Почему расширение нативных объектов - плохая практика?
Каждый лидер общественного мнения говорит, что расширение нативных объектов - плохая практика. Но почему? Мы получаем хит производительности? Боятся ли они, что кто-то делает это "неправильным путем" и добавляет перечислимые типы в Object, практически уничтожая все петли на любом объекте?
Возьмите TJ Holowaychuk's should.js, например. Он добавляет простой метод получения Object и все отлично работает ( источник).
Object.defineProperty(Object.prototype, 'should', {
set: function(){},
get: function(){
return new Assertion(Object(this).valueOf());
},
configurable: true
});
Это действительно имеет смысл. Например, можно продлить Array,
Array.defineProperty(Array.prototype, "remove", {
set: function(){},
get: function(){
return removeArrayElement.bind(this);
}
});
var arr = [0, 1, 2, 3, 4];
arr.remove(3);
Есть ли аргументы против расширения нативных типов?
9 ответов
Когда вы расширяете объект, вы меняете его поведение.
Изменение поведения объекта, который будет использоваться только вашим собственным кодом, вполне подойдет. Но когда вы изменяете поведение чего-то, что также используется другим кодом, существует риск, что вы нарушите этот другой код.
Когда дело доходит до добавления методов в классы объектов и массивов в javascript, риск взлома чего-либо очень велик из-за того, как работает javascript. Многолетний опыт научил меня тому, что подобные вещи приводят ко всем видам ужасных ошибок в javascript.
Если вам нужно пользовательское поведение, гораздо лучше определить свой собственный класс (возможно, подкласс), а не менять собственный. Таким образом, вы ничего не сломаете.
Возможность изменить работу класса без разделения на подклассы является важной особенностью любого хорошего языка программирования, но его следует использовать редко и с осторожностью.
Там нет измеримого недостатка, как удар производительности. По крайней мере, никто не упомянул. Так что это вопрос личных предпочтений и опыта.
Главный аргумент "за": выглядит лучше и более интуитивно понятен: синтаксис "сахар". Это особая функция типа / экземпляра, поэтому она должна быть специально привязана к этому типу / экземпляру.
Главный противоположный аргумент: код может вмешиваться. Если lib A добавляет функцию, она может перезаписать функцию lib B. Это может очень легко взломать код.
У обоих есть смысл. Когда вы полагаетесь на две библиотеки, которые напрямую изменяют ваши типы, вы, скорее всего, в итоге получите неработающий код, поскольку ожидаемая функциональность, вероятно, не одинакова. Я полностью согласен с этим. Макробиблиотеки не должны манипулировать нативными типами. В противном случае вы как разработчик никогда не узнаете, что на самом деле происходит за кулисами.
И это причина, по которой мне не нравятся такие библиотеки, как jQuery, подчеркивание и т. Д. Не поймите меня неправильно; они абсолютно хорошо запрограммированы и работают как шарм, но они большие. Вы используете только 10% из них, и понимаете около 1%.
Вот почему я предпочитаю атомистический подход, когда вам требуется только то, что вам действительно нужно. Таким образом, вы всегда знаете, что происходит. Микробиблиотеки делают только то, что вы от них хотите, чтобы они не мешали. В контексте того, что конечный пользователь знает, какие функции добавлены, расширение собственных типов можно считать безопасным.
TL; DR В случае сомнений не расширяйте нативные типы. Расширяйте собственный тип только в том случае, если вы на 100% уверены, что конечный пользователь будет знать о таком поведении и захочет его использовать. Ни в коем случае не манипулируйте существующими функциями нативного типа, так как это нарушит существующий интерфейс.
Если вы решили расширить тип, используйте Object.defineProperty(obj, prop, desc); если вы не можете использовать тип prototype,
Я изначально придумал этот вопрос, потому что я хотел Error s для отправки через JSON. Итак, мне нужен был способ их упорядочить. error.stringify() чувствовал себя намного лучше, чем errorlib.stringify(error); как предполагает вторая конструкция, я работаю над errorlib и не на error сам.
На мой взгляд, это плохая практика. Основная причина - интеграция. Цитирование следует.js документы:
OMG IT РАСШИРЯЕТ ОБЪЕКТ???!?!@ Да, да, да, с одним геттером должен, и нет, это не сломает ваш код
Ну, как может автор узнать? Что, если мой фреймворк делает то же самое? Что если мои обещания lib делает то же самое?
Если вы делаете это в своем собственном проекте, тогда это нормально. Но для библиотеки это плохой дизайн. Underscore.js - пример того, как все сделано правильно:
var arr = [];
_(arr).flatten()
// or: _.flatten(arr)
// NOT: arr.flatten()
Если вы посмотрите на это в каждом конкретном случае, возможно, некоторые реализации являются приемлемыми.
String.prototype.slice = function slice( me ){
return me;
}; // Definite risk.
Перезапись уже созданных методов создает больше проблем, чем решает, поэтому на многих языках программирования обычно утверждается, что такой практики избегают. Как разработчики знают, что функция была изменена?
String.prototype.capitalize = function capitalize(){
return this.charAt(0).toUpperCase() + this.slice(1);
}; // A little less risk.
В этом случае мы не перезаписываем какой-либо известный базовый метод JS, но расширяем String. Один из аргументов в этом посте упоминал, как новый разработчик узнает, является ли этот метод частью ядра JS, или где найти документы? Что произойдет, если основной объект JS String получит метод с именем capitalize?
Что если вместо добавления имен, которые могут конфликтовать с другими библиотеками, вы использовали специфический для компании / приложения модификатор, понятный всем разработчикам?
String.prototype.weCapitalize = function weCapitalize(){
return this.charAt(0).toUpperCase() + this.slice(1);
}; // marginal risk.
var myString = "hello to you.";
myString.weCapitalize();
// => Hello to you.
Если вы продолжите расширять другие объекты, все разработчики столкнутся с ними в дикой природе (в данном случае) с нами, которая уведомит их о том, что это расширение относится к конкретной компании / приложению.
Это не устраняет коллизии имен, но уменьшает вероятность. Если вы решите, что расширение основных объектов JS предназначено для вас и / или вашей команды, возможно, это для вас.
Расширение прототипов встроенных модулей - действительно плохая идея. Тем не менее, ES2015 представил новый метод, который можно использовать для получения желаемого поведения:
использующий WeakMap s, чтобы связать типы со встроенными прототипами
Следующая реализация расширяет Number а также Array прототипы, не касаясь их вообще:
// new types
const AddMonoid = {
empty: () => 0,
concat: (x, y) => x + y,
};
const ArrayMonoid = {
empty: () => [],
concat: (acc, x) => acc.concat(x),
};
const ArrayFold = {
reduce: xs => xs.reduce(
type(xs[0]).monoid.concat,
type(xs[0]).monoid.empty()
)};
// the WeakMap that associates types to prototpyes
types = new WeakMap();
types.set(Number.prototype, {
monoid: AddMonoid
});
types.set(Array.prototype, {
monoid: ArrayMonoid,
fold: ArrayFold
});
// auxiliary helpers to apply functions of the extended prototypes
const genericType = map => o => map.get(o.constructor.prototype);
const type = genericType(types);
// mock data
xs = [1,2,3,4,5];
ys = [[1],[2],[3],[4],[5]];
// and run
console.log("reducing an Array of Numbers:", ArrayFold.reduce(xs) );
console.log("reducing an Array of Arrays:", ArrayFold.reduce(ys) );
console.log("built-ins are unmodified:", Array.prototype.empty);Как вы можете видеть, даже примитивные прототипы могут быть расширены с помощью этой техники. Он использует структуру карты и Object идентичность для связывания типов со встроенными прототипами.
Мой пример позволяет reduce функция, которая ожидает только Array в качестве единственного аргумента, потому что он может извлечь информацию о том, как создать пустой аккумулятор и как объединить элементы с этим аккумулятором из элементов самого массива.
Обратите внимание, что я мог бы использовать обычный Map тип, поскольку слабые ссылки не имеют смысла, когда они просто представляют встроенные прототипы, которые никогда не собираются мусором. Тем не менее, WeakMap не повторяется и не может быть проверен, если у вас нет правильного ключа. Это желаемая особенность, так как я хочу избежать любой формы отражения типа.
Еще одна причина, почему вы не должны расширять нативные объекты:
Мы используем Magento, который использует prototype.js и расширяет множество вещей на нативных объектах. Это работает хорошо, пока вы не решите включить новые функции, и вот тут начинаются большие проблемы.
Мы ввели Webcomponents на одной из наших страниц, поэтому webcomponents-lite.js решает заменить весь (нативный) объект Event в IE (почему?). Это, конечно, нарушает prototype.js, который, в свою очередь, нарушает Magento. (пока вы не найдете проблему, вы можете потратить много часов на ее устранение)
Если вам нравятся неприятности, продолжайте делать это!
Я вижу три причины не делать этого (по крайней мере, из приложения), только две из которых рассматриваются в существующих ответах здесь:
- Если вы сделаете это неправильно, вы случайно добавите перечисляемое свойство ко всем объектам расширенного типа. Легко обойти с помощью
Object.defineProperty, который создает неперечислимые свойства по умолчанию. - Вы можете вызвать конфликт с библиотекой, которую вы используете. Можно избежать с усердием; просто проверьте, какие методы определяют используемые вами библиотеки, прежде чем добавлять что-либо в прототип, проверьте примечания к выпуску при обновлении и протестируйте свое приложение.
- Вы можете вызвать конфликт с будущей версией нативной среды JavaScript.
Пункт 3, пожалуй, самый важный. Посредством тестирования вы можете убедиться, что ваши прототипные расширения не вызывают конфликтов с библиотеками, которые вы используете, потому что вы сами решаете, какие библиотеки вы используете. То же самое не относится к нативным объектам, если предположить, что ваш код выполняется в браузере. Если вы определите Array.prototype.swizzle(foo, bar) сегодня и завтра Google добавляет Array.prototype.swizzle(bar, foo) Chrome, вы можете столкнуться с некоторыми смущенными коллегами, которые задаются вопросом, почему .swizzle Поведение не похоже на то, что задокументировано в MDN.
Этого можно избежать, используя специфичный для приложения префикс для методов, добавляемых в собственные объекты (например, определение Array.prototype.myappSwizzle вместо Array.prototype.swizzle), но это некрасиво; это так же хорошо решается с помощью автономных утилит вместо дополнения прототипов.
Perf - тоже причина. Иногда вам может потребоваться перебрать ключи. Есть несколько способов сделать это
for (let key in object) { ... }
for (let key in object) { if (object.hasOwnProperty(key) { ... } }
for (let key of Object.keys(object)) { ... }
Я обычно использую for of Object.keys() так как он делает правильные вещи и относительно краток, нет необходимости добавлять проверку.
Просто догадываюсь о причине Object.keys медленно, очевидно, Object.keys()должен сделать распределение. Фактически, AFAIK с тех пор должен выделить копию всех ключей.
const before = Object.keys(object);
object.newProp = true;
const after = Object.keys(object);
before.join('') !== after.join('')
Возможно, JS-движок может использовать какую-то неизменяемую ключевую структуру, чтобы Object.keys(object) возвращает ссылку на что-то, что перебирает неизменяемые ключи и что object.newProp создает совершенно новый объект неизменяемых ключей, но что бы то ни было, он явно медленнее до 15 раз
Даже проверка hasOwnProperty до 2 раз медленнее.
Суть всего в том, что если у вас есть чувствительный к производительности код и вам нужно перебирать ключи, тогда вы хотите иметь возможность использовать for in без необходимости звонить hasOwnProperty. Вы можете сделать это, только если вы не изменилиObject.prototype
обратите внимание, что если вы используете Object.definePropertyдля изменения прототипа, если добавляемые вами вещи не перечисляются, то они не повлияют на поведение JavaScript в вышеуказанных случаях. К сожалению, по крайней мере, в Chrome 83 они влияют на производительность.
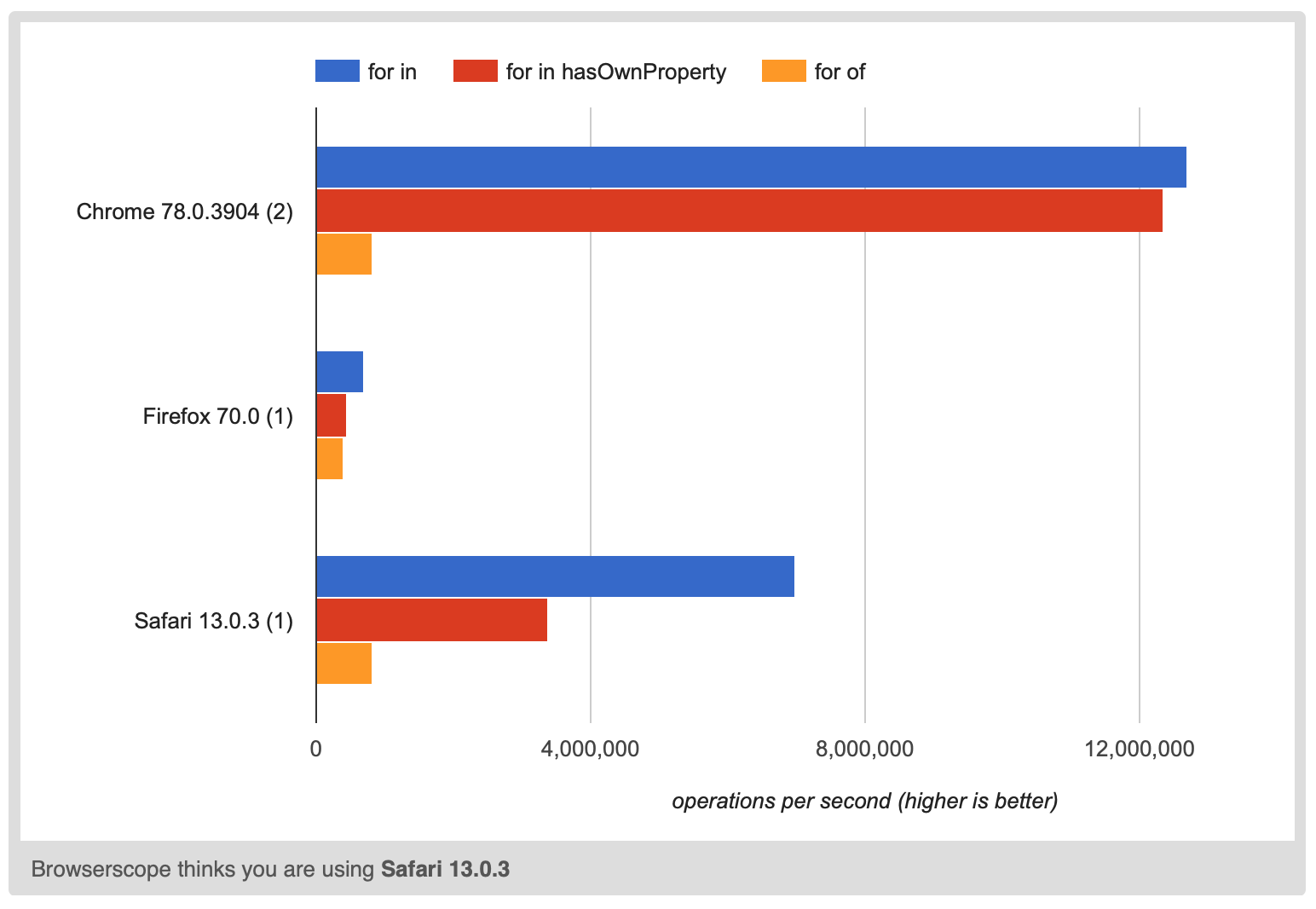
Я добавил 3000 неперечислимых свойств, чтобы попытаться вызвать любые проблемы с производительностью. Всего с 30 свойствами тесты были слишком близки, чтобы сказать, есть ли какое-либо влияние на производительность.
https://jsperf.com/does-adding-non-enumerable-properties-affect-perf
Firefox 77 и Safari 13.1 не показали разницы в производительности между классами Augmented и Unaugmented, возможно, v8 будет исправлен в этой области, и вы можете игнорировать проблемы производительности.
Но позвольте мне также добавить, что есть историяArray.prototype.smoosh. Краткая версия - это популярная библиотека Mootools, созданная самостоятельно.Array.prototype.flatten. Когда комитет по стандартам попытался добавить роднойArray.prototype.flattenони обнаружили, что не могут не взломать множество сайтов. Разработчики, узнавшие о перерыве, предложили назвать метод es5smooshв шутку, но люди волновались, не понимая, что это шутка. Они остановились наflat вместо того flatten
Мораль этой истории в том, что вы не должны расширять родные объекты. Если вы это сделаете, вы можете столкнуться с той же проблемой, что и ваши файлы, и если ваша конкретная библиотека не станет такой же популярной, как MooTools, поставщики браузеров вряд ли решат проблему, которую вы вызвали. Если ваша библиотека действительно станет такой популярной, это будет означать, что все остальные будут работать над проблемой, которую вы вызвали. Итак, пожалуйста, не расширяйте собственные объекты
Я лично расширяю собственные методы, я просто использую
x префикс в моих библиотеках (используется также при расширении сторонних библиотек).
( поскольку единственная проблема заключается в конфликте с будущим стандартом, который, скорее всего, никогда не будет вводить префикс «x» в собственные методы, за которым следует заглавная буква ), например
Только TS:
declare global {
interface Array<T> {
xFlatten(): ExtractArrayItemsRecursive<T>;
}
}
JS + TS:
Array.prototype.xFlatten = function() { /*...*/ }