Найти количество раз, когда комбинация встречается в массивном двумерном массиве
У меня есть двумерный массив numy, и я хочу, чтобы функция работала с col1 и col2 массива. Если "M" - это число уникальных значений из col1, а "N" - это число уникальных значений из col2, то вывод 1D массив будет иметь размер (M * N). Например, предположим, что в col1 есть 3 уникальных значения: A1, A2 и A3 и 2 уникальных значения в col2: X1 и X2. Тогда возможны следующие комбинации:(A1 X1),(A1 X2),(A2 X1),(A2 X2),(A3 X1),(A3 X2). Теперь я хочу выяснить, сколько раз каждая комбинация встречается вместе в одной и той же строке, т.е. сколько там строк, содержащих эту комбинацию (A1,X1) и т. Д. Я хочу вернуть счет в виде одномерного массива. Это мой код:
import numpy as np
#@profile
def myfunc(arr1,arr2):
unique_arr1 = np.unique(arr1)
unique_arr2 = np.unique(arr2)
pdt = len(unique_arr1)*len(unique_arr2)
count = np.zeros(pdt).astype(int)
## getting the number of possible combinations and storing them in arr1_n and arr2_n
if ((len(unique_arr2)>0) and (len(unique_arr1)>0)):
arr1_n = unique_arr1.repeat(len(unique_arr2))
arr2_n = np.tile(unique_arr2,len(unique_arr1))
## Finding the number of times a particular combination has occured
for i in np.arange(0,pdt):
pos1 = np.where(arr1==arr1_n[i])[0]
pos2 = np.where(arr2==arr2_n[i])[0]
count[i] = len(np.intersect1d(pos1,pos2))
return count
np.random.seed(1)
myarr = np.random.randint(20,size=(80000,4))
a = myfunc(myarr[:,1],myarr[:,2])
Ниже приведены результаты профилирования, когда я запускаю line_profiler для этого кода.
Таймер: 1e-06 с
Общее время: 18,1849 с Файл: testcode3.py Функция: myfunc в строке 2
Строка № Хиты Время на удар% Содержание строки
2 @profile
3 def myfunc(arr1,arr2):
4 1 74549.0 74549.0 0.4 unique_arr1 = np.unique(arr1)
5 1 72970.0 72970.0 0.4 unique_arr2 = np.unique(arr2)
6 1 9.0 9.0 0.0 pdt = len(unique_arr1)*len(unique_arr2)
7 1 48.0 48.0 0.0 count = np.zeros(pdt).astype(int)
8
9 1 5.0 5.0 0.0 if ((len(unique_arr2)>0) and (len(unique_arr1)>0)):
10 1 16.0 16.0 0.0 arr1_n = unique_arr1.repeat(len(unique_arr2))
11 1 105.0 105.0 0.0 arr2_n = np.tile(unique_arr2,len(unique_arr1))
12 401 5200.0 13.0 0.0 for i in np.arange(0,pdt):
13 400 6870931.0 17177.3 37.8 pos1 = np.where(arr1==arr1_n[i])[0]
14 400 6844999.0 17112.5 37.6 pos2 = np.where(arr2==arr2_n[i])[0]
15 400 4316035.0 10790.1 23.7 count[i] = len(np.intersect1d(pos1,pos2))
16 1 4.0 4.0 0.0 return count
Как видите, np.where и np.intersect1D занимают много времени. Кто-нибудь может предложить более быстрые способы сделать это? В будущем мне придется работать с реальными данными, намного большими, чем эта, поэтому мне нужно оптимизировать этот код.
2 ответа
Чтобы соответствовать требованиям Bidisha Das:
Код:
def myfunc3(arr1, arr2):
order_mag = 10**(int(math.log10(np.amax([arr1, arr2]))) + 1)
complete_arr = arr1*order_mag + arr2
unique_elements, counts_elements = np.unique(complete_arr, return_counts=True)
unique_arr1 = np.unique(arr1)
unique_arr2 = np.unique(arr2)
r = np.zeros((len(unique_arr1), len(unique_arr2)))
for i in range(len(unique_elements)):
i1 = np.where(unique_arr1==int(unique_elements[i]/order_mag))
i2 = np.where(unique_arr2==(unique_elements[i]%order_mag))
r[i1,i2] += counts_elements[i]
r = r.flatten()
return r
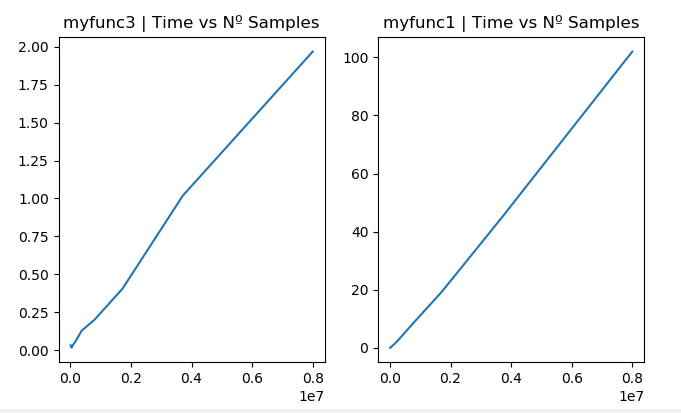
Тестовый код:
times_f3 = []
times_f1 = []
ns = 8*10**np.linspace(3, 6, 10)
for i in ns:
np.random.seed(1)
myarr = np.random.randint(20,size=(int(i),4))
start1 = time.time()
a = myfunc3(myarr[:,1],myarr[:,2])
end1 = time.time()
times_f3.append(end1-start1)
start2 = time.time()
b = myfunc(myarr[:,1],myarr[:,2])
end2 = time.time()
times_f1.append(end2-start2)
print("N: {:1>d}, myfucn2 time: {:.3f} ms, myfucn time: {:.3f} ms".format(int(i), (end1-start1)*1000.0, (end2-start2)*1000.0))
print("Equal?: " + str(np.array_equal(a,b)))
Результаты:
Зная максимально возможное значение ваших столбцов, вы можете использовать:
def myfunc2(arr1,arr2):
# The *100 depends on your maximum possible value
complete_arr = myarr[:,1]*100 + myarr[:,2]
unique_elements, counts_elements = np.unique(complete_arr, return_counts=True)
return counts_elements
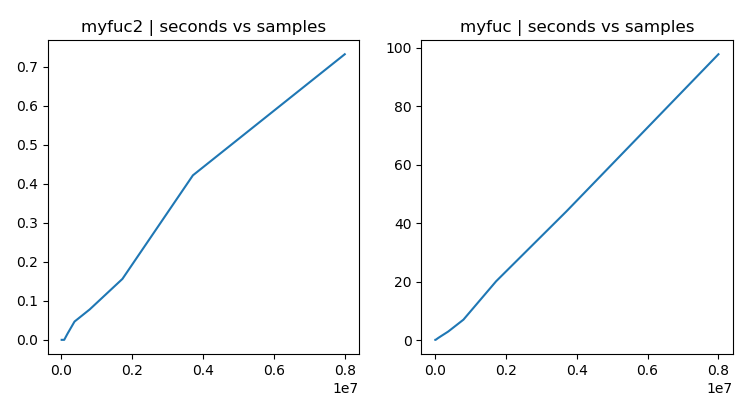
Результаты с 8·10e5 и 8·10e6 строк:
N: 800000, myfucn2 time: 78.287 ms, myfucn time: 6556.748 ms
Equal?: True
N: 8000000, myfucn2 time: 736.020 ms, myfucn time: 100544.354 ms
Equal?: True
Тестовый код:
times_f1 = []
times_f2 = []
ns = 8*10**np.linspace(3, 6, 10)
for i in ns:
np.random.seed(1)
myarr = np.random.randint(20,size=(int(i),4))
start1 = time.time()
a = myfunc2(myarr[:,1],myarr[:,2])
end1 = time.time()
times_f2.append(end1-start1)
start2 = time.time()
b = myfunc(myarr[:,1],myarr[:,2])
end2 = time.time()
times_f1.append(end2-start2)
print("N: {:1>d}, myfucn2 time: {:.3f} ms, myfucn time: {:.3f} ms".format(int(i), (end1-start1)*1000.0, (end2-start2)*1000.0))
print("Equal?: " + str(np.array_equal(a,b)))
Временная сложность кажется O(n) для обоих случаев: