Что такое индекс в SQL?
Что такое индекс в SQL? Можете ли вы объяснить или ссылку, чтобы понять ясно?
Где я должен использовать индекс?
14 ответов
Индекс используется для ускорения поиска в базе данных. В MySQL есть хорошая документация по этому вопросу (которая актуальна и для других серверов SQL): http://dev.mysql.com/doc/refman/5.0/en/mysql-indexes.html
Индекс можно использовать для эффективного поиска всех строк, соответствующих некоторому столбцу в вашем запросе, а затем просматривать только это подмножество таблицы, чтобы найти точные совпадения. Если у вас нет индексов ни в одном столбце WHERE оговорка SQL Сервер должен пройти всю таблицу и проверить каждую строку, чтобы увидеть, соответствует ли она, что может быть медленной операцией на больших таблицах.
Индекс также может быть UNIQUE индекс, что означает, что вы не можете иметь повторяющиеся значения в этом столбце, или PRIMARY KEY который в некоторых механизмах хранения определяет, где в файле базы данных хранится значение.
В MySQL вы можете использовать EXPLAIN перед вашим SELECT заявление, чтобы увидеть, будет ли ваш запрос использовать какой-либо индекс. Это хорошее начало для устранения проблем с производительностью. Подробнее читайте здесь: http://dev.mysql.com/doc/refman/5.0/en/explain.html
Кластерный индекс похож на содержание телефонной книги. Вы можете открыть книгу в "Хильдич, Дэвид" и найти всю информацию обо всех "Хильдичах" рядом друг с другом. Здесь ключи для кластеризованного индекса (фамилия, имя).
Это делает кластерные индексы отличными для получения большого количества данных на основе запросов на основе диапазона, поскольку все данные расположены рядом друг с другом.
Поскольку кластеризованный индекс на самом деле связан с тем, как хранятся данные, для каждой таблицы возможен только один из них (хотя вы можете использовать мошенничество для имитации нескольких кластеризованных индексов).
Некластеризованный индекс отличается тем, что их может быть много, и они затем указывают на данные в кластерном индексе. Например, у вас может быть некластеризованный индекс в конце телефонной книги, на котором указана (город, адрес)
Представьте себе, если бы вам пришлось искать в телефонной книге всех людей, которые живут в "Лондоне" - только с кластеризованным индексом, вам пришлось бы искать каждый элемент в телефонной книге, так как ключ в кластерном индексе включен (фамилия, имя), и в результате люди, живущие в Лондоне, случайно разбросаны по всему индексу.
Если у вас есть некластеризованный индекс для (города), то эти запросы можно выполнить намного быстрее.
Надеюсь, это поможет!
Очень хорошая аналогия - считать индекс базы данных индексом в книге. Если у вас есть книга о странах и вы ищете Индию, то зачем вам перелистывать всю книгу - что эквивалентно полному сканированию таблицы в терминологии базы данных - когда вы можете просто перейти к индексу в конце книга, которая расскажет вам точные страницы, где вы можете найти информацию об Индии. Аналогично, так как индекс книги содержит номер страницы, индекс базы данных содержит указатель на строку, содержащую значение, которое вы ищете в своем SQL.
Индекс используется для ускорения выполнения запросов. Это достигается за счет уменьшения количества страниц данных базы данных, которые необходимо посетить / отсканировать.
В SQL Server кластерный индекс определяет физический порядок данных в таблице. В таблице может быть только один кластеризованный индекс (кластеризованный индекс - это таблица). Все остальные индексы в таблице называются некластеризованными.
Индексы предназначены для быстрого поиска данных. Индексы в базе данных аналогичны индексам, которые вы найдете в книге. Если у книги есть указатель, и я прошу вас найти главу в этой книге, вы можете быстро найти ее с помощью указателя. С другой стороны, если книга не имеет указателя, вам придется больше времени искать в поисках главы, просматривая каждую страницу от начала до конца книги. Аналогичным образом индексы в базе данных могут помочь запросам быстро находить данные. Если вы новичок в индексах, следующие видео могут быть очень полезны. Фактически, я многому научился у них.
Основы индекса
Кластерные и некластерные индексы
Уникальные и неуникальные индексы
Преимущества и недостатки индексов
Для начала нам нужно понять, как выполняется нормальный (без индексации) запрос. Он в основном пересекает каждую строку одну за другой и, когда находит данные, возвращает. Смотрите следующее изображение. (Это изображение было взято из этого видео.)
 Итак, предположим, что запрос должен найти 50, он должен будет прочитать 49 записей в виде линейного поиска.
Итак, предположим, что запрос должен найти 50, он должен будет прочитать 49 записей в виде линейного поиска.
Смотрите следующее изображение. (Это изображение было взято из этого видео)
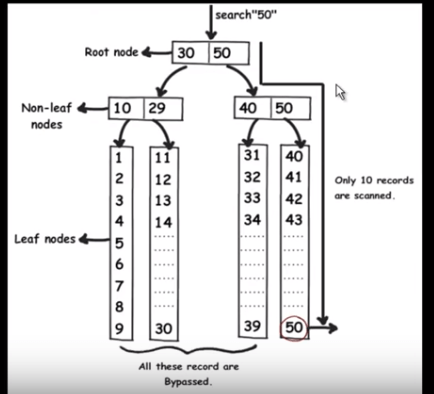
Когда мы применяем индексирование, запрос быстро обнаруживает данные, не считывая каждый из них, просто удаляя половину данных в каждом обходе, как при бинарном поиске. Индексы mysql хранятся в виде B-дерева, где все данные находятся в конечном узле.
Ну вообще индекс это B-tree, Существует два типа индексов: кластеризованные и некластеризованные.
Кластерный индекс создает физический порядок строк (он может быть только один, и в большинстве случаев он также является первичным ключом - если вы создаете первичный ключ для таблицы, вы также создаете кластерный индекс для этой таблицы).
Некластеризованный индекс также является двоичным деревом, но он не создает физический порядок строк. Таким образом, конечные узлы некластерного индекса содержат PK (если он существует) или индекс строки.
Индексы используются для увеличения скорости поиска. Потому что сложность O(log N). Индексы это очень большая и интересная тема. Я могу сказать, что создание индексов для большой базы данных иногда является искусством.
INDEXES - легко найти данные
UNIQUE INDEX - повторяющиеся значения не допускаются
Синтаксис для INDEX
CREATE INDEX INDEX_NAME ON TABLE_NAME(COLUMN);
Синтаксис для UNIQUE INDEX
CREATE UNIQUE INDEX INDEX_NAME ON TABLE_NAME(COLUMN);
INDEX - это метод оптимизации производительности, который ускоряет процесс поиска данных. Это постоянная структура данных, связанная с таблицей (или представлением), чтобы повысить производительность при извлечении данных из этой таблицы (или представления).
Индексный поиск применяется более конкретно, когда ваши запросы включают фильтр WHERE. В противном случае, т. Е. Запрос без WHERE-фильтра отбирает целые данные и обрабатывает их. Поиск по всей таблице без INDEX называется Table-scan.
Вы найдете точную информацию для Sql-индексов в ясной и надежной форме: перейдите по следующим ссылкам:
- Для лучшего понимания: http://dotnetauthorities.blogspot.in/2013/12/Microsoft-SQL-Server-Training-Online-Learning-Classes-INDEX-Overview-and-Optimizations.html
- Для понимания в плане реализации: http://dotnetauthorities.blogspot.in/2013/12/Microsoft-SQL-Server-Training-Online-Learning-Classes-INDEX-Creation-Deletetion-Optimizations.html
Если вы используете SQL Server, одним из лучших ресурсов является собственная электронная книга Books Online, которая поставляется вместе с установкой! Это первое место, на которое я бы ссылался для ЛЮБЫХ тем, связанных с SQL Server.
Если это практично, "как мне это сделать?" вопросы, тогда Stackru будет лучшим местом, чтобы спросить.
Кроме того, я давно не вернулся, но sqlservercentral.com раньше был одним из лучших сайтов, связанных с SQL Server.
Индекс используется по нескольким причинам. Основной причиной является ускорение запросов, чтобы вы могли получать строки или сортировать строки быстрее. Другая причина заключается в определении первичного ключа или уникального индекса, который гарантирует, что никакие другие столбцы не будут иметь таких же значений.
Итак, как на самом деле работает индексация?
Ну, во-первых, таблица базы данных не меняет порядок, когда мы помещаем индекс в столбец, чтобы оптимизировать производительность запроса.
An index is a data structure, (most commonly its B-tree {Its balanced tree, not binary tree}) that stores the value for a specific column in a table.
Основным преимуществом B-дерева является то, что данные в нем можно сортировать. Наряду с этим структура данных B-Tree эффективна по времени, а такие операции, как поиск, вставка, удаление, могут выполняться за логарифмическое время.
Таким образом, индекс будет выглядеть так -
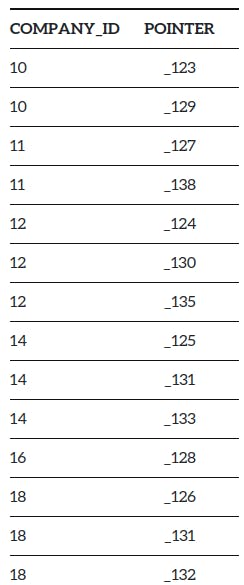
Здесь для каждого столбца он будет сопоставлен с внутренним идентификатором (указателем) базы данных, который указывает на точное местоположение строки. И теперь, если мы запустим тот же запрос.
Визуальное представление выполнения запроса
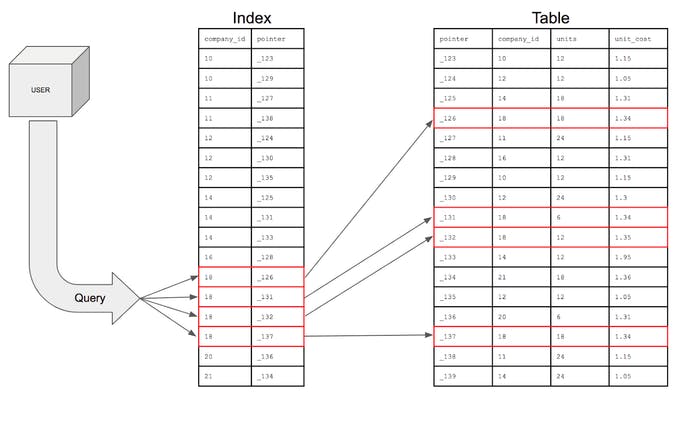
Таким образом, индексирование просто сокращает временную сложность с o (n) до o (log n).
Подробная информация - https://blog.pankajtanwar.in/how-database-indexing-actually-works-internal
INDEX не является частью SQL. INDEX создает сбалансированное дерево на физическом уровне для ускорения CRUD.
SQL - это язык, который описывает схему концептуального уровня и схему внешнего уровня. SQL не описывает схему физического уровня.
Оператор, создающий ИНДЕКС, определяется СУБД, а не стандартом SQL.
Индекс - это on-disk structure associated with a table or view that speeds retrieval of rows from the table or view. Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Эти ключи хранятся в структуре (B-дереве), которая позволяет SQL Server быстро и эффективно находить строку или строки, связанные со значениями ключей.
Indexes are automatically created when PRIMARY KEY and UNIQUE constraints are defined on table columns. For example, when you create a table with a UNIQUE constraint, Database Engine automatically creates a nonclustered index.
Если вы настроили ПЕРВИЧНЫЙ КЛЮЧ, компонент Database Engine автоматически создает кластерный индекс, если кластерный индекс еще не существует. Когда вы пытаетесь применить ограничение PRIMARY KEY к существующей таблице, а кластеризованный индекс уже существует в этой таблице, SQL Server применяет первичный ключ с помощью некластеризованного индекса.
Пожалуйста, обратитесь к этому для получения дополнительной информации об индексах (кластеризованных и некластеризованных):https://docs.microsoft.com/en-us/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-ver15
Надеюсь это поможет!