Как получить data.frame с делами из таблицы сопряженности в r?
Я хотел бы воспроизвести некоторые расчеты из книги (логит регрессия). Книга дает таблицу непредвиденных расходов и результаты.
Вот таблица:
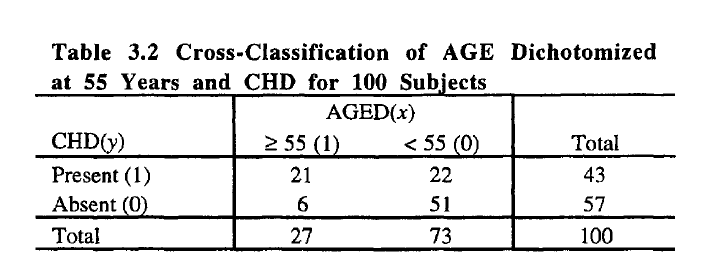
.
example <- matrix(c(21,22,6,51), nrow = 2, byrow = TRUE)
#Labels:
rownames(example) <- c("Present","Absent")
colnames(example) <- c(">= 55", "<55")
Это дает мне это:
>= 55 <55
Present 21 22
Absent 6 51
Но для использования функции glm() данные должны быть следующими:
(два столбца, один с "Возрастом" и один с "Подарком", заполненный 0/1)
age <- c(rep(c(0),27), rep(c(1),73))
present <- c(rep(c(0),21), rep(c(1),6), rep(c(0),22), rep(c(1),51))
data <- data.frame(present, age)
> data
present age
1 0 0
2 0 0
3 0 0
. . .
. . .
. . .
100 1 1
Есть ли простой способ получить эту структуру из таблицы / матрицы?
5 ответов
reshape2::melt(example)
Это даст вам,
Var1 Var2 value
1 Present >= 55 21
2 Absent >= 55 6
3 Present <55 22
4 Absent <55 51
который вы можете легко использовать для glm
Вы могли бы, возможно, использовать countsToCases функция, как определено здесь.
countsToCases(as.data.frame(as.table(example)))
# Var1 Var2
#1 Present >= 55
#1.1 Present >= 55
#1.2 Present >= 55
#1.3 Present >= 55
#1.4 Present >= 55
#1.5 Present >= 55
# ...
Вы всегда можете перекодировать переменные в числовые значения, если хотите.
Код ниже может выглядеть длинным, но только group_by() а также do() Инструкция заниматься расширением данных. Все остальное касается изменения данных в длинном формате и кодирования символьных переменных в 0 и 1. Я попытался начать с точной матрицы, которую вы задали в своем вопросе.
Загрузка пакетов манипулирования данными
library(tidyr)
library(dplyr)
Создать фрейм данных
Создайте матрицу, как в вашем примере, но избегайте знаков ">" в именах столбцов
example <- matrix(c(21,22,6,51), nrow = 2, byrow = TRUE)
rownames(example) <- c("Present","Absent")
colnames(example) <- c("above55", "below55")
Преобразовать матрицу в кадр данных
example <- data.frame(example) %>%
add_rownames("chd")
Или просто создайте фрейм данных напрямую
data.frame(chd = c("Present", "Absent"),
above55 = c(21,6),
below55 = c(22,51))
Изменить данные
data2 <- example %>%
gather(age, nrow, -chd) %>%
# Encode chd and age as 0 or 1
mutate(chd = ifelse(chd=="Present",1,0),
age = ifelse(age=="above55",1,0)) %>%
group_by(chd, age) %>%
# Expand each variable by nrow
do(data.frame(chd = rep(.$chd,.$nrow),
age = rep(.$age,.$nrow)))
head(data2)
# Source: local data frame [6 x 2]
# Groups: chd, age [1]
#
# chd age
# (dbl) (dbl)
# 1 0 0
# 2 0 0
# 3 0 0
# 4 0 0
# 5 0 0
# 6 0 0
tail(data2)
# Source: local data frame [6 x 2]
# Groups: chd, age [1]
#
# chd age
# (dbl) (dbl)
# 1 1 1
# 2 1 1
# 3 1 1
# 4 1 1
# 5 1 1
# 6 1 1
table(data2)
# age
# chd 0 1
# 0 51 6
# 1 22 21
То же, что и в вашем примере, за исключением проблемы кодирования возраста, упомянутой в моем комментарии выше.
Я бы пошел на:
library(data.table)
tab <- data.table(AGED = c(1, 1, 0, 0),
CHD = c(1, 0, 1, 0),
Count = c(21, 6, 22, 51))
tabExp <- tab[rep(1:.N, Count), .(AGED, CHD)]
Изменить: Быстрое объяснение, так как мне потребовалось некоторое время, чтобы понять это:
В data.table объекты .N хранит количество строк в группе (если сгруппировано с by) или просто количество строк в целом data.tableИтак, в этом примере:
tab[rep(1:.N, Count)]
а также
tab[rep(1:4, Count)]
и наконец
tab[rep(1:4, c(21, 6, 22, 51)]
эквивалентны.
То же самое с базой R:
tab2 <- data.frame(AGED = c(1, 1, 0, 0),
CHD = c(1, 0, 1, 0),
Count = c(21, 6, 22, 51))
tabExp2 <- tab2[rep(1:nrow(tab2), tab2$Count), c("AGED", "CHD")]
Так, glm не совсем так негибко. Частично ?glm читает
For ‘binomial’ and ‘quasibinomial’ families the response can also
be specified as a ‘factor’ (when the first level denotes failure
and all others success) or as a two-column matrix with the columns
giving the numbers of successes and failures.
Я предполагаю, что вы хотите проверить влияние возраста на Present/Absent, Ключ для указания ответа типа (в псевдокоде) c(success, failure),
Таким образом, вам нужны данные, как data.frame(Age= ..., Present = ..., Absent), Самый простой способ сделать это из вашего example это транспонировать, а затем принуждать к data.frameи добавьте столбец:
example_t <- as.data.frame(t(example))
example_df <- data.frame(example_t, Age=factor(row.names(example_t)))
что дает вам
Present Absent Age
>= 55 21 6 >= 55
<55 22 51 <55
Затем вы можете запустить GLM:
glm(cbind(Present, Absent) ~ Age, example_df, family = 'binomial')
получить
Call: glm(formula = cbind(Present, Absent) ~ Age, family = "binomial",
data = example_for_glm)
Coefficients:
(Intercept) Age<55
1.253 -2.094
Degrees of Freedom: 1 Total (i.e. Null); 0 Residual
Null Deviance: 18.7
Residual Deviance: -1.332e-15 AIC: 11.99
добавление
Вы также можете получить ответ через @therimalaya. Но это только первый шаг
as.data.frame(as.table(example))
(только дает вам часть пути там)
Var1 Var2 Freq
1 Present >= 55 21
2 Absent >= 55 6
3 Present <55 22
4 Absent <55 51
но чтобы на самом деле иметь столбец успехов и неудач, нужно сделать что-то большее. Вы могли бы использовать tidyr попасть туда
as.data.frame(as.table(example)) %>% tidyr::spread(Var1, Freq)
похож на мой example_df выше
Var2 Present Absent
1 >= 55 21 6
2 <55 22 51