Нормализация отношения многие ко многим в sql
У меня есть таблица продуктов, которая содержит два столбца
ProductID Desc
1 Fan
2 Table
3 Bulb
У меня есть другая таблица, которая содержит информацию о поставщике
SupplierID Desc
1 ABC
2 XYZ
3 HJK
Теперь один поставщик может поставлять несколько продуктов, а один продукт может поставляться несколькими поставщиками. Для этого я создал другую таблицу tbl_Supplier_Product.
SupplierID ProductID
1 1
1 2
2 1
2 2
2 3
Это хороший способ связать эту таблицу с поставщиком и таблицей продуктов через первичный составной ключ. В этой таблице первичным ключом будет составной ключ (SupplierID и ProductID) или я должен добавить дополнительный идентификатор строки столбца для каждой записи, а затем использовать его в качестве первичного ключа и добавить уникальное ограничение для столбцов SupplierID и ProductID.
SupplierID ProductID Row ID
1 1 1
1 2 2
2 1 3
2 2 4
2 3 5
UNIQUE CONSTRAINT(SupplierID, ProductID)
Каково отношение этой таблицы к таблице поставщиков? Я немного запутался здесь, потому что я добавил эту таблицу, чтобы разрешить взаимосвязь многих ко многим и избыточные данные, но все же кажется, что эта таблица имеет много ко многим отношениям с обеими таблицами??
2 ответа
Вам не нужен дополнительный столбец: составной ключ - это все, что вам нужно
Я хотел бы создать уникальный индекс, который также является обратным к PK: это полезно для многих запросов, а также предоставляет индекс FK для ProductID.
После комментария:
CREATE TABLE SupplierProduct (
SupplierID int NOT NULL,
ProductID int NOT NULL,
PRIMARY KEY (SupplierID, ProductID)
);
GO
CREATE UNIQUE NONCLUSTERED INDEX IXU_ReversePK ON SupplierProduct (ProductID, SupplierID);
GO
Для большего
- SQL: Вам нужен автоинкрементный первичный ключ для таблиц Many-Many? для более (см. комментарии)
- Разница между двумя индексами со столбцами, заданными в обратном порядке
И также используйте это, как правило, чтобы убедиться, что все ваши FK имеют индексы
SELECT fk.name AS [Missing FK Index]
FROM sys.foreign_keys fk
WHERE EXISTS
(
SELECT *
FROM sys.foreign_key_columns fkc
WHERE fkc.constraint_object_id = fk.object_id
AND NOT EXISTS
(
SELECT *
FROM sys.index_columns ic
WHERE ic.object_id = fkc.parent_object_id
AND ic.column_id = fkc.parent_column_id
AND ic.index_column_id = fkc.constraint_column_id
)
);
GO
В ERD (случайный из PowerPoint у меня есть):

Вы можете использовать составные ключи, но в наши дни более обычным является использование суррогатных ключей. Суррогат - это первичный ключ, который обычно представляет собой уникальный идентификатор GUID, не имеющий никакого значения ни для кого, кроме цели однозначной идентификации строки таблицы. Суррогат используется программным обеспечением только для внутренних целей, поэтому обычно пользователи никогда его не видят и не должны видеть.
Вы также должны использовать соглашение об именах для первичных ключей, где id является первичным ключом (это должен быть суррогатный ключ), а все внешние ключи - table.id. Часть таблицы сообщает вам, что это внешний ключ для этой таблицы. Так:
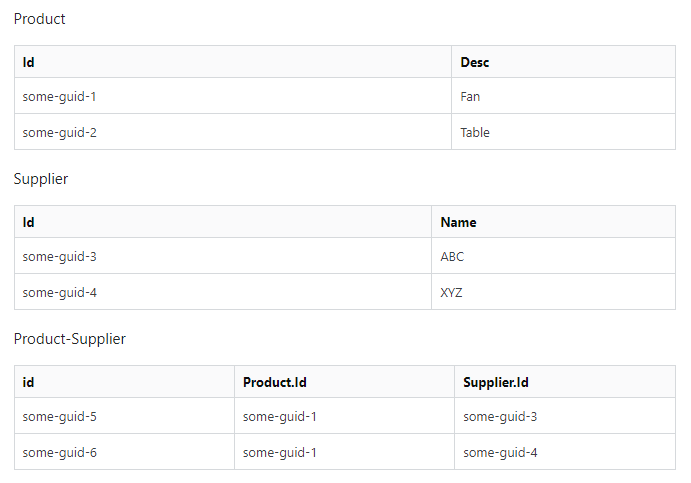
Таблица «продукт-поставщик» - это то, что некоторые называют «таблицей связей» или «таблицей соединений». Их задача - НОРМАЛИЗИРОВАТЬ отношения "многие ко многим". Это превращает отношения «многие ко многим» в отношения «один ко многим», и с тех пор мы все живем долго и счастливо. У такого количества продуктов может быть много поставщиков, а у многих поставщиков может быть много продуктов, нормализуется (разрешается) таблицей соединения продукт-поставщик, где у продукта есть от одной до многих строк продукта-поставщика, а у поставщика от одной до многих строк продукта-поставщика.
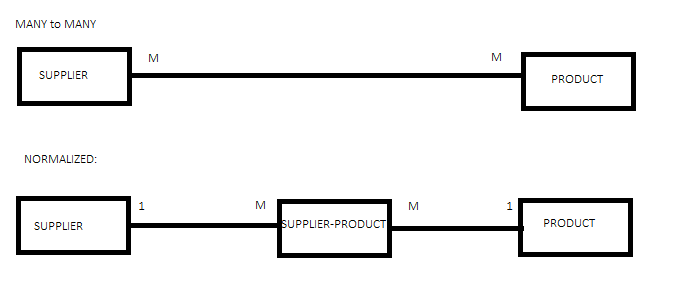
Обратите внимание, что объединенную таблицу можно назвать поставщиком-продуктом или продуктом-поставщиком, не имеет значения, как вы ее назовете, если она названа в честь родительских таблиц с дефисом между ними, это также соглашение об именах.
Дело здесь в том, что вы всегда разрешаете отношение «многие ко многим», нормализуя его в два отношения «один ко многим», как показано здесь.