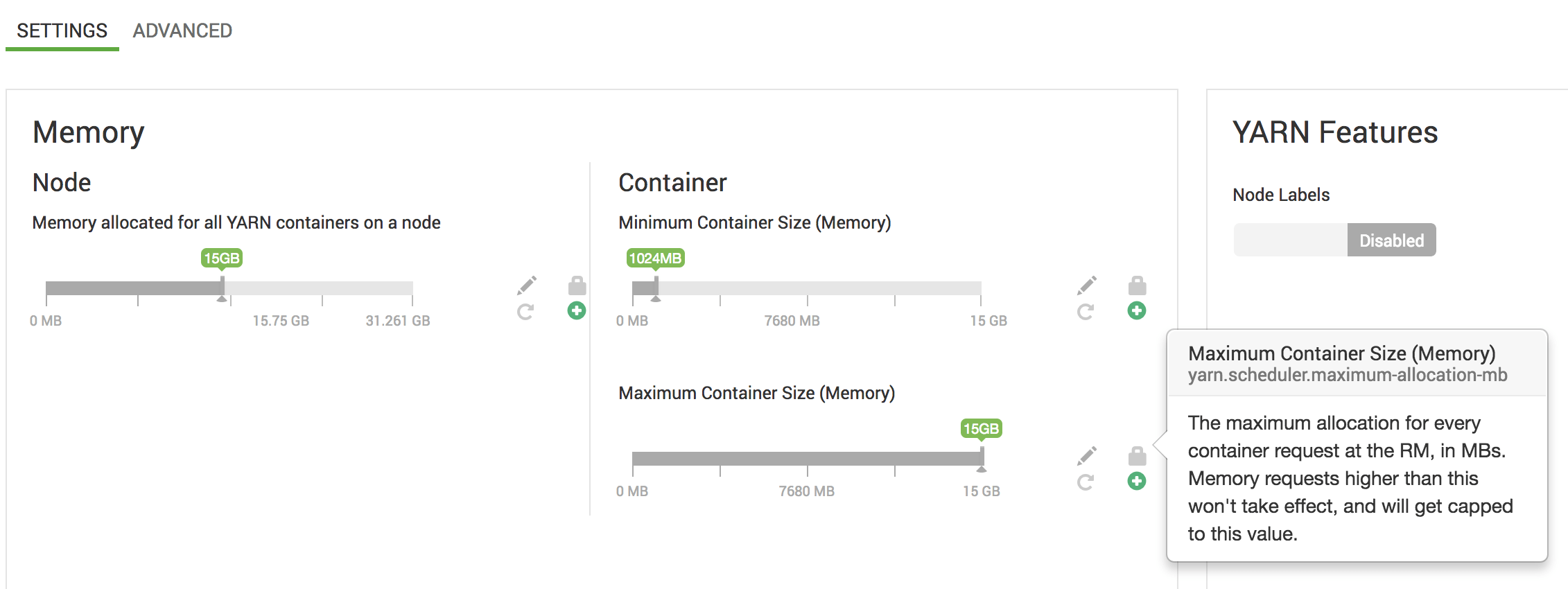
Чтобы следить за тем, что происходит за кулисами, вы можете запустить пользовательский интерфейс Yarn Resource Manager и проверить вкладку "Диагностика" конкретного приложения. Здесь есть полезные явные сообщения о распределении ресурсов, особенно когда задание принято и находится в состоянии ожидания.