Как точно запланированы x86 мопы?
Современные процессоры x86 разбивают входящий поток команд на микрооперации (uops 1), а затем планируют эти мопы не по порядку, когда их входные данные становятся готовыми. Хотя основная идея ясна, я хотел бы знать конкретные детали того, как планируются готовые инструкции, поскольку это влияет на решения по микрооптимизации.
Например, возьмите следующий игрушечный цикл 2:
top:
lea eax, [ecx + 5]
popcnt eax, eax
add edi, eax
dec ecx
jnz top
это в основном реализует цикл (со следующим соответствием: eax -> total, c -> ecx):
do {
total += popcnt(c + 5);
} while (--c > 0);
Я знаком с процессом оптимизации любого маленького цикла, рассматривая разбивку по uop, задержки в цепочке зависимостей и так далее. В приведенном выше цикле у нас есть только одна переносимая цепочка зависимостей: dec ecx, Первые три инструкции цикла (lea, imul, add) являются частью цепочки зависимостей, которая начинает каждый цикл заново.
Финал dec а также jne слиты. Таким образом, мы имеем в общей сложности 4 мопа слитых доменов и одну цепочку зависимостей с циклом переноса с задержкой в 1 цикл. Исходя из этого критерия, кажется, что цикл может выполняться за 1 цикл / итерацию.
Тем не менее, мы должны посмотреть на давление порта:
-
leaможно выполнить на портах 1 и 5 - Popcnt может выполняться на порту 1
-
addможно выполнить на портах 0, 1, 5 и 6 - Предсказано-принято
jnzвыполняется на порту 6
Таким образом, чтобы перейти к 1 циклу / итерации, вам необходимо выполнить следующее:
- Popcnt должен выполняться на порту 1 (единственный порт, на котором он может выполняться)
-
leaдолжен выполняться на порту 5 (и никогда на порту 1) -
addдолжен выполняться на порту 0 и никогда на любом из трех других портов, на которых он может выполняться -
jnzв любом случае может выполняться только на 6 порту
Это много условий! Если бы инструкции были запланированы случайным образом, вы могли бы получить намного худшую пропускную способность. Например, 75% add будет идти в порт 1, 5 или 6, что приведет к задержке popcnt, lea или же jnz на один цикл. Аналогично для lea который может перейти на 2 порта, один из которых используется совместно с popcnt,
IACA, с другой стороны, сообщает о результате, очень близком к оптимальному, 1,05 цикла на итерацию:
Intel(R) Architecture Code Analyzer Version - 2.1
Analyzed File - l.o
Binary Format - 64Bit
Architecture - HSW
Analysis Type - Throughput
Throughput Analysis Report
--------------------------
Block Throughput: 1.05 Cycles Throughput Bottleneck: FrontEnd, Port0, Port1, Port5
Port Binding In Cycles Per Iteration:
---------------------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
---------------------------------------------------------------------------------------
| Cycles | 1.0 0.0 | 1.0 | 0.0 0.0 | 0.0 0.0 | 0.0 | 1.0 | 0.9 | 0.0 |
---------------------------------------------------------------------------------------
N - port number or number of cycles resource conflict caused delay, DV - Divider pipe (on port 0)
D - Data fetch pipe (on ports 2 and 3), CP - on a critical path
F - Macro Fusion with the previous instruction occurred
* - instruction micro-ops not bound to a port
^ - Micro Fusion happened
# - ESP Tracking sync uop was issued
@ - SSE instruction followed an AVX256 instruction, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 | |
---------------------------------------------------------------------------------
| 1 | | | | | | 1.0 | | | CP | lea eax, ptr [ecx+0x5]
| 1 | | 1.0 | | | | | | | CP | popcnt eax, eax
| 1 | 0.1 | | | | | 0.1 | 0.9 | | CP | add edi, eax
| 1 | 0.9 | | | | | | 0.1 | | CP | dec ecx
| 0F | | | | | | | | | | jnz 0xfffffffffffffff4
Это в значительной степени отражает необходимое "идеальное" планирование, о котором я упоминал выше, с небольшим отклонением: оно показывает add красть порт 5 от lea на 1 из 10 циклов. Он также не знает, что слитая ветвь собирается перейти на порт 6, так как это предсказано, как принято, поэтому он помещает большую часть мопов для ветви на порт 0, и большинство мопов для add на порту 6, а не наоборот.
Неясно, являются ли дополнительные 0,05 циклов, которые IACA сообщает оптимальными, результатом некоторого глубокого, точного анализа или менее проницательного следствия алгоритма, который он использует, например, анализ цикла по фиксированному числу циклов, или просто ошибка или что-то еще. То же самое касается 0,1 доли мопа, которая, по ее мнению, попадет в неидеальный порт. Также не ясно, объясняет ли одно другое - я думаю, что неправильное назначение порта 1 из 10 приведет к счету циклов 11/10 = 1,1 цикла на итерацию, но я не определил фактический нисходящий поток. результаты - может быть, влияние меньше в среднем. Или это может быть просто округление (0,05 == 0,1 до 1 десятичного знака).
Так как же на самом деле планируются современные процессоры x86? Особенно:
- Когда на станции резервирования будет готово несколько мопов, в каком порядке они запланированы для портов?
- Когда UOP может перейти на несколько портов (например,
addа такжеleaв приведенном выше примере), как определяется, какой порт выбран? - Если какой-либо из ответов включает в себя концепцию, подобную самой старой, для выбора среди мопов, как она определяется? Возраст с момента его доставки в РС? Возраст с тех пор, как он стал готов? Как нарушаются связи? Приходит ли когда-нибудь порядок программ?
Результаты на Skylake
Давайте измерим некоторые реальные результаты на Skylake, чтобы проверить, какие ответы объясняют экспериментальные данные, так что вот некоторые реальные результаты измерений (из perf) на моей коробке Skylake. Смущает, я собираюсь перейти на использование imul для моей инструкции "выполняется только на одном порту", так как она имеет много вариантов, в том числе версии с тремя аргументами, которые позволяют использовать разные регистры для источника и назначения. Это очень удобно при создании цепочек зависимостей. Это также позволяет избежать всей "неправильной зависимости от пункта назначения", popcnt есть.
Независимые инструкции
Давайте начнем с рассмотрения простого (?) Случая, когда инструкции относительно независимы - без каких-либо цепочек зависимостей, кроме тривиальных, таких как счетчик цикла.
Вот 4 моп петли (только 3 выполненных мопа) с умеренным давлением. Все инструкции независимы (не указывайте ни источники, ни пункты назначения). add может в принципе украсть p1 нужен imul или же p6 необходимо для dec:
Пример 1
instr p0 p1 p5 p6
xor (elim)
imul X
add X X X X
dec X
top:
xor r9, r9
add r8, rdx
imul rax, rbx, 5
dec esi
jnz top
The results is that this executes with perfect scheduling at 1.00 cycles / iteration:
560,709,974 uops_dispatched_port_port_0 ( +- 0.38% )
1,000,026,608 uops_dispatched_port_port_1 ( +- 0.00% )
439,324,609 uops_dispatched_port_port_5 ( +- 0.49% )
1,000,041,224 uops_dispatched_port_port_6 ( +- 0.00% )
5,000,000,110 instructions:u # 5.00 insns per cycle ( +- 0.00% )
1,000,281,902 cycles:u
( +- 0.00% )
Как и ожидалось, p1 а также p6 полностью используются imul а также dec/jnz соответственно, а затем add выдает примерно половину между оставшимися доступными портами. Обратите внимание примерно - фактическое соотношение составляет 56% и 44%, и это соотношение довольно стабильно во всех прогонах (обратите внимание на +- 0.49% вариации). Если я отрегулирую выравнивание петли, разделение изменится (53/46 для выравнивания 32B, больше похоже на 57/42 для выравнивания 32B+4). Теперь, если мы ничего не изменим, кроме позиции imul в петле:
Пример 2
top:
imul rax, rbx, 5
xor r9, r9
add r8, rdx
dec esi
jnz top
Потом вдруг p1 / p5 сплит составляет ровно 50%/50% с вариацией 0,00%:
500,025,758 uops_dispatched_port_port_0 ( +- 0.00% )
1,000,044,901 uops_dispatched_port_port_1 ( +- 0.00% )
500,038,070 uops_dispatched_port_port_5 ( +- 0.00% )
1,000,066,733 uops_dispatched_port_port_6 ( +- 0.00% )
5,000,000,439 instructions:u # 5.00 insns per cycle ( +- 0.00% )
1,000,439,396 cycles:u ( +- 0.01% )
Так что это уже интересно, но трудно сказать, что происходит. Возможно, точное поведение зависит от начальных условий при входе в цикл и чувствительно к упорядочению в цикле (например, потому что используются счетчики). Этот пример показывает, что происходит нечто большее, чем "случайное" или "глупое" планирование. В частности, если вы просто устраните imul Инструкция из цикла, вы получите следующее:
Пример 3
330,214,329 uops_dispatched_port_port_0 ( +- 0.40% )
314,012,342 uops_dispatched_port_port_1 ( +- 1.77% )
355,817,739 uops_dispatched_port_port_5 ( +- 1.21% )
1,000,034,653 uops_dispatched_port_port_6 ( +- 0.00% )
4,000,000,160 instructions:u # 4.00 insns per cycle ( +- 0.00% )
1,000,235,522 cycles:u ( +- 0.00% )
Здесь add в настоящее время примерно равномерно распределен среди p0, p1 а также p5 - поэтому наличие imul повлияло на add планирование: это было не просто следствием какого-то правила "избегать порта 1".
Обратите внимание, что общее давление порта составляет всего 3 моп / цикл, так как xor является идиомой обнуления и устраняется в переименователе. Давайте попробуем с максимальным давлением 4 моп. Я ожидаю, что любой механизм, задействованный выше, сможет идеально спланировать и это. Мы только меняем xor r9, r9 в xor r9, r10, так что это больше не идиома обнуления. Мы получаем следующие результаты:
Пример 4
top:
xor r9, r10
add r8, rdx
imul rax, rbx, 5
dec esi
jnz top
488,245,238 uops_dispatched_port_port_0 ( +- 0.50% )
1,241,118,197 uops_dispatched_port_port_1 ( +- 0.03% )
1,027,345,180 uops_dispatched_port_port_5 ( +- 0.28% )
1,243,743,312 uops_dispatched_port_port_6 ( +- 0.04% )
5,000,000,711 instructions:u # 2.66 insns per cycle ( +- 0.00% )
1,880,606,080 cycles:u ( +- 0.08% )
К сожалению! Вместо того, чтобы равномерно планировать все p0156, планировщик недоиспользован p0 (это только выполнение чего-то ~49% циклов), и, следовательно, p1 а также p6 переподписаны, потому что они выполняют оба своих необходимых операций imul а также dec/jnz, Такое поведение, я думаю, согласуется с показателем давления на основе счетчика, как указано в ответе hayesti, и с назначением мопов на порт во время выдачи, а не во время исполнения, как упоминали и hayesti, и Питер Кордес. Такое поведение 3 приводит к тому, что выполнение самого старого правила готовых мопов не так эффективно. Если бы мопы не были связаны с портами исполнения в вопросе, а скорее во время исполнения, то это "самое старое" правило решило бы проблему выше после одной итерации - один раз imul и один dec/jnz задержали на одну итерацию, они всегда будут старше конкурирующих xor а также add инструкции, поэтому всегда должны быть запланированы в первую очередь. Однако я узнал, что если порты назначаются во время выпуска, это правило не помогает, потому что порты предопределены во время выпуска. Я думаю, что это все еще немного помогает в одобрении инструкций, которые являются частью длинных цепочек зависимости (так как они будут иметь тенденцию отставать), но это не панацея, как я думал.
Это также, кажется, объясняет результаты выше: p0 получает больше давления, чем на самом деле, потому что dec/jnz комбо может в теории выполнить на p06, На самом деле, поскольку предсказано, что ветвь принята, она только p6, но, возможно, эта информация не может быть введена в алгоритм балансировки давления, поэтому счетчики имеют тенденцию видеть одинаковое давление на p016 Это означает, что add и xor распространяться по-разному, чем оптимально.
Вероятно, мы можем проверить это, развернув цикл немного, чтобы jnz это менее важный фактор...
1 Хорошо, это правильно написано μops, но это убивает возможность поиска и фактически вводит символ "μ", который я обычно прибегаю к копированию-вставке символа с веб-страницы.
2 я изначально использовал imul вместо popcnt в петле, но, невероятно, IACA не поддерживает это!
3 Обратите внимание, что я не утверждаю, что это плохой дизайн или что-то в этом роде - вероятно, существуют очень веские аппаратные причины, по которым планировщик не может легко принимать все свои решения во время выполнения.
3 ответа
Ваши вопросы сложны по нескольким причинам:
- Ответ во многом зависит от микроархитектуры процессора, которая может значительно варьироваться от поколения к поколению.
- Это мелкие детали, которые Intel обычно не публикует.
Тем не менее я постараюсь ответить...
Когда на станции резервирования будет готово несколько мопов, в каком порядке они запланированы для портов?
Это должен быть самый старый [см. Ниже], но ваш пробег может отличаться. Микроархитектура P6 (используемая в Pentium Pro, 2 и 3) использовала станцию резервирования с пятью планировщиками (по одному на порт исполнения); планировщики использовали указатель приоритета в качестве места для начала сканирования готовых мопов для отправки. Это был только псевдо FIFO, поэтому вполне возможно, что самая старая готовая инструкция не всегда была запланирована. В микроархитектуре NetBurst (используемой в Pentium 4) они отказались от единой станции резервирования и вместо этого использовали две очереди uop. Это были правильные очереди с приоритетом свертывания, поэтому планировщики гарантированно получили самую старую готовую инструкцию. Базовая архитектура вернулась на станцию резервирования, и я рискнул бы сделать обоснованное предположение, что они использовали сворачивающуюся очередь приоритетов, но я не могу найти источник, чтобы подтвердить это. Если у кого-то есть определенный ответ, я весь в ушах.
Когда UOP может перейти на несколько портов (например, add и lea в приведенном выше примере), как определяется, какой порт выбран?
Это сложно знать. Лучшее, что я смог найти, - это патент Intel, описывающий такой механизм. По сути, они хранят счетчик для каждого порта, который имеет избыточные функциональные блоки. Когда мопы покидают интерфейс на станцию бронирования, им назначается порт отправки. Если приходится выбирать между несколькими избыточными исполнительными блоками, счетчики используются для равномерного распределения работы. Счетчики увеличиваются и уменьшаются при входе и выходе из резервирования соответственно.
Естественно, это всего лишь эвристика и не гарантирует идеальное бесконфликтное расписание, однако, я все еще могу видеть, как оно работает на вашем игрушечном примере. Команды, которые могут идти только на один порт, в конечном итоге будут влиять на планировщик для отправки "менее ограниченных" мопов на другие порты.
В любом случае, наличие патента не обязательно означает, что идея была принята (хотя, тем не менее, один из авторов был также техническим руководителем Pentium 4, так кто знает?)
Если какой-либо из ответов включает в себя концепцию, подобную самой старой, для выбора среди мопов, как она определяется? Возраст с момента его доставки в РС? Возраст с тех пор, как он стал готов? Как нарушаются связи? Приходит ли когда-нибудь порядок программ?
Поскольку мопы вставляются в станцию резервирования по порядку, самое старое здесь действительно относится ко времени, когда оно вошло в станцию резервирования, то есть самое старое в программном порядке.
Кстати, я бы взял эти результаты IACA с небольшим количеством соли, поскольку они могут не отражать нюансы реального оборудования. В Haswell есть аппаратный счетчик, называемый uops_executed_port, который может сообщить вам, сколько циклов в вашем потоке было проблем с Uops для портов 0-7. Может быть, вы могли бы использовать их, чтобы лучше понять вашу программу?
Вот то, что я нашел на Skylake, исходя из того, что мопы назначаются портам во время выдачи (т. Е. Когда они выдаются в RS), а не во время отправки (т. Е. В момент, когда они отправляются на выполнение), Прежде чем я понял, что решение о порте было принято во время отправки.
Я сделал множество тестов, которые пытались выделить последовательности add операции, которые могут пойти на p0156 а также imul операции, которые идут только на порт 0. Типичный тест идет примерно так:
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
... many more mov instructions
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
imul ebx, ebx, 1
imul ebx, ebx, 1
imul ebx, ebx, 1
imul ebx, ebx, 1
add r9, 1
add r8, 1
add ecx, 1
add edx, 1
add r9, 1
add r8, 1
add ecx, 1
add edx, 1
add r9, 1
add r8, 1
add ecx, 1
add edx, 1
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
... many more mov instructions
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
В основном, есть долгое введение mov eax, [edi] инструкции, которые выдаются только на p23 и, следовательно, не забивайте порты, используемые инструкциями (я мог бы также использовать nop инструкции, но тест будет немного другим, так как nop не выдайте в РС). Далее следует раздел "Полезная нагрузка", состоящий из 4 imul и 12 add, а затем выводной раздел более пустышка mov инструкции.
Во-первых, давайте посмотрим на патент, который hayesti связал выше, и о котором он описывает основную идею: счетчики для каждого порта, которые отслеживают общее количество мопов, назначенных порту, которые используются для балансировки нагрузки назначений портов. Взгляните на эту таблицу, включенную в описание патента:
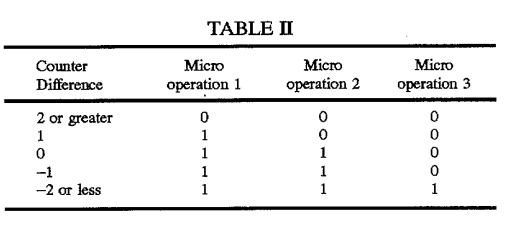
Эта таблица используется для выбора между p0 или же p1 для 3-мера в группе вопросов для 3-х сторонней архитектуры, обсуждаемой в патенте. Обратите внимание, что поведение зависит от положения мопа в группе, и что существует 4 правила1, основанные на подсчете, которые логически распределяют мопы вокруг. В частности, счет должен быть на уровне +/- 2 или выше, прежде чем всей группе будет назначен недостаточно используемый порт.
Давайте посмотрим, можем ли мы наблюдать, как "положение в группе вопросов" имеет значение для поведения на Склейке. Мы используем полезную нагрузку одного add лайк:
add edx, 1 ; position 0
mov eax, [edi]
mov eax, [edi]
mov eax, [edi]
... и мы перемещаем его внутри 4-х инструкционного патрона как:
mov eax, [edi]
add edx, 1 ; position 1
mov eax, [edi]
mov eax, [edi]
... и так далее, тестирование всех четырех позиций в группе вопросов2. Это показывает следующее, когда RS заполнен (из mov инструкции), но без давления порта любого из соответствующих портов:
- Первый
addинструкции идут кp5или жеp6с выбранным портом, обычно чередующимся, поскольку команда замедляется (т.е.addинструкции в четных позицияхp5и в нечетных позицияхp6). - Второй
addинструкция также идет кp56- Который из двух первым не пошел. - После этого дальше
addинструкции начинают уравновешиватьсяp0156, сp5а такжеp6обычно впереди, но с вещами довольно даже в целом (то есть, разрыв междуp56а два других порта не растут).
Далее я посмотрел, что произойдет, если загрузить p1 с imul операции, затем сначала в кучу add операции:
imul ebx, ebx, 1
imul ebx, ebx, 1
imul ebx, ebx, 1
imul ebx, ebx, 1
add r9, 1
add r8, 1
add ecx, 1
add edx, 1
add r9, 1
add r8, 1
add ecx, 1
add edx, 1
add r9, 1
add r8, 1
add ecx, 1
add edx, 1
Результаты показывают, что планировщик справляется с этим хорошо - все imul добрался до запланированного p1 (как и ожидалось), а затем ни один из последующих add инструкции пошли к p1, распространяясь вокруг p056 вместо. Так что здесь планирование работает хорошо.
Конечно, когда ситуация обратная, и серия imul приходит после adds, p1 загружается со своей долей добавлений до imulхитом Это является результатом назначения портов, происходящего по порядку во время выпуска, так как нет механизма, чтобы "смотреть в будущее" и видеть imul при планировании adds.
В целом, планировщик выглядит хорошо в этих тестовых случаях.
Это не объясняет, что происходит в меньших, более плотных циклах, таких как:
sub r9, 1
sub r10, 1
imul ebx, edx, 1
dec ecx
jnz top
Как и в примере 4 в моем вопросе, этот цикл только заполняет p0 на ~30% циклов, несмотря на наличие двух sub инструкции, которые должны быть в состоянии перейти к p0 на каждом цикле. p1 а также p6 переподписаны, каждый выполняя 1.24 мопов за каждую итерацию (1 идеально). Я не смог триангулировать разницу между примерами, которые хорошо работают в верхней части этого ответа, с плохими циклами - но есть еще много идей, которые можно попробовать.
Я заметил, что примеры без различий в задержке инструкций, похоже, не страдают от этой проблемы. Например, вот еще один 4-х контурный цикл со "сложным" давлением на порт:
top:
sub r8, 1
ror r11, 2
bswap eax
dec ecx
jnz top
Карта UOP выглядит следующим образом:
instr p0 p1 p5 p6
sub X X X X
ror X X
bswap X X
dec/jnz X
Итак sub всегда должен идти к p15, поделился с bswap если что-то получится. Они делают:
Статистика счетчика производительности для "./sched-test2" (2 прогона):
999,709,142 uops_dispatched_port_port_0 ( +- 0.00% )
999,675,324 uops_dispatched_port_port_1 ( +- 0.00% )
999,772,564 uops_dispatched_port_port_5 ( +- 0.00% )
1,000,991,020 uops_dispatched_port_port_6 ( +- 0.00% )
4,000,238,468 uops_issued_any ( +- 0.00% )
5,000,000,117 instructions:u # 4.99 insns per cycle ( +- 0.00% )
1,001,268,722 cycles:u ( +- 0.00% )
Таким образом, кажется, что проблема может быть связана с задержками инструкций (конечно, между примерами есть и другие различия). Это то, что возникло в этом похожем вопросе.
1 В таблице 5 правил, но правила для счетчиков 0 и -1 идентичны.
2 Конечно, я не могу быть уверен, где начинаются и заканчиваются группы вопросов, но независимо от того, как мы тестируем четыре разные позиции, когда скатываемся вниз по четырем инструкциям (но метки могут быть неправильными). Я также не уверен, что максимальный размер группы проблем равен 4 - более ранние части конвейера шире - но я верю, что это так, и некоторые тесты, казалось, показали, что это так (циклы с кратным числом 4 мопов показали согласованное поведение планирования). В любом случае выводы верны при разных размерах групп планирования.
Раздел 2.12 книги « Точное прогнозирование пропускной способности базовых блоков в новейших микроархитектурах Intel» [^1] объясняет, как назначаются порты, но не объясняет пример 4 в описании вопроса. Мне также не удалось выяснить, какую роль Latency играет в назначении портов.
В предыдущей работе [19, 25, 26] были определены порты, которые могут использовать микрооперации отдельных инструкций. Однако для микроопераций, которые могут использовать более одного порта, ранее было неизвестно, как фактический порт выбирается процессором. Мы перепроектировали алгоритм назначения портов с помощью микробенчмарков. Далее мы опишем наши результаты для процессоров с восемью портами; такие ЦП в настоящее время наиболее широко используются.
Порты назначаются, когда переименовщик выдает планировщику µops. За один цикл может быть выдано до четырех микроопераций. В дальнейшем мы будем называть положение микрооперации внутри цикла слотом задачи; например, самая старая инструкция, выданная в цикле, будет занимать слот выдачи 0.
Порт, назначаемый µop, зависит от слота его выдачи и от портов, назначенных µop, которые не были выполнены и были выпущены в предыдущем цикле.
Далее мы будем рассматривать только микрооперации, которые могут использовать более одного порта. Для данной µop m пусть $P_{min}$ будет портом, которому назначено наименьшее количество невыполненных µop из числа портов, которые может использовать m. Пусть $P_{min'}$ будет портом со вторым наименьшим использованием на данный момент. Если среди портов с наименьшим (или вторым наименьшим, соответственно) использованием есть ничья, пусть $P_{min}$ (или $P_{min'}$) будет портом с наибольшим номером порта среди этих портов ( причина такого выбора, вероятно, в том, что порты с более высокими номерами подключены к меньшему количеству функциональных блоков). Если разница между $P_{min}$ и $P_{min'}$ больше или равна 3, мы устанавливаем $P_{min'}$ равным $P_{min}$.
Микрооперации в слотах задач 0 и 2 назначаются порту $P_{min}$. Микрооперации в слотах задач 1 и 3 назначаются порту $P_{min'}$.
Особым случаем являются микрооперации, которые могут использовать порт 2 и порт 3. Эти порты используются микрооперациями, обрабатывающими доступ к памяти, и оба порта подключены к функциональным блокам одного типа. Для таких микроопераций алгоритм назначения портов чередуется между портом 2 и портом 3.
Я попытался выяснить, распределяются ли $P_{min}$ и $P_{min'}$ между потоками (Hyper-Threading), а именно может ли один поток влиять на назначение портов другого в том же ядре.
Просто разделите код, используемый в ответе BeeOnRope, на два потока.
thread1:
.loop:
imul rax, rbx, 5
jmp .loop
thread2:
mov esi,1000000000
.top:
bswap eax
dec esi
jnz .top
jmp thread2
Где инструкции могут быть выполнены на портах 1 и 5, и
Эксперимент был записан следующим образом, где порты P0 и P5 на потоке 1 и p0 на потоке 2 должны были записывать небольшое количество непользовательских данных, но не мешая выводу. Из данных видно, что
Поэтому счетчики не распределяются между потоками.
Этот вывод не противоречит SMotherSpectre[^2], который использует время в качестве побочного канала. (Например, поток 2 дольше ожидает на порту 1, чтобы использовать порт 1.)
Выполнение инструкций, занимающих определенный порт, и измерение времени их выполнения позволяет сделать вывод о других инструкциях, выполняемых на том же порту. Сначала мы выбираем две инструкции, каждая из которых запланирована на один отдельный порт выполнения. Один поток выполняет и отсчитывает длинную последовательность одиночных инструкций микроопераций, запланированных для порта a, в то время как другой поток одновременно выполняет длинную последовательность инструкций, запланированных для порта b. Мы ожидаем, что если a = b, возникнет конкуренция и измеренное время выполнения будет больше по сравнению со случаем a ≠ b.
[^1]: Абель, Андреас и Ян Райнеке. «Точное прогнозирование пропускной способности базовых блоков в новейших микроархитектурах Intel». Препринт arXiv arXiv:2107.14210 (2021 г.).
[^2]: Бхаттачарья, Атри, Александра Сандулеску, Матиас Нойгшвандтнер, Алессандро Сорниотти, Бабак Фалсафи, Матиас Пайер и Анил Курмус. «SMoTherSpectre: использование спекулятивного исполнения через конкуренцию за порт». Материалы конференции ACM SIGSAC 2019 г. по компьютерной и коммуникационной безопасности, 6 ноября 2019 г., стр. 785–800. https://doi.org/10.1145/3319535.3363194.