iconv не завершен конвертировать в utf8
Когда я конвертировал свой текст на этом сайте, он будет конвертирован правильно:
http://string-functions.com/encodedecode.aspx
Я выбираю источник 'Windows-1252' и цель 'utf-8'.
Посмотрите на скриншот ниже:
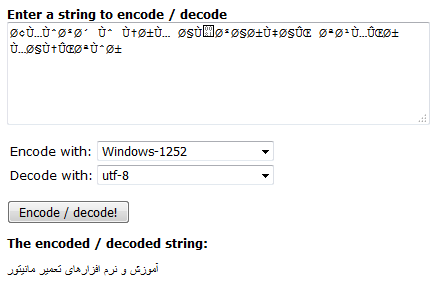
Но когда я конвертирую с помощью следующего кода, некоторые буквы не конвертируются, а текст прерывается.
iconv -c -f UTF-8 -t WINDOWS-1252 < mytext.txt > fixed_mytext.txt
Фраза, которая должна быть преобразована:
آموزش Ùˆ نرم اÙزارهای تعمیر مانیتور
Если true, то конвертируйте эту фразу:
آموزش و نرم افزارهای تعمیر مانیتور
Пожалуйста, помогите мне. благодарю вас
мой оригинальный текст:
http://www.todaymagazine.ir/forum.txt
1 ответ
Оригинальный текст был в UTF-8. Он был по ошибке интерпретирован как текст в Windows-1252 и преобразован из Windows-1252 в UTF-8. Это никогда не должно было быть сделано. Чтобы устранить ущерб, нам нужно преобразовать файл из UTF-8 в Windows-1252, а затем просто обработать его как файл UTF-8.
Однако есть проблема. Буква ف кодируется в UTF-8 как 0xd9 0x81и код 0x81 не является частью Windows1252.
К счастью, когда было совершено первое ошибочное преобразование, персонаж не был потерян или заменен знаком вопроса. Он был преобразован в контрольного персонажа 0xc2 0x81,
0xd9 код в Windows1252, это буква Ùкоторый в UTF-8 есть 0xc3 0x99, Таким образом, последняя последовательность байтов для ف в преобразованном файле 0xc3 0x99 0xc2 0x81,
Мы можем просто заменить на что-то ASCII-дружественное с sed сценарий, сделайте обратное преобразование, а затем замените его обратно на ف.
LANG=C sed $'s/\xc3\x99\xc2\x81/===FE===/g' forum.txt | \
iconv -f utf8 -t cp1252 | \
sed $'s/===FE===/\xd9\x81/g'
В результате получается оригинальный файл в кодировке UTF-8.
(удостоверься что ===FE=== не используется в тексте первым!)