Использование инструкций процессора AVX: низкая производительность без "/arch:AVX"
Мой код на C++ использует SSE, и теперь я хочу улучшить его для поддержки AVX, когда он будет доступен. Поэтому я определяю, когда доступен AVX, и вызываю функцию, которая использует команды AVX. Я использую Win7 SP1 + VS2010 SP1 и процессор с AVX.
Чтобы использовать AVX, необходимо включить это:
#include "immintrin.h"
и тогда вы можете использовать встроенные функции AVX, такие как _mm256_mul_ps, _mm256_add_ps и т.д. Проблема в том, что по умолчанию VS2010 создает код, который работает очень медленно и отображает предупреждение:
предупреждение C4752: обнаружены расширенные векторные расширения Intel(R); рассмотрите возможность использования /arch:AVX
Кажется, VS2010 на самом деле не использует инструкции AVX, а эмулирует их. я добавил /arch:AVX к настройкам компилятора и получил хорошие результаты. Но эта опция говорит компилятору использовать команды AVX везде, где это возможно. Так что мой код может зависнуть на процессоре, который не поддерживает AVX!
Таким образом, вопрос заключается в том, как заставить компилятор VS2010 генерировать код AVX, но только тогда, когда я непосредственно указываю встроенные функции AVX. Для SSE это работает, я просто использую встроенные функции SSE и создаю код SSE без каких-либо опций компилятора, таких как /arch:SSE, Но для AVX это не работает по некоторым причинам.
3 ответа
Поведение, которое вы видите, является результатом дорогостоящего переключения состояний.
См. Стр. 102 руководства Agner Fog:
http://www.agner.org/optimize/microarchitecture.pdf
Каждый раз, когда вы неправильно переключаетесь между инструкциями SSE и AVX, вы будете платить очень высокий (~70) штраф за цикл.
Когда вы компилируете без /arch:AVX, VS2010 будет генерировать инструкции SSE, но все равно будет использовать AVX везде, где есть встроенные AVX. Следовательно, вы получите код, содержащий инструкции SSE и AVX, которые будут содержать эти штрафы за переключение состояний. (VS2010 это знает, поэтому выдает предупреждение, которое вы видите.)
Поэтому вы должны использовать либо все SSE, либо все AVX. Определение /arch:AVX говорит компилятору использовать все AVX.
Похоже, вы пытаетесь создать несколько путей кода: один для SSE, а другой для AVX. Для этого я предлагаю вам разделить код SSE и AVX на два разных модуля компиляции. (один составлен с /arch:AVX и один без) Затем свяжите их вместе и сделайте диспетчер для выбора на основе того, на каком оборудовании он работает.
Если вам нужно смешать SSE и AVX, обязательно используйте _mm256_zeroupper() или же _mm256_zeroall() соответственно, чтобы избежать штрафов за переключение состояний.
ТЛ; др
использование _mm256_zeroupper(); или же _mm256_zeroall(); вокруг разделов кода с использованием AVX (до или после в зависимости от аргументов функции). Использовать только вариант /arch:AVX для исходных файлов с AVX, а не для всего проекта, чтобы избежать нарушения поддержки устаревших кодированных путей только для SSE.
причина
Я думаю, что лучшее объяснение можно найти в статье Intel "Избегание штрафов за переход AVX-SSE" ( PDF). Аннотация гласит:
Переход между 256-битными инструкциями Intel® AVX и унаследованными инструкциями Intel® SSE в программе может привести к снижению производительности, поскольку аппаратное обеспечение должно сохранять и восстанавливать старшие 128 битов регистров YMM.
Разделение кода AVX и SSE на разные блоки компиляции НЕ может помочь, если вы переключаетесь между вызывающим кодом как из объектных файлов с поддержкой SSE, так и с поддержкой AVX, поскольку переход может произойти, когда инструкции или сборка AVX смешаны с любым из (от Intel бумага):
- 128-битные внутренние инструкции
- Встроенная сборка SSE
- Код C/C++ с плавающей запятой, скомпилированный в Intel® SSE
- Вызовы функций или библиотек, которые включают в себя любое из перечисленного
Это означает, что могут быть даже штрафы за соединение с внешним кодом с использованием SSE.
подробности
Существует три состояния процессора, определенные в инструкциях AVX, и одно из состояний состоит в том, где все регистры YMM разделены, что позволяет использовать нижнюю половину командами SSE. Документ Intel " Переходы состояний Intel® AVX: миграция кода SSE в AVX " содержит диаграмму этих состояний:
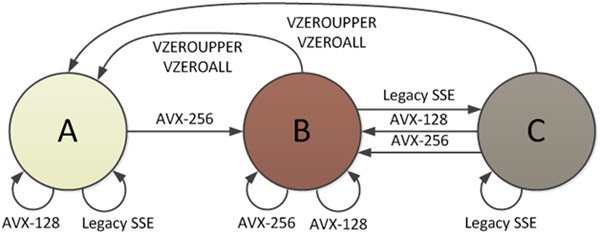
В состоянии B (режим AVX-256) все биты регистров YMM используются. Когда вызывается инструкция SSE, должен произойти переход в состояние C, и здесь есть штраф. Верхняя половина всех регистров YMM должна быть сохранена во внутреннем буфере до запуска SSE, даже если они оказались нулями. Стоимость переходов составляет порядка 50-80 тактов на оборудовании Sandy Bridge. Существует также штраф от C -> A, как показано на рисунке 2.
Вы также можете найти подробности о штрафе за переключение состояний, вызвавшем это замедление, на странице 130, Раздел 9.12, "Переходы между режимами VEX и не-VEX" в руководстве по оптимизации Agner Fog (версия обновлена 2014-08-07), на которое есть ссылка в ответе Mystical., Согласно его руководству, любой переход в / из этого состояния занимает "около 70 тактов на Песчаном мосту". Как говорится в документе Intel, это штраф за переход, которого можно избежать.
разрешение
Чтобы избежать штрафов за переход, вы можете либо удалить весь устаревший код SSE, дать указание компилятору преобразовать все инструкции SSE в их кодированную VEX форму 128-битных инструкций (если компилятор способен), либо перевести регистры YMM в известное нулевое состояние до того, как переход между AVX и SSE кодом. По сути, для поддержки отдельного пути кода SSE вы должны обнулить старшие 128 битов всех 16 регистров YMM (выпуская VZEROUPPER инструкция) после любого кода, который использует инструкции AVX. Обнуление этих битов вручную вызывает переход в состояние A и позволяет избежать дорогостоящего штрафа, так как значения YMM не нужно хранить во внутреннем буфере аппаратно. Встроенный, который выполняет эту инструкцию _mm256_zeroupper, Описание этой сущности очень информативно:
Эта встроенная функция полезна для очистки верхних битов регистров YMM при переходе между инструкциями Intel® Advanced Vector Extensions (Intel® AVX) и устаревшими инструкциями Intel® Supplemental SIMD Extensions (Intel® SSE). Там нет штрафов за переход, если приложение очищает старшие биты всех регистров YMM (устанавливается в "0") через
VZEROUPPERсоответствующая инструкция для этого встроенного, перед переходом между инструкциями Intel® Advanced Vector Extensions (Intel® AVX) и устаревшими инструкциями Intel® Supplemental SIMD Extensions (Intel® SSE).
В Visual Studio 2010+ (возможно, даже старше) вы получаете это с помощью immintrin.h.
Обратите внимание, что обнуление битов другими методами не устраняет штраф - VZEROUPPER или же VZEROALL инструкции должны быть использованы.
Одним из автоматических решений, реализованных Intel Compiler, является вставка VZEROUPPER в начале каждой функции, содержащей код Intel AVX, если ни один из аргументов не является регистром YMM или __m256 / __m256d / __m256i тип данных и в конце функции, если возвращаемое значение не является регистром YMM или __m256 / __m256d / __m256i тип данных.
В дикой природе
это VZEROUPPER Решение используется FFTW для создания библиотеки с поддержкой SSE и AVX. Смотрите simd-avx.h:
/* Use VZEROUPPER to avoid the penalty of switching from AVX to SSE.
See Intel Optimization Manual (April 2011, version 248966), Section
11.3 */
#define VLEAVE _mm256_zeroupper
затем VLEAVE(); вызывается в конце каждой функции, используя встроенные функции для инструкций AVX.
Обновление. Вставка последних компиляторов
vzeroupper автоматически, и вы не хотите добавлять его вручную через
_mm256_zeroupper, поскольку компилятор может видеть, когда его можно оптимизировать (после встраивания функции AVX в функцию AVX)
См. Раздел « Нужно ли мне использовать _mm256_zeroupper в 2021 году?»