Как извлечь данные из изображения, которое содержит табличные данные?
Я использую pytesseract, pillow,cv2 для распознавания изображений и получения текста, присутствующего на изображении. Поскольку мой ввод представляет собой отсканированный документ PDF, я сначала преобразовал его в формат изображения (JPEG), а затем попытался извлечь текст. Я только на полпути. Входные данные являются таблицей, и заголовки не отображаются, поскольку заголовки имеют черный фон. Я тоже пробовал getstructuringelement но не в состоянии найти способ. Вот что я сделал до сих пор
import cv2
import os
import numpy as np
import pytesseract
#import pillow
#Since scanned PDF can't be handled by pdf2image, convert the scanned PDF into a JPEG format using the below code-
filename = path
from pdf2image import convert_from_path
pages = convert_from_path(filename, 500) for page in pages:
page.save("dest", 'JPEG')
imgname = "path"
oriimg = cv2.imread(imgname,cv2.IMREAD_COLOR)
cv2.imshow("original image", oriimg)
cv2.waitKey(0)
#img = cv2.resize(oriimg,None,fx=0.5,fy=0.5,interpolation=cv2.INTER_CUBIC)
img = cv2.resize(oriimg,(700,1500),interpolation=cv2.INTER_AREA)
#here length height
cv2.imshow("lol", img)
cv2.waitKey(0)
cv2.imwrite("changed_dimensionsimgpath", img)
import PIL.Image
image = cv2.imread(imgname,cv2.IMREAD_COLOR)
grayedimg = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) grayedimg =
cv2.threshold(grayedimg, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv2.imwrite("H://newim.jpg", grayedimg)
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-
OCR\tesseract.exe"
text = pytesseract.image_to_string(PIL.Image.open("path"))
print(text)
Моя таблица ввода выглядит как ниже. Области с черным фоном не распознаются OCR и не извлекаются как текст. Любая помощь будет принята с благодарностью. 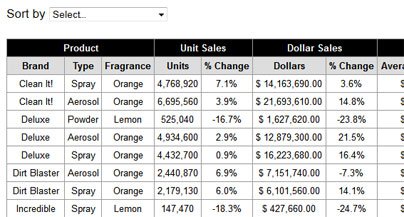
Вывод этого кода для изображения образца
Sun by Select .
F'I‘L‘Mlm":[ [Juir SHIIEF'. ”fillfit Fadll'fi
Brand Type Fragranm Unit: Ithange Dollm 'LChanga Men
Eleanit' Sprayl Grange J.?IEBflI-Efl' 11% '5H'1Elfi9flflfl 35% I E
Eleanlt! kfimnsul' Grange IEEEESWI 39% I521LESM1MH 1113553 ‘ E
Dehuxe F‘mmr [emu 525.940 461% '51:EE?,GED,00 433.6% 5
Datum: Anus»! firing?) 4,3341%} 29% 513573300119 215% E
Dem Spray ‘Drangr: £432,100 09% 515.223.:53000 154%
Min Blaster Aemgul: Dramge ”2114033111 59% :SHSiMMfl H94:
DiFlEIESIEf Sprawl Drama “NEW. 50% ‘5E1D1_E-BDM 141% I
Incredlme Spray Lem 1.513.410" 483% a HELENE] $11143 I E
t“ In
1'"
1 ответ
Использование cv2 хорошо после cv2.imwrite(имя_файла_пакета, серый_имг)
import PIL.Image
Use config='-psm 6'
page_str = image_to_string(Image.open(temp_filename), lang="eng", config='-psm 6')
Это вернет хорошие данные из изображений таблицы