Как создать индексированное представление количества детей
Я пытаюсь взять таблицу с отношениями родитель-ребенок и узнать количество детей. Я хотел бы создать индексированное представление о количестве детей, используя COUNT_BIG(*),
Проблема в том, что в моем представлении индекса я не хочу удалять сущности, у которых нет дочерних элементов, вместо этого я хочу Count быть 0 для тех.
Дано
> Id | Entity | Parent
> -: | :----- | :-----
> 1 | A | null
> 2 | AA | A
> 3 | AB | A
> 4 | ABA | AB
> 5 | ABB | AB
> 6 | AAA | AA
> 7 | AAB | AA
> 8 | AAC | AA
Я хочу создать индексированное представление, которое возвращает
> Entity | Count
> :----- | ----:
> A | 2
> AA | 3
> AB | 2
> ABA | 0
> ABB | 0
> AAA | 0
> AAB | 0
> AAC | 0
Вот мой SQL, который работает, но с использованием LEFT JOIN и CTE (оба не допускаются в представлении индекса)
DROP TABLE IF EXISTS Example CREATE TABLE Example ( Id INT primary key, Entity varchar(50), Parent varchar(50) ) INSERT INTO Example VALUES (1, 'A', NULL) ,(2, 'AA', 'A') ,(3, 'AB','A') ,(4, 'ABA', 'AB') ,(5, 'ABB', 'AB') ,(6, 'AAA', 'AA') ,(7, 'AAB', 'AA') ,(8, 'AAC', 'AA') SELECT * FROM Example ;WITH CTE AS ( SELECT Parent, COUNT(*) as Count FROM dbo.Example GROUP BY Parent ) SELECT e.Entity, COALESCE(Count,0) Count FROM dbo.Example e LEFT JOIN CTE g ON e.Entity = g.Parent GO
3 ответа
Я не думаю, что вы можете достичь этого, используя CTE или LEFT JOIN, потому что существует много ограничений на использование индексированных представлений.
Временное решение
Я предлагаю разделить запрос на две части:
- Создайте индексированное представление вместо общего табличного выражения (CTE)
- Создайте неиндексированное представление, которое выполняет LEFT JOIN
Кроме того, создайте некластеризованный индекс на Entity столбец в таблице Example,
Затем, когда вы запрашиваете неиндексированное представление, оно будет использовать индексы
--CREATE TABLE
CREATE TABLE Example (
Id INT primary key,
Entity varchar(50),
Parent varchar(50)
)
--INSERT VALUES
INSERT INTO Example
VALUES
(1, 'A', NULL)
,(2, 'AA', 'A')
,(3, 'AB','A')
,(4, 'ABA', 'AB')
,(5, 'ABB', 'AB')
,(6, 'AAA', 'AA')
,(7, 'AAB', 'AA')
,(8, 'AAC', 'AA')
--CREATE NON CLUSTERED INDEX
CREATE NONCLUSTERED INDEX idx1 ON dbo.Example(Entity);
--CREATE Indexed View
CREATE VIEW dbo.ExampleView_1
WITH SCHEMABINDING
AS
SELECT Parent, COUNT_BIG(*) as Count
FROM dbo.Example
GROUP BY Parent
CREATE UNIQUE CLUSTERED INDEX idx ON dbo.ExampleView_1(Parent);
--Create non-indexed view
CREATE VIEW dbo.ExampleView_2
WITH SCHEMABINDING
AS
SELECT e.Entity, COALESCE(Count,0) Count
FROM dbo.Example e
LEFT JOIN dbo.ExampleView_1 g
ON e.Entity = g.Parent
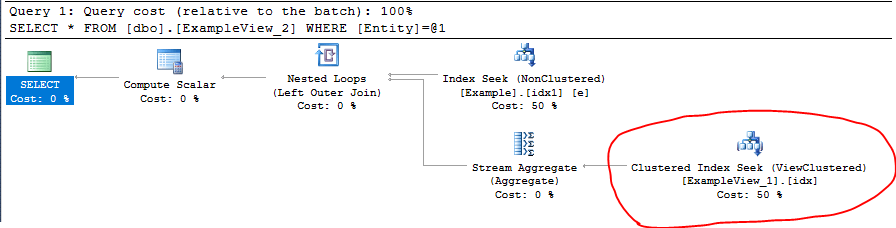
Поэтому при выполнении следующего запроса:
SELECT * FROM dbo.ExampleView_2 WHERE Entity = 'A'
Вы можете видеть, что представление Clustered index и Table Non-Clustered index используются в плане выполнения:
Дополнительная информация
Я не нашел дополнительных обходных путей для замены использования LEFT JOIN или же UNION или же CTE в индексированных представлениях вы можете проверить много похожих вопросов Stackru:
- Индексирование представлений с помощью CTE
- Чем заменить левое соединение в представлении, чтобы иметь индексированное представление?
- Создать индекс по представлению SQL с операторами UNION? Это действительно улучшит производительность?
Обновление 1 - Разделение вида против декартового объединения
Чтобы определить лучший подход, я попытался сравнить оба предложенных подхода.
--The other approach (cartesian join)
CREATE TABLE TwoRows (
N INT primary key
)
INSERT INTO TwoRows
VALUES (1),(2)
CREATE VIEW dbo.indexedView WITH SCHEMABINDING AS
SELECT
IIF(T.N = 2, Entity, Parent) as Entity
, COUNT_BIG(*) as CountPlusOne
, COUNT_BIG(ALL IIF(T.N = 2, NULL, 1)) as Count
FROM dbo.Example E1
INNER JOIN dbo.TwoRows T
ON 1=1
WHERE IIF(T.N = 2, Entity, Parent) IS NOT NULL
GROUP BY IIF(T.N = 2, Entity, Parent)
GO
CREATE UNIQUE CLUSTERED INDEX testIndex ON indexedView(Entity)
Я создал каждое индексированное представление для отдельных баз данных и выполнил следующий запрос:
SELECT * FROM View WHERE Entity = 'AA'
Расщепление зрения
Декартово соединение
Статистика по времени
Статистика времени показывает, что время выполнения подхода декартового объединения выше, чем подход представления разделения, как показано на рисунке ниже (декартовое соединение справа):
Добавление с (NOEXPAND)
Также я попытался добавить WITH(NOEXPAND) При выборе варианта декартового объединения ядро базы данных использует кластеризованный индекс индексированного представления, и в результате получается следующее:
Я очистил все кэши и выполнил сравнение. Сравнение статистики по времени показывает, что подход представления с разделением по-прежнему быстрее, чем подход с декартовым соединением ( WITH(NOEXPAND) подход справа):
Я смог выполнить то, что хотел, выполнив декартово объединение строк, которое будет равно 0 (N=2).
Создайте таблицу под названием две строки, которые будут дублировать внуков
DROP TABLE IF EXISTS TwoRows
CREATE TABLE TwoRows (
N INT primary key
)
INSERT INTO TwoRows
VALUES (1),(2)
Получить оригинальный стол
DROP TABLE IF EXISTS Example
CREATE TABLE Example (
Id INT primary key,
Entity varchar(50),
Parent varchar(50)
)
INSERT INTO Example
VALUES
(1, 'A', NULL)
,(2, 'AA', 'A')
,(3, 'AB','A')
,(4, 'ABA', 'AB')
,(5, 'ABB', 'AB')
,(6, 'AAA', 'AA')
,(7, 'AAB', 'AA')
,(8, 'AAC', 'AA')
Создать индексированное представление
DROP VIEW IF EXISTS dbo.indexedView
CREATE VIEW dbo.indexedView WITH SCHEMABINDING AS
SELECT
IIF(T.N = 2, Entity, Parent) as Entity
, COUNT_BIG(*) as CountPlusOne
, COUNT_BIG(ALL IIF(T.N = 2, NULL, 1)) as Count
FROM dbo.Example E1
INNER JOIN dbo.TwoRows T
ON 1=1
WHERE IIF(T.N = 2, Entity, Parent) IS NOT NULL
GROUP BY IIF(T.N = 2, Entity, Parent)
GO
CREATE UNIQUE CLUSTERED INDEX testIndex ON indexedView(Entity)
SELECT *
FROM indexedView
Я не мог, как избежать использования COUNT_BIG(*)
Вы можете создать AFTER INSERT,UPDATE, DELETE вызвать на вашем example таблица и новая таблица для материализации результатов.
В триггере вы можете использовать любой оператор. Вы можете сделать это двумя способами, в зависимости от того, насколько быстро ваш запрос начальный запрос.
Например, вы можете обрезать таблицу на каждом INSERT/UPDATE/DELETE а затем рассчитать количество и вставить его снова (если запрос быстрый).
Или вы можете положиться на inserted а также deleted таблицы, которые являются специальными таблицами, видимыми в контексте триггера и показывающими, как изменились значения строк.
Например, если запись существует в inserted стол, а не в deleted - это (есть) новый ряд (ы). Вы можете рассчитать COUNT только для них.
Если запись существует только в deleted Таблица - это удаление (нам нужно удалить строку для нашей предварительно рассчитанной таблицы).
И в обеих таблицах есть строка - это обновление - нам нужно выполнить новый подсчет для записи.
Здесь очень важно одно - не манипулируйте строками один за другим. Всегда работайте партиями строк для трех вышеописанных случаев, иначе вы получите неэффективный триггер, который задержит операции CRUD с исходной таблицей.