Как использовать многопоточность в Python?
Я пытаюсь понять потоки в Python. Я посмотрел на документацию и примеры, но, честно говоря, многие примеры слишком сложны, и у меня возникают проблемы с их пониманием.
Как вы четко показываете задачи, разделенные для многопоточности?
26 ответов
С тех пор, как этот вопрос был задан в 2010 году, произошло реальное упрощение в том, как сделать простую многопоточность с python с map и pool.
Приведенный ниже код взят из статьи / поста в блоге, который вы обязательно должны проверить (без принадлежности) - Параллелизм в одной строке: лучшая модель для повседневных задач многопоточности. Я подведу итог ниже - это всего лишь несколько строк кода:
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(4)
results = pool.map(my_function, my_array)
Какая многопоточная версия:
results = []
for item in my_array:
results.append(my_function(item))
Описание
Map - это классная маленькая функция и ключ к легкому внедрению параллелизма в ваш код Python. Для тех, кто незнаком, map - это нечто, взятое из функциональных языков, таких как Lisp. Это функция, которая отображает другую функцию в последовательности.
Map обрабатывает для нас итерации последовательности, применяет функцию и сохраняет все результаты в удобном списке в конце.
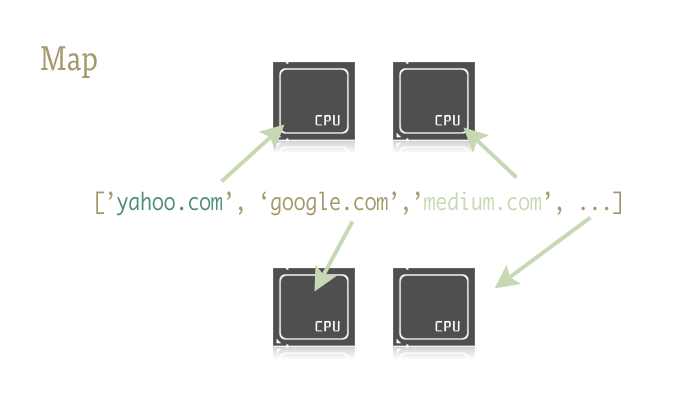
Реализация
Параллельные версии функции map предоставляются двумя библиотеками:multiprocessing, а также ее малоизвестным, но не менее фантастическим дочерним элементом:multiprocessing.dummy.
multiprocessing.dummy это то же самое, что и многопроцессорный модуль, но вместо него используются потоки ( важное отличие - использовать несколько процессов для задач с интенсивным использованием процессора; потоки для (и во время) ввода-вывода):
multiprocessing.dummy копирует API многопроцессорной обработки, но является не более чем оболочкой для модуля потоков.
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
]
# make the Pool of workers
pool = ThreadPool(4)
# open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
# close the pool and wait for the work to finish
pool.close()
pool.join()
И сроки результатов:
Single thread: 14.4 seconds
4 Pool: 3.1 seconds
8 Pool: 1.4 seconds
13 Pool: 1.3 seconds
Передача нескольких аргументов (работает так только в Python 3.3 и более поздних версиях):
Чтобы передать несколько массивов:
results = pool.starmap(function, zip(list_a, list_b))
или передать константу и массив:
results = pool.starmap(function, zip(itertools.repeat(constant), list_a))
Если вы используете более раннюю версию Python, вы можете передать несколько аргументов через этот обходной путь.
(Спасибо user136036 за полезный комментарий)
Вот простой пример: вам нужно попробовать несколько альтернативных URL-адресов и вернуть содержимое первого ответа.
import Queue
import threading
import urllib2
# called by each thread
def get_url(q, url):
q.put(urllib2.urlopen(url).read())
theurls = ["http://google.com", "http://yahoo.com"]
q = Queue.Queue()
for u in theurls:
t = threading.Thread(target=get_url, args = (q,u))
t.daemon = True
t.start()
s = q.get()
print s
Это тот случай, когда многопоточность используется в качестве простой оптимизации: каждая подпоток ожидает разрешения и ответа URL-адреса, чтобы поместить его содержимое в очередь; каждый поток является демоном (не будет поддерживать процесс, если основной поток завершится - это более распространено, чем нет); основной поток запускает все подпотоки, делает get в очереди, чтобы ждать, пока один из них не сделал put, затем генерирует результаты и завершает работу (что удаляет все подпотоки, которые все еще могут выполняться, поскольку они являются потоками демона).
Правильное использование потоков в Python неизменно связано с операциями ввода / вывода (поскольку CPython в любом случае не использует несколько ядер для выполнения задач, связанных с ЦП, единственная причина для многопоточности - не блокирование процесса, пока существует ожидание некоторого ввода / вывода). Между прочим, очереди почти всегда являются лучшим способом перераспределения работы между потоками и / или сбора результатов работы, и они по своей сути поточнобезопасны, поэтому они избавляют вас от беспокойства о блокировках, условиях, событиях, семафорах и других концепции координации / связи потоков.
ПРИМЕЧАНИЕ. Для фактического распараллеливания в Python вы должны использовать многопроцессорный модуль для ветвления нескольких процессов, которые выполняются параллельно (из-за глобальной блокировки интерпретатора потоки Python обеспечивают чередование, но на самом деле выполняются последовательно, а не параллельно, и полезны только тогда, когда чередование операций ввода / вывода).
Однако, если вы просто ищете чередование (или выполняете операции ввода-вывода, которые можно распараллелить, несмотря на глобальную блокировку интерпретатора), то модуль потоков - это то место, с которого нужно начинать. В качестве простого примера рассмотрим проблему суммирования большого диапазона путем параллельного суммирования поддиапазонов:
import threading
class SummingThread(threading.Thread):
def __init__(self,low,high):
super(SummingThread, self).__init__()
self.low=low
self.high=high
self.total=0
def run(self):
for i in range(self.low,self.high):
self.total+=i
thread1 = SummingThread(0,500000)
thread2 = SummingThread(500000,1000000)
thread1.start() # This actually causes the thread to run
thread2.start()
thread1.join() # This waits until the thread has completed
thread2.join()
# At this point, both threads have completed
result = thread1.total + thread2.total
print result
Обратите внимание, что приведенный выше пример является очень глупым, поскольку он абсолютно не выполняет ввод-вывод и будет выполняться последовательно, хотя и с чередованием (с дополнительными издержками переключения контекста) в CPython из-за глобальной блокировки интерпретатора.
Как и другие упомянутые, CPython может использовать потоки только для ожидания ввода-вывода из-за GIL. Если вы хотите использовать несколько ядер для задач, связанных с процессором, используйте многопроцессорность:
from multiprocessing import Process
def f(name):
print 'hello', name
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
Просто примечание, очередь не требуется для многопоточности.
Это самый простой пример, который я могу себе представить, который показывает 10 процессов, запущенных одновременно.
import threading
from random import randint
from time import sleep
def print_number(number):
# Sleeps a random 1 to 10 seconds
rand_int_var = randint(1, 10)
sleep(rand_int_var)
print "Thread " + str(number) + " slept for " + str(rand_int_var) + " seconds"
thread_list = []
for i in range(1, 10):
# Instantiates the thread
# (i) does not make a sequence, so (i,)
t = threading.Thread(target=print_number, args=(i,))
# Sticks the thread in a list so that it remains accessible
thread_list.append(t)
# Starts threads
for thread in thread_list:
thread.start()
# This blocks the calling thread until the thread whose join() method is called is terminated.
# From http://docs.python.org/2/library/threading.html#thread-objects
for thread in thread_list:
thread.join()
# Demonstrates that the main process waited for threads to complete
print "Done"
Ответ от Алекса Мартелли помог мне, однако здесь есть измененная версия, которая, на мой взгляд, была более полезной (по крайней мере, для меня).
import Queue
import threading
import urllib2
worker_data = ['http://google.com', 'http://yahoo.com', 'http://bing.com']
#load up a queue with your data, this will handle locking
q = Queue.Queue()
for url in worker_data:
q.put(url)
#define a worker function
def worker(queue):
queue_full = True
while queue_full:
try:
#get your data off the queue, and do some work
url= queue.get(False)
data = urllib2.urlopen(url).read()
print len(data)
except Queue.Empty:
queue_full = False
#create as many threads as you want
thread_count = 5
for i in range(thread_count):
t = threading.Thread(target=worker, args = (q,))
t.start()
Учитывая функцию, f, нить это так:
import threading
threading.Thread(target=f).start()
Чтобы передать аргументы f
threading.Thread(target=f, args=(a,b,c)).start()
Я нашел это очень полезным: создать столько потоков, сколько ядер, и позволить им выполнять (большое) количество задач (в данном случае, вызывая программу оболочки):
import Queue
import threading
import multiprocessing
import subprocess
q = Queue.Queue()
for i in range(30): #put 30 tasks in the queue
q.put(i)
def worker():
while True:
item = q.get()
#execute a task: call a shell program and wait until it completes
subprocess.call("echo "+str(item), shell=True)
q.task_done()
cpus=multiprocessing.cpu_count() #detect number of cores
print("Creating %d threads" % cpus)
for i in range(cpus):
t = threading.Thread(target=worker)
t.daemon = True
t.start()
q.join() #block until all tasks are done
В Python 3 есть возможность запуска параллельных задач. Это облегчает нашу работу.
Имеет пул потоков и пул процессов.
Следующее дает понимание:
Пример ThreadPoolExecutor
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
ProcessPoolExecutor
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
Я видел здесь много примеров, когда никакой реальной работы не выполнялось + они были в основном связаны с процессором. Вот пример задачи, связанной с процессором, которая вычисляет все простые числа от 10 миллионов до 10,05 миллионов. Я использовал все 4 метода здесь
import math
import timeit
import threading
import multiprocessing
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def time_stuff(fn):
"""
Measure time of execution of a function
"""
def wrapper(*args, **kwargs):
t0 = timeit.default_timer()
fn(*args, **kwargs)
t1 = timeit.default_timer()
print("{} seconds".format(t1 - t0))
return wrapper
def find_primes_in(nmin, nmax):
"""
Compute a list of prime numbers between the given minimum and maximum arguments
"""
primes = []
#Loop from minimum to maximum
for current in range(nmin, nmax + 1):
#Take the square root of the current number
sqrt_n = int(math.sqrt(current))
found = False
#Check if the any number from 2 to the square root + 1 divides the current numnber under consideration
for number in range(2, sqrt_n + 1):
#If divisible we have found a factor, hence this is not a prime number, lets move to the next one
if current % number == 0:
found = True
break
#If not divisible, add this number to the list of primes that we have found so far
if not found:
primes.append(current)
#I am merely printing the length of the array containing all the primes but feel free to do what you want
print(len(primes))
@time_stuff
def sequential_prime_finder(nmin, nmax):
"""
Use the main process and main thread to compute everything in this case
"""
find_primes_in(nmin, nmax)
@time_stuff
def threading_prime_finder(nmin, nmax):
"""
If the minimum is 1000 and the maximum is 2000 and we have 4 workers
1000 - 1250 to worker 1
1250 - 1500 to worker 2
1500 - 1750 to worker 3
1750 - 2000 to worker 4
so lets split the min and max values according to the number of workers
"""
nrange = nmax - nmin
threads = []
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
#Start the thrread with the min and max split up to compute
#Parallel computation will not work here due to GIL since this is a CPU bound task
t = threading.Thread(target = find_primes_in, args = (start, end))
threads.append(t)
t.start()
#Dont forget to wait for the threads to finish
for t in threads:
t.join()
@time_stuff
def processing_prime_finder(nmin, nmax):
"""
Split the min, max interval similar to the threading method above but use processes this time
"""
nrange = nmax - nmin
processes = []
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
p = multiprocessing.Process(target = find_primes_in, args = (start, end))
processes.append(p)
p.start()
for p in processes:
p.join()
@time_stuff
def thread_executor_prime_finder(nmin, nmax):
"""
Split the min max interval similar to the threading method but use thread pool executor this time
This method is slightly faster than using pure threading as the pools manage threads more efficiently
This method is still slow due to the GIL limitations since we are doing a CPU bound task
"""
nrange = nmax - nmin
with ThreadPoolExecutor(max_workers = 8) as e:
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
e.submit(find_primes_in, start, end)
@time_stuff
def process_executor_prime_finder(nmin, nmax):
"""
Split the min max interval similar to the threading method but use the process pool executor
This is the fastest method recorded so far as it manages process efficiently + overcomes GIL limitations
RECOMMENDED METHOD FOR CPU BOUND TASKS
"""
nrange = nmax - nmin
with ProcessPoolExecutor(max_workers = 8) as e:
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
e.submit(find_primes_in, start, end)
def main():
nmin = int(1e7)
nmax = int(1.05e7)
print("Sequential Prime Finder Starting")
sequential_prime_finder(nmin, nmax)
print("Threading Prime Finder Starting")
threading_prime_finder(nmin, nmax)
print("Processing Prime Finder Starting")
processing_prime_finder(nmin, nmax)
print("Thread Executor Prime Finder Starting")
thread_executor_prime_finder(nmin, nmax)
print("Process Executor Finder Starting")
process_executor_prime_finder(nmin, nmax)
main()
Вот результаты на моем компьютере с Mac OSX 4
Sequential Prime Finder Starting
9.708213827005238 seconds
Threading Prime Finder Starting
9.81836523200036 seconds
Processing Prime Finder Starting
3.2467174359990167 seconds
Thread Executor Prime Finder Starting
10.228896902000997 seconds
Process Executor Finder Starting
2.656402041000547 seconds
Использование сверкающего нового модуля concurrent.futures
def sqr(val):
import time
time.sleep(0.1)
return val * val
def process_result(result):
print(result)
def process_these_asap(tasks):
import concurrent.futures
with concurrent.futures.ProcessPoolExecutor() as executor:
futures = []
for task in tasks:
futures.append(executor.submit(sqr, task))
for future in concurrent.futures.as_completed(futures):
process_result(future.result())
# Or instead of all this just do:
# results = executor.map(sqr, tasks)
# list(map(process_result, results))
def main():
tasks = list(range(10))
print('Processing {} tasks'.format(len(tasks)))
process_these_asap(tasks)
print('Done')
return 0
if __name__ == '__main__':
import sys
sys.exit(main())
Подход к исполнителю может показаться знакомым всем тем, кто раньше запачкал руки в Java.
Также на заметку: чтобы сохранить разумность вселенной, не забывайте закрывать свои пулы / исполнителей, если вы не используете with контекст (который настолько хорош, что делает это за вас)
Для меня идеальным примером потоков является мониторинг асинхронных событий. Посмотрите на этот код.
# thread_test.py
import threading
import time
class Monitor(threading.Thread):
def __init__(self, mon):
threading.Thread.__init__(self)
self.mon = mon
def run(self):
while True:
if self.mon[0] == 2:
print "Mon = 2"
self.mon[0] = 3;
Вы можете поиграть с этим кодом, открыв сеанс IPython и выполнив что-то вроде:
>>>from thread_test import Monitor
>>>a = [0]
>>>mon = Monitor(a)
>>>mon.start()
>>>a[0] = 2
Mon = 2
>>>a[0] = 2
Mon = 2
Подожди несколько минут
>>>a[0] = 2
Mon = 2
Большинство документов и учебных пособий используют Python Threading а также Queue Модуль они могут показаться подавляющим для начинающих.
Возможно, рассмотрим concurrent.futures.ThreadPoolExecutor Модуль Python 3. В сочетании с with Положение и список понимания это может быть настоящим шармом.
from concurrent.futures import ThreadPoolExecutor, as_completed
def get_url(url):
# Your actual program here. Using threading.Lock() if necessary
return ""
# List of urls to fetch
urls = ["url1", "url2"]
with ThreadPoolExecutor(max_workers = 5) as executor:
# Create threads
futures = {executor.submit(get_url, url) for url in urls}
# as_completed() gives you the threads once finished
for f in as_completed(futures):
# Get the results
rs = f.result()
Заимствуя из этого поста, мы знаем выбор между многопоточностью, многопроцессорностью и асинхронностью их использования.
Python3 имеет новую встроенную библиотеку для параллелизма и параллелизма: concurrent.futures
Таким образом, я демонстрирую экспериментом для запуска четырех задач (т.е. .sleep() метод) Threading-Pool Способ:
from concurrent.futures import ThreadPoolExecutor, as_completed
from time import sleep, time
def concurrent(max_worker=1):
futures = []
tick = time()
with ThreadPoolExecutor(max_workers=max_worker) as executor:
futures.append(executor.submit(sleep, 2))
futures.append(executor.submit(sleep, 1))
futures.append(executor.submit(sleep, 7))
futures.append(executor.submit(sleep, 3))
for future in as_completed(futures):
if future.result() is not None:
print(future.result())
print('Total elapsed time by {} workers:'.format(max_worker), time()-tick)
concurrent(5)
concurrent(4)
concurrent(3)
concurrent(2)
concurrent(1)
Вне:
Total elapsed time by 5 workers: 7.007831811904907
Total elapsed time by 4 workers: 7.007944107055664
Total elapsed time by 3 workers: 7.003149509429932
Total elapsed time by 2 workers: 8.004627466201782
Total elapsed time by 1 workers: 13.013478994369507
[ПРИМЕЧАНИЕ]:
- Как видно из приведенных выше результатов, лучший случай был
3рабочие четыре, четыре задачи. - Если у вас есть задача процесса вместо ввода-вывода (используя
thread) вы могли бы изменитьThreadPoolExecutorс участиемProcessPoolExecutor
Я хотел бы поделиться простым примером и объяснениями, которые я нашел полезными, когда мне пришлось самому заняться этой проблемой.
Здесь я вставлю некоторую полезную информацию о GIL и простом повседневном примере (с использованием multiprocessing.dummy) и его тестах с многопоточностью и без нее.
Глобальная блокировка интерпретатора (GIL)
Python не допускает многопоточность в прямом смысле этого слова. Он имеет многопоточный пакет, но если вы хотите многопоточность, чтобы ускорить ваш код, то использовать его обычно не очень хорошая идея. Python имеет конструкцию, называемую Global Interpreter Lock (GIL). GIL гарантирует, что только один из ваших "потоков" может выполняться одновременно. Поток получает GIL, выполняет небольшую работу, а затем передает GIL следующему потоку. Это происходит очень быстро, поэтому человеческому глазу может показаться, что ваши потоки выполняются параллельно, но на самом деле они просто по очереди используют одно и то же ядро ЦП. Вся эта передача GIL увеличивает накладные расходы на выполнение. Это означает, что если вы хотите, чтобы ваш код выполнялся быстрее, то использование потокового пакета часто не является хорошей идеей.
Есть причины использовать пакет потоков Python. Если вы хотите запускать некоторые вещи одновременно, а эффективность не имеет значения, тогда это совершенно нормально и удобно. Или, если вы запускаете код, который должен чего-то ждать (например, какой-нибудь ввод-вывод), тогда это может иметь большой смысл. Но библиотека потоков не позволит вам использовать дополнительные ядра процессора.
Многопоточность может быть передана на аутсорсинг операционной системе (посредством многопроцессорной обработки), некоторому внешнему приложению, которое вызывает ваш код Python (например, Spark или Hadoop), или некоторому коду, который вызывает ваш код Python (например, у вас может быть ваш Python код вызывает функцию C, которая делает дорогие многопоточные вещи).
Почему это важно
Потому что многие люди тратят много времени, пытаясь найти узкие места в своем причудливом многопоточном коде Python, прежде чем узнают, что такое GIL.
Как только эта информация станет понятной, вот мой код:
#!/bin/python
from multiprocessing.dummy import Pool
from subprocess import PIPE,Popen
import time
import os
# In the variable pool_size we define the "parallelness".
# For CPU-bound tasks, it doesn't make sense to create more Pool processes
# than you have cores to run them on.
#
# On the other hand, if you are using I/O-bound tasks, it may make sense
# to create a quite a few more Pool processes than cores, since the processes
# will probably spend most their time blocked (waiting for I/O to complete).
pool_size = 8
def do_ping(ip):
if os.name == 'nt':
print ("Using Windows Ping to " + ip)
proc = Popen(['ping', ip], stdout=PIPE)
return proc.communicate()[0]
else:
print ("Using Linux / Unix Ping to " + ip)
proc = Popen(['ping', ip, '-c', '4'], stdout=PIPE)
return proc.communicate()[0]
os.system('cls' if os.name=='nt' else 'clear')
print ("Running using threads\n")
start_time = time.time()
pool = Pool(pool_size)
website_names = ["www.google.com","www.facebook.com","www.pinterest.com","www.microsoft.com"]
result = {}
for website_name in website_names:
result[website_name] = pool.apply_async(do_ping, args=(website_name,))
pool.close()
pool.join()
print ("\n--- Execution took {} seconds ---".format((time.time() - start_time)))
# Now we do the same without threading, just to compare time
print ("\nRunning NOT using threads\n")
start_time = time.time()
for website_name in website_names:
do_ping(website_name)
print ("\n--- Execution took {} seconds ---".format((time.time() - start_time)))
# Here's one way to print the final output from the threads
output = {}
for key, value in result.items():
output[key] = value.get()
print ("\nOutput aggregated in a Dictionary:")
print (output)
print ("\n")
print ("\nPretty printed output:")
for key, value in output.items():
print (key + "\n")
print (value)
Вот очень простой пример импорта CSV с использованием потоков. [Включение библиотеки может отличаться для разных целей]
Вспомогательные функции:
from threading import Thread
from project import app
import csv
def import_handler(csv_file_name):
thr = Thread(target=dump_async_csv_data, args=[csv_file_name])
thr.start()
def dump_async_csv_data(csv_file_name):
with app.app_context():
with open(csv_file_name) as File:
reader = csv.DictReader(File)
for row in reader:
#DB operation/query
Функция водителя:
import_handler(csv_file_name)
Многопоточность с простым примером, который будет полезен. Вы можете запустить его и легко понять, как многопоточная работа в Python. Я использовал блокировку для предотвращения доступа к другому потоку, пока предыдущие потоки не закончили свою работу. С помощью
tLock = threading.BoundedSemaphore(значение =4)
В этой строке кода вы можете разрешить номера процессов одновременно и удерживать остальные потоки, которые будут выполняться позже или после завершения предыдущих процессов.
import threading
import time
#tLock = threading.Lock()
tLock = threading.BoundedSemaphore(value=4)
def timer(name, delay, repeat):
print "\r\nTimer: ", name, " Started"
tLock.acquire()
print "\r\n", name, " has the acquired the lock"
while repeat > 0:
time.sleep(delay)
print "\r\n", name, ": ", str(time.ctime(time.time()))
repeat -= 1
print "\r\n", name, " is releaseing the lock"
tLock.release()
print "\r\nTimer: ", name, " Completed"
def Main():
t1 = threading.Thread(target=timer, args=("Timer1", 2, 5))
t2 = threading.Thread(target=timer, args=("Timer2", 3, 5))
t3 = threading.Thread(target=timer, args=("Timer3", 4, 5))
t4 = threading.Thread(target=timer, args=("Timer4", 5, 5))
t5 = threading.Thread(target=timer, args=("Timer5", 0.1, 5))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
print "\r\nMain Complete"
if __name__ == "__main__":
Main()
Ни одно из вышеперечисленных решений не использовало несколько ядер на моем сервере GNU/Linux (где у меня нет прав администратора). Они просто работали на одном ядре. Я использовал нижний уровень os.fork интерфейс для порождения нескольких процессов. Это код, который работал для меня:
from os import fork
values = ['different', 'values', 'for', 'threads']
for i in range(len(values)):
p = fork()
if p == 0:
my_function(values[i])
break
import threading
import requests
def send():
r = requests.get('https://www.stackoverlow.com')
thread = []
t = threading.Thread(target=send())
thread.append(t)
t.start()
Как версия python3 второго anwser:
import queue as Queue
import threading
import urllib.request
# Called by each thread
def get_url(q, url):
q.put(urllib.request.urlopen(url).read())
theurls = ["http://google.com", "http://yahoo.com", "http://www.python.org","https://wiki.python.org/moin/"]
q = Queue.Queue()
def thread_func():
for u in theurls:
t = threading.Thread(target=get_url, args = (q,u))
t.daemon = True
t.start()
s = q.get()
def non_thread_func():
for u in theurls:
get_url(q,u)
s = q.get()
И вы можете это проверить:
start = time.time()
thread_func()
end = time.time()
print(end - start)
start = time.time()
non_thread_func()
end = time.time()
print(end - start)
non_thread_func() должен стоить в 4 раза больше времени, чем thread_func()
Это очень легко понять. Вот два простых способа создания потоков.
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
import threading
def a(a=1, b=2):
print(a)
time.sleep(5)
print(b)
return a+b
def b(**kwargs):
if "a" in kwargs:
print("am b")
else:
print("nothing")
to_do=[]
executor = ThreadPoolExecutor(max_workers=4)
ex1=executor.submit(a)
to_do.append(ex1)
ex2=executor.submit(b, **{"a":1})
to_do.append(ex2)
for future in as_completed(to_do):
print("Future {} and Future Return is {}\n".format(future, future.result()))
print("threading")
to_do=[]
to_do.append(threading.Thread(target=a))
to_do.append(threading.Thread(target=b, kwargs={"a":1}))
for threads in to_do:
threads.start()
for threads in to_do:
threads.join()
import threading
myHeavyFctThread = threading.Thread(name='myHeavyFunction', target=myHeavyFunction)
f = threading.Thread(name='foreground', target=foreground)
когда вместо myHeavyFunction вы передаете имя вашей функции и когда вам нужно активировать поток:
myHeavyFctThread.start()
Я знаю, что уже поздно, но может кому-то помочь:D
Этот код ниже может запускать 10 потоков одновременно , печатая числа от до :
from threading import Thread
def test():
for i in range(0, 100):
print(i)
thread_list = []
for _ in range(0, 10):
thread = Thread(target=test)
thread_list.append(thread)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
И этот код ниже является сокращением
forциклическая версия приведенного выше кода, выполняющая 10 потоков, одновременно печатающих числа из0к99:
from threading import Thread
def test():
[print(i) for i in range(0, 100)]
thread_list = [Thread(target=test) for _ in range(0, 10)]
[thread.start() for thread in thread_list]
[thread.join() for thread in thread_list]
Это результат ниже:
...
99
83
97
84
98
99
85
86
87
88
...
Пример многопоточности. Здесь потоки выполняются одновременно:
from threading import Thread
def fun_square(x):
x_square = x**2
print('x_square: ', x_square)
def x_pow_y(x,y):
x_pow_y = x**y
print('x_pow_y: ', x_pow_y)
def fun_qube(z):
z_qube = z*z*z
print('z_qube: ', z_qube)
def normal_fun():
print("Normal fun is working at same time...")
Thread(target = fun_square, args=(5,)).start() #args=(x,)
Thread(target = x_pow_y, args=(2,4,)).start() #args=(x,y,)
Thread(target = fun_qube(4)).start() #fun_qube(z)
Thread(target = normal_fun).start()
Самый простой способ использования многопоточности/многопроцессорности — использовать библиотеки более высокого уровня, такие как autothread.
import autothread
from time import sleep as heavyworkload
@autothread.multithreaded() # <-- This is all you need to add
def example(x: int, y: int):
heavyworkload(1)
return x*y
Теперь вы можете накормить свои списки функций целыми числами. Autothread сделает все за вас и просто выдаст результаты, рассчитанные параллельно.
result = example([1, 2, 3, 4, 5], 10)
Здесь args - это кортеж аргументов; используйте пустой кортеж для вызова функции без передачи аргументов. kwargs - необязательный словарь аргументов ключевых слов.
пример
#!/usr/bin/python
import thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print "%s: %s" % ( threadName, time.ctime(time.time()) )
# Create two threads as follows
try:
thread.start_new_thread( print_time, ("Thread-1", 2, ) )
thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print "Error: unable to start thread"
while 1:
pass
Когда приведенный выше код выполняется, он дает следующий результат -
Thread-1: Thu Jan 22 15:42:17 2009
Thread-1: Thu Jan 22 15:42:19 2009
Thread-2: Thu Jan 22 15:42:19 2009
Thread-1: Thu Jan 22 15:42:21 2009
Thread-2: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:25 2009
Thread-2: Thu Jan 22 15:42:27 2009
Thread-2: Thu Jan 22 15:42:31 2009
Thread-2: Thu Jan 22 15:42:35 2009