Что является более производительным: <= 0 или <1?
В тот день, когда я изучал C и сборку, нас учили, что для увеличения скорости лучше использовать простые сравнения. Так, например, если вы говорите:
if(x <= 0)
против
if(x < 1)
который будет выполняться быстрее? Мой аргумент (который может быть неправильным) заключается в том, что второй почти всегда будет выполняться быстрее, поскольку выполняется только одно сравнение), т. Е. Меньше одного, да или нет.
Принимая во внимание, что первое будет выполняться быстро, если число меньше 0, потому что это равно true, нет необходимости проверять равенство, делая его так же быстро, как второе, однако, оно всегда будет медленнее, если число равно 0 или больше, потому что оно Затем нужно сделать второе сравнение, чтобы увидеть, равно ли оно 0.
Сейчас я использую C#, и хотя разработка для настольных ПК не является проблемой (по крайней мере, в той степени, в которой его аргумент стоит спорить), я все же думаю, что такие аргументы необходимо учитывать, так как я разрабатываю и для мобильных устройств, которые очень менее мощные, чем настольные компьютеры, и скорость становится проблемой на таких устройствах.
Для дальнейшего рассмотрения я говорю о целых числах (без десятичных дробей) и числах, где не может быть отрицательного числа, такого как -1 или -12,345 и т. Д. (Если нет ошибки), например, при работе со списками или массивами, когда вы не можете иметь отрицательное количество элементов, но вы хотите проверить, является ли список пустым (или, если есть проблема, установите значение x в отрицательное значение, чтобы указать на ошибку, например, в списке есть некоторые элементы, но вы не можете по какой-то причине получить весь список и указать это, чтобы установить отрицательное число, которое не будет совпадать с сообщением об отсутствии элементов).
По вышеуказанной причине я сознательно не учел очевидное
if(x == 0)
а также
if(x.isnullorempty())
и другие подобные предметы для обнаружения списка без предметов.
Опять же, для рассмотрения мы говорим о возможности извлечения элементов из базы данных, возможно, с использованием хранимых процедур SQL, которые имеют упомянутую функциональность (т. Е. Стандарт (по крайней мере, в этой компании) - возвращать отрицательное число, чтобы указать на проблему).
Так что в таких случаях лучше использовать первый или второй пункт выше?
9 ответов
Они идентичны. Ни один не быстрее, чем другой. Они оба задают один и тот же вопрос, предполагая, x является целым числом C# не является сборкой. Вы просите компилятор сгенерировать лучший код, чтобы получить желаемый эффект. Вы не указываете, как он получает этот результат.
Смотрите также этот ответ.
Мой аргумент (который может быть неправильным) заключается в том, что второй почти всегда будет выполняться быстрее, поскольку выполняется только одно сравнение), т. Е. Меньше одного, да или нет.
Очевидно, что это неправильно. Посмотрите, что произойдет, если вы предполагаете, что это правда:
< быстрее чем <= потому что он задает меньше вопросов. (Ваш аргумент.)
> та же скорость, что и <= потому что он задает тот же вопрос, только с перевернутым ответом.
таким образом < быстрее чем >! Но этот же аргумент показывает > быстрее чем <,
"просто с перевернутым ответом", кажется, крадется в дополнительной логической операции, поэтому я не уверен, что следую этому ответу.
Это неправильно (для кремния это иногда правильно для программного обеспечения) по той же причине. Рассматривать:
3 != 4 дороже вычислить, чем 3 == 4, потому что это 3 != 4 с перевернутым ответом, дополнительная логическая операция.
3 == 4 дороже, чем 3 != 4, потому что это 3 != 4 с перевернутым ответом, дополнительная логическая операция.
Таким образом, 3 != 4 дороже, чем сам.
Перевернутый ответ - только противоположный вопрос, а не дополнительная логическая операция. Или, если быть более точным, это сопоставление результатов сравнения с окончательным ответом. И то и другое 3 == 4 а также 3 != 4 потребуйте, чтобы вы сравнили 3 и 4. Это сравнение приводит к тому, что эфир "равно" или "неравен". Вопросы просто сопоставляют "равный" и "неравный" с "истинным" и "ложным" по-разному. Ни одно отображение не является более дорогим, чем другое.
По крайней мере, в большинстве случаев нет, одно преимущество перед другим.
<= обычно не реализуется как два отдельных сравнения. На типичном (например, x86) процессоре у вас будет два отдельных флага, один для обозначения равенства, а другой для отрицательного (что также может означать "меньше чем"). Наряду с этим у вас будут ветви, которые зависят от комбинации этих флагов, поэтому < переводит на jl или же jb (переходите, если меньше, или переходите, если ниже - первый предназначен для чисел со знаком, второй для неподписанных). <= будет переводить на jle или же jbe (прыгать, если меньше или равно, прыгать, если меньше или равно).
Различные процессоры будут использовать разные имена / мнемонику для инструкций, но у большинства все еще есть эквивалентные инструкции. В каждом случае, о котором я знаю, все они выполняются с одинаковой скоростью.
Изменить: Упс - я хотел упомянуть одно возможное исключение из общего правила, которое я упомянул выше. Хотя это не совсем из < против <=, если / когда вы можете сравнить с 0 вместо любого другого числа вы можете иногда получить небольшое (незначительное) преимущество. Например, давайте предположим, что у вас была переменная, которую вы собирались отсчитывать, пока не достигли некоторого минимума. В таком случае вы могли бы получить небольшое преимущество, если бы вы могли считать до 0, а не до 1. Причина довольно проста: на упомянутые выше флаги влияет большинство инструкций. Давайте предположим, что у вас было что-то вроде:
do {
// whatever
} while (--i >= 1);
Компилятор может перевести это что-то вроде:
loop_top:
; whatever
dec i
cmp i, 1
jge loop_top
Если вместо этого вы сравниваете с 0 (while (--i > 0) или же while (--i != 0)), это может привести к чему-то вроде этого;
loop_top:
; whatever
dec i
jg loop_top
; or: jnz loop_top
Здесь dec устанавливает / сбрасывает флаг нуля, чтобы указать, был ли результат уменьшения нулевым или нет, поэтому условие может быть основано непосредственно на результате из dec, устраняя cmp используется в другом коде.
Я должен добавить, однако, что, хотя это было довольно эффективно, скажем, 30+ лет назад, большинство современных компиляторов могут обрабатывать подобные переводы без вашей помощи (хотя некоторые компиляторы могут этого не делать, особенно для таких вещей, как небольшие встроенные системы). Итак, если вам небезразлична оптимизация в целом, то вряд ли вы когда-нибудь позаботитесь об этом, но, по крайней мере, мне кажется, что приложение на C# в лучшем случае кажется сомнительным.
В большинстве современных аппаратных средств есть встроенные инструкции для проверки выражения " меньше или равно" в одной инструкции, которая выполняется точно так же быстро, как и та, которая проверяет условие " меньше". Аргумент, который применялся к (намного) более старому оборудованию, больше не применим - выберите тот вариант, который вы считаете наиболее читабельным, то есть тот, который лучше передает вашу идею читателям вашего кода.
Вот мои функции:
public static void TestOne()
{
Boolean result;
Int32 i = 2;
for (Int32 j = 0; j < 1000000000; ++j)
result = (i < 1);
}
public static void TestTwo()
{
Boolean result;
Int32 i = 2;
for (Int32 j = 0; j < 1000000000; ++j)
result = (i <= 0);
}
Вот код IL, который идентичен:
L_0000: ldc.i4.2
L_0001: stloc.0
L_0002: ldc.i4.0
L_0003: stloc.1
L_0004: br.s L_000a
L_0006: ldloc.1
L_0007: ldc.i4.1
L_0008: add
L_0009: stloc.1
L_000a: ldloc.1
L_000b: ldc.i4 1000000000
L_0010: blt.s L_0006
L_0012: ret
Очевидно, что после нескольких сеансов тестирования ни один из них не быстрее другого. Разница состоит только в нескольких миллисекундах, которые нельзя считать реальной разницей, и произведенный выход IL в любом случае одинаков.
И у процессоров ARM, и у x86 будут специальные инструкции как "меньше", так и "меньше или равно" (которые также могут быть оценены как "НЕ больше, чем"), поэтому не будет абсолютно никакой разницы в реальном мире, если вы используете какой-либо полу современный компилятор.
Во время рефакторинга, если вы передумаете о логике, if(x<=0) быстрее (и менее подвержен ошибкам) отрицать (т.е. if(!(x<=0)), по сравнению с if(!(x<1)) что не отрицает правильно) но это, вероятно, не та производительность, на которую вы ссылаетесь.;-)
ЕСЛИ x<1 быстрее, тогда изменятся современные компиляторы x<=0 в x<1 (при условии, x является интегралом). Поэтому для современных компиляторов это не должно иметь значения, и они должны генерировать идентичный машинный код.
Даже если x<=0 скомпилировано с инструкциями, отличными от x<1, разница в производительности будет настолько незначительной, что в большинстве случаев не стоит беспокоиться; Скорее всего, в вашем коде будут другие более продуктивные области для оптимизации. Золотое правило состоит в том, чтобы профилировать ваш код и оптимизировать биты, которые на самом деле медленны в реальном мире, а не биты, которые, как вы думаете, гипотетически могут быть медленными или не такими быстрыми, как теоретически. Также сконцентрируйтесь на том, чтобы сделать ваш код читаемым для других, а не на фантомных микрооптимизациях, которые исчезают в клубе дыма компилятора.
@Francis Rodgers, вы сказали:
Принимая во внимание, что первое будет выполняться быстро, если число меньше 0, потому что это равно true, нет необходимости проверять равенство, делая его так же быстро, как второе, однако, оно всегда будет медленнее, если число равно 0 или больше, потому что оно Затем нужно сделать второе сравнение, чтобы увидеть, равно ли оно 0.
и (в комментариях),
Можете ли вы объяснить, где> совпадает с <=, потому что это не имеет смысла в моем логическом мире. Например, <=0 - это не то же самое, что>0, фактически полностью противоположно. Мне просто нужен пример, чтобы я мог лучше понять ваш ответ
Вы просите о помощи, и вам нужна помощь. Я действительно хочу помочь вам, и я боюсь, что многим другим эта помощь тоже нужна.
Начните с более простой вещи. Ваша идея, что тестирование для> не то же самое, что тестирование для <=, логически неверна (не только на любом языке программирования). Посмотрите на эти диаграммы, расслабьтесь и подумайте об этом. Что произойдет, если вы знаете, что X <= Y в A и B? Что произойдет, если вы знаете, что X > Y на каждой диаграмме? 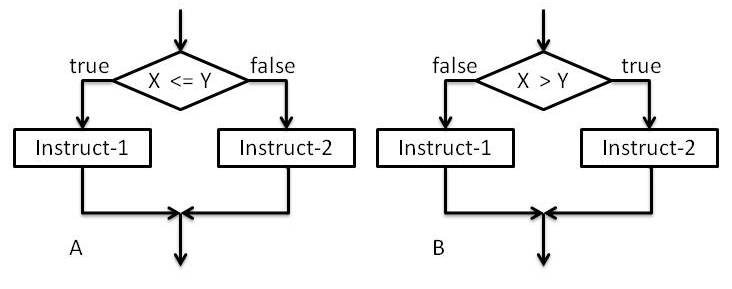 Правильно, ничего не изменилось, они эквивалентны. Ключевая деталь диаграмм в том, что
Правильно, ничего не изменилось, они эквивалентны. Ключевая деталь диаграмм в том, что true а также false в A и B находятся на противоположных сторонах. Смысл этого в том, что компилятор (или вообще-де-кодер) имеет свободу реорганизовать поток программы таким образом, что оба вопроса эквивалентны. Это означает, что нет необходимости разбивать <= на два шага, только реорганизовать немного в вашем потоке. Только очень плохой компилятор или интерпретатор не сможет сделать это. Ничего общего с ассемблером. Идея состоит в том, что даже для процессоров без достаточных флагов для всех сравнений компилятор может генерировать (псевдо) ассемблерный код с использованием теста с наилучшими характеристиками. Но добавив возможность процессорам проверять более одного флага параллельно на электронном уровне, работа компилятора значительно упрощается. Вам может быть интересно / интересно почитать страницы с 3-14 по 3-15 и с 5-3 по 5-5 (последняя включает инструкции по переходу с, может вас удивить) http://download.intel.com/products/processor/manual/325462.pdf
Во всяком случае, я хотел бы обсудить больше о связанных ситуациях.
Сравнение с 0 или с 1: @Jerry Coffin дает очень хорошее объяснение на уровне ассемблера. Если углубиться на уровне машинного кода, то вариант для сравнения с 1 должен "жестко закодировать" 1 в инструкции ЦП и загрузить его в ЦП, тогда как другому варианту это не удалось. Во всяком случае, здесь выгода абсолютно мала. Я не думаю, что это будет измеримо по скорости в любой реальной ситуации. Как побочный комментарий, инструкция cmp i, 1 будет сделано только своего рода вычитаниеi-1 (без сохранения результата), но устанавливая флаги, и вы в конечном итоге фактически сравниваете с 0!!
Более важной может быть такая ситуация: сравнить X<=Y или же Y>=X с очевидно логически эквивалентны, но это может иметь серьезный побочный эффект, если X а также Y Выражение необходимо оценивать и может повлиять на результат другого! Все еще очень плохо и потенциально не определено.
Теперь вернемся к диаграммам и рассмотрим примеры на ассемблере от @Jerry Coffin. Я вижу здесь следующую проблему. Настоящее программное обеспечение - это своего рода линейная цепочка в памяти. Вы выбираете одно из условий и переходите в другую позицию программной памяти, чтобы продолжить, в то время как обратное просто продолжается. Возможно, имеет смысл выбрать более частое условие, которое будет просто продолжаться. Я не понимаю, как мы можем дать подсказку компилятору в этих ситуациях, и, очевидно, компилятор не может понять это сам. Пожалуйста, поправьте меня, если я ошибаюсь, но такого рода проблемы с оптимизацией носят в основном общий характер, и программист должен решать сам без помощи компилятора.
Но опять же, в любой быстрой ситуации я напишу свой код, глядя на общую неподвижность и читабельность, а не на эти локальные небольшие оптимизации.