Разделение сообщений Кафки построчно в Spark структурированной потоковой передаче
Я хочу прочитать сообщение из темы Кафки в моей работе Spark Structured Streaming во фрейм данных. но я получаю все сообщение в одном смещении, поэтому в кадре данных только это сообщение входит в одну строку вместо нескольких строк. (в моем случае это 3 строки)
Когда я печатаю это сообщение, я получаю вывод ниже:
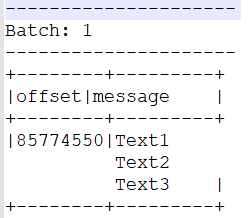
Сообщения "Text1", "Text2" и "Text3" я хочу в 3 строки в кадре данных, чтобы я мог обрабатывать дальше.
Пожалуйста, помогите мне.
1 ответ
Вы можете использовать пользовательскую функцию (UDF), чтобы преобразовать строку сообщения в последовательность строк, а затем применить функцию разнесения к этому столбцу, чтобы создать новую строку для каждого элемента в последовательности:
Как показано ниже (в Scala, тот же принцип применяется к pyspark):
case class KafkaMessage(offset: Long, message: String)
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.functions.explode
val df = sc.parallelize(List(KafkaMessage(1000, "Text1\nText2\nText3"))).toDF()
val splitString = udf { s: String => s.split('\n') }
df.withColumn("splitMsg", explode(splitString($"message")))
.select("offset", "splitMsg")
.show()
это даст следующий результат:
+------+--------+
|offset|splitMsg|
+------+--------+
| 1000| Text1|
| 1000| Text2|
| 1000| Text3|
+------+--------+