Почему jnz требуется 2 цикла для завершения во внутреннем цикле
Я на IvyBridge. Я нашел поведение производительности jnz несовместимы во внутренней и внешней петлях.
Следующая простая программа имеет внутренний цикл с фиксированным размером 16:
global _start
_start:
mov rcx, 100000000
.loop_outer:
mov rax, 16
.loop_inner:
dec rax
jnz .loop_inner
dec rcx
jnz .loop_outer
xor edi, edi
mov eax, 60
syscall
perf инструмент показывает внешний цикл работает 32c/iter. Это предполагает jnz требуется 2 цикла для завершения.
Затем я ищу в таблице инструкций Агнера, условный переход имеет 1-2 "взаимную пропускную способность" с комментарием "быстро, если нет перехода".
В этот момент я начинаю верить, что вышеописанное поведение как-то ожидается. Но почему jnz во внешнем цикле требуется только 1 цикл для завершения?
Если я удалю .loop_inner часть, внешний цикл работает 1c / iter. Поведение выглядит противоречивым.
Что мне здесь не хватает?
Изменить для получения дополнительной информации:
perf Результаты для вышеуказанной программы с командой:
perf stat -ecycles,branches,branch-misses,lsd.uops,uops_issued.any -r4 ./a.out
является:
3,215,921,579 cycles ( +- 0.11% ) (79.83%)
1,701,361,270 branches ( +- 0.02% ) (80.05%)
19,212 branch-misses # 0.00% of all branches ( +- 17.72% ) (80.09%)
31,052 lsd.uops ( +- 76.58% ) (80.09%)
1,803,009,428 uops_issued.any ( +- 0.08% ) (79.93%)
perf Результат эталонного случая:
global _start
_start:
mov rcx, 100000000
.loop_outer:
mov rax, 16
dec rcx
jnz .loop_outer
xor edi, edi
mov eax, 60
syscall
является:
100,978,250 cycles ( +- 0.66% ) (75.75%)
100,606,742 branches ( +- 0.59% ) (75.74%)
1,825 branch-misses # 0.00% of all branches ( +- 13.15% ) (81.22%)
199,698,873 lsd.uops ( +- 0.07% ) (87.87%)
200,300,606 uops_issued.any ( +- 0.12% ) (79.42%)
Таким образом, причина в основном ясна: ЛСД перестает работать по какой-то причине во вложенном случае. Уменьшение размера внутреннего цикла немного уменьшит медлительность, но не полностью.
Ища в Intel "Руководство по оптимизации", я обнаружил, что LSD не будет работать, если цикл содержит "более восьми взятых веток". Это как-то объясняет поведение.
2 ответа
TL; DR: DSB, по-видимому, способен доставлять только один скачок внутреннего цикла каждый второй цикл. Также переключатели DSB-MITE составляют до 9% времени выполнения.
Введение - Часть 1. Понимание событий производительности LSD
Сначала я расскажу, когда LSD.UOPS а также LSD.CYCLES_ACTIVE Происходят события производительности и некоторые особенности ЛСД на микроархитектурах IvB и SnB. Как только мы установим это основание, мы сможем ответить на вопрос. Для этого мы можем использовать небольшие фрагменты кода, которые специально предназначены для точного определения, когда происходят эти события.
Согласно документации:
LSD.UOPS: Количество мопов, доставленных ЛСД.LSD.CYCLES_ACTIVE: Циклы Uops, доставленные LSD, но не от декодера.
Эти определения полезны, но, как вы увидите позже, недостаточно точны, чтобы ответить на ваш вопрос. Важно лучше понять эти события. Некоторая информация, представленная здесь, не документирована Intel, и это только моя лучшая интерпретация эмпирических результатов и некоторых связанных с ними патентов, которые я получил. Хотя мне не удалось найти конкретный патент, который описывает реализацию LSD в микроархитектурах SnB или более поздних.
Каждый из следующих тестов начинается с комментария, который содержит название теста. Все числа нормированы за итерацию, если не указано иное.
; B1
----------------------------------------------------
mov rax, 100000000
.loop:
dec rax
jnz .loop
----------------------------------------------------
Metric | IvB | SnB
----------------------------------------------------
cycles | 0.90 | 1.00
LSD.UOPS | 0.99 | 1.99
LSD.CYCLES_ACTIVE | 0.49 | 0.99
CYCLE_ACTIVITY.CYCLES_NO_EXECUTE | 0.00 | 0.00
UOPS_ISSUED.STALL_CYCLES | 0.43 | 0.50
Обе инструкции в теле цикла объединены в одну строку. На IvB и SnB есть только один порт выполнения, который может выполнять команды перехода. Следовательно, максимальная пропускная способность должна составлять 1 с /iter. IvB на 10% быстрее, хотя, по некоторым причинам.
Согласно Уменьшается ли производительность при выполнении циклов, чей счетчик числа операций не кратен ширине процессора? LSD в IvB и SnB не может выдавать мопы через границы тела цикла, даже если есть доступные слоты выдачи. Поскольку цикл содержит один моп, мы ожидаем, что LSD будет выдавать один моп за цикл, и что LSD.CYCLES_ACTIVE должно примерно равняться общему количеству циклов.
На IvB, LSD.UOPS как и ожидалось. То есть ЛСД будет выдавать один моп за цикл. Обратите внимание, что, поскольку число циклов равно количеству итераций, которое равно количеству мопов, мы можем эквивалентно сказать, что LSD выдает один моп на одну итерацию. По сути, большинство выполненных мопов было выпущено из ЛСД. Тем не мение, LSD.CYCLES_ACTIVE составляет около половины числа циклов. Как это возможно? В этом случае не должна ли быть выдана только половина от общего числа мопов из ЛСД? Я думаю, что здесь происходит то, что цикл по существу разворачивается дважды, и за цикл выдается два мопа. Тем не менее, только один моп может быть выполнен за цикл еще RESOURCE_STALLS.RS ноль, указывая, что RS никогда не заполняется. Тем не мение, RESOURCE_STALLS.ANY составляет около половины отсчета цикла. Собирая все это вместе сейчас, кажется, что ЛСД фактически выдает 2 мопа через каждый второй цикл, и что есть некоторые структурные ограничения, которые достигаются через каждый второй цикл. CYCLE_ACTIVITY.CYCLES_NO_EXECUTE подтверждает, что в каждом цикле всегда есть хотя бы один read uop в RS. Следующие эксперименты покажут условия для развертывания.
На СнБ, LSD.UOPS показывает, что от ЛСД было выпущено вдвое больше общего количества мопов. Также LSD.CYCLES_ACTIVE указывает на то, что ЛСД был активен большую часть времени. CYCLE_ACTIVITY.CYCLES_NO_EXECUTE а также UOPS_ISSUED.STALL_CYCLES как на IvB. Следующие эксперименты помогают понять, что происходит. Кажется, что измеряется LSD.CYCLES_ACTIVE равен реальному LSD.CYCLES_ACTIVE + RESOURCE_STALLS.ANY, Поэтому, чтобы получить реальное LSD.CYCLES_ACTIVE, RESOURCE_STALLS.ANY должны быть вычтены из измеренного LSD.CYCLES_ACTIVE, То же самое относится и к LSD.CYCLES_4_UOPS, Реальный LSD.UOPS можно рассчитать следующим образом:
LSD.UOPS измеряется = LSD.UOPS реальный + ((LSD.UOPS измерено / LSD.CYCLES_ACTIVE измерено) * RESOURCE_STALLS.ANY)
Таким образом,
LSD.UOPS реальный = LSD.UOPS измеряется - ((LSD.UOPS измерено / LSD.CYCLES_ACTIVE измерено) * RESOURCE_STALLS.ANY)
знак равно LSD.UOPS измерено * (1 - (RESOURCE_STALLS.ANY / LSD.CYCLES_ACTIVE размеренный))
Для всех тестов, которые я выполнял на SnB (включая те, которые здесь не показаны), эти корректировки являются точными.
Обратите внимание, что RESOURCE_STALLS.RS а также RESOURCE_STALLS.ANY на SnB так же, как IvB. Таким образом, кажется, что ЛСД работает так же, как этот конкретный тест, на IvB и SnB, за исключением того, что события LSD.UOPS а также LSD.CYCLES_ACTIVE считаются по-разному.
; B2
----------------------------------------------------
mov rax, 100000000
mov rbx, 0
.loop:
dec rbx
jz .loop
dec rax
jnz .loop
----------------------------------------------------
Metric | IvB | SnB
----------------------------------------------------
cycles | 1.98 | 2.00
LSD.UOPS | 1.92 | 3.99
LSD.CYCLES_ACTIVE | 0.94 | 1.99
CYCLE_ACTIVITY.CYCLES_NO_EXECUTE | 0.00 | 0.00
UOPS_ISSUED.STALL_CYCLES | 1.00 | 1.00
В В2 на каждую итерацию приходится 2 мопа, и оба являются прыжками. Первый никогда не берется, поэтому остается только один цикл. Мы ожидаем, что он будет работать на 2c / iter, что действительно так. LSD.UOPS показывает, что большинство мопов были выпущены из ЛСД, но LSD.CYCLES_ACTIVE показывает, что ЛСД был активен только половину времени. Это означает, что цикл не был развернут. Таким образом, кажется, что развертывание происходит только тогда, когда в цикле есть один моп.
; B3
----------------------------------------------------
mov rax, 100000000
.loop:
dec rbx
dec rax
jnz .loop
----------------------------------------------------
Metric | IvB | SnB
----------------------------------------------------
cycles | 0.90 | 1.00
LSD.UOPS | 1.99 | 1.99
LSD.CYCLES_ACTIVE | 0.99 | 0.99
CYCLE_ACTIVITY.CYCLES_NO_EXECUTE | 0.00 | 0.00
UOPS_ISSUED.STALL_CYCLES | 0.00 | 0.00
Здесь также есть 2 мопа, но первый - мультивыключение ALU с одним циклом, которое не связано с мега прыжком. B3 помогает нам ответить на следующие два вопроса:
- Если цель прыжка не является прыжком, будет ли
LSD.UOPSа такжеLSD.CYCLES_ACTIVEеще дважды рассчитывать на SnB? - Если цикл содержит 2 мопа, где только один из них является прыжком, будет ли LSD развернуть цикл?
B3 показывает, что ответом на оба вопроса является "Нет".
UOPS_ISSUED.STALL_CYCLES предполагает, что LSD остановит только один цикл, если он выдаст два прыжковых мопа за один цикл. Этого никогда не происходит в B3, поэтому там нет киосков.
; B4
----------------------------------------------------
mov rax, 100000000
.loop:
add rbx, qword [buf]
dec rax
jnz .loop
----------------------------------------------------
Metric | IvB | SnB
----------------------------------------------------
cycles | 0.90 | 1.00
LSD.UOPS | 1.99 | 2.00
LSD.CYCLES_ACTIVE | 0.99 | 1.00
CYCLE_ACTIVITY.CYCLES_NO_EXECUTE | 0.00 | 0.00
UOPS_ISSUED.STALL_CYCLES | 0.00 | 0.00
B4 имеет дополнительный поворот к нему; он содержит 2 мопа в объединенном домене, но 3 мопа в объединенном домене, потому что инструкция load-ALU становится непригодной для RS. В предыдущих бенчмарках не было микросопливных мопов, только макроплавленные мопы. Цель здесь - увидеть, как ЛСД относится к микрозонкам.
LSD.UOPS показывает, что два мопа команды load-ALU заняли один слот проблемы (слитый прыжковый моп потребляет только один слот). Также с LSD.CYCLES_ACTIVE равно cycles Развертывание не произошло. Пропускная способность цикла соответствует ожидаемой.
; B5
----------------------------------------------------
mov rax, 100000000
.loop:
jmp .next
.next:
dec rax
jnz .loop
----------------------------------------------------
Metric | IvB | SnB
----------------------------------------------------
cycles | 2.00 | 2.00
LSD.UOPS | 1.91 | 3.99
LSD.CYCLES_ACTIVE | 0.96 | 1.99
CYCLE_ACTIVITY.CYCLES_NO_EXECUTE | 0.00 | 0.00
UOPS_ISSUED.STALL_CYCLES | 1.00 | 1.00
B5 - последний тест, который нам понадобится. Это похоже на В2 в том, что оно содержит два ветвления. Тем не менее, один из прыжков в B5 - это безусловный прыжок вперед. Результаты идентичны B2, что указывает на то, что не имеет значения, является ли прыжковый переход условным или нет. Это также тот случай, если первый прыжок является условным, а второй - нет.
Введение. Часть 2. Прогнозирование ветвей в ЛСД.
LSD - это механизм, реализованный в очереди UOP (IDQ), который может улучшить производительность и снизить энергопотребление (следовательно, уменьшается тепловыделение). Это может повысить производительность, поскольку некоторые ограничения, существующие в интерфейсе, могут быть ослаблены в очереди uop. В частности, на SnB и IvB максимальная пропускная способность каналов MITE и DSB составляет 4 мегапикселя / с, но в байтах - 16 Б / с и 32 Б / с соответственно. Пропускная способность очереди uop также равна 4uops/c, но не имеет ограничений по количеству байтов. Пока LSD выдает мопы из очереди мопов, внешний интерфейс (т. Е. Блоки выборки и декодирования) и даже ненужная логика ниже по потоку от IDQ могут быть отключены. До Nehalem, LSD был реализован в блоке IQ. Начиная с Haswell, LSD поддерживает циклы, которые содержат мопы из MSROM. LSD в процессорах Skylake отключен, потому что, по-видимому, он глючит.
Петли обычно содержат хотя бы одну условную ветвь. ЛСД по существу отслеживает обратные условные переходы и пытается определить последовательность мопов, составляющих цикл. Если LSD требуется слишком много времени для обнаружения петли, производительность может ухудшиться, а мощность может быть потеряна. С другой стороны, если ЛСД преждевременно блокирует цикл и пытается воспроизвести его, условный переход цикла может фактически провалиться. Это может быть обнаружено только после выполнения условного перехода, что означает, что более поздние мопы, возможно, уже были отправлены и отправлены для выполнения. Все эти мопы должны быть сброшены, а внешний интерфейс должен быть активирован для получения мопов с правильного пути. Таким образом, может быть значительное снижение производительности, если улучшение производительности от использования LSD не превышает ухудшение производительности в результате потенциально неправильного прогнозирования последнего выполнения условной ветви, где завершается цикл.
Мы уже знаем, что единица предсказания ветвления (BPU) в SnB и более поздних версиях может правильно предсказать, когда условная ветвь цикла проваливается, когда общее число итераций не превышает некоторого небольшого числа, после чего BPU предполагает, что цикл будет повторяться навсегда. Если LSD использует сложные возможности BPU для прогнозирования прекращения блокировки, он должен иметь возможность правильно прогнозировать те же случаи. Возможно также, что LSD использует свой собственный предиктор ветвления, который потенциально намного проще. Давайте разберемся.
mov rcx, 100000000/(IC+3)
.loop_outer:
mov rax, IC
mov rbx, 1
.loop_inner:
dec rax
jnz .loop_inner
dec rcx
jnz .loop_outer
Позволять OC а также IC обозначим количество внешних итераций и количество внутренних итераций соответственно. Они связаны следующим образом:
OC = 100000000 / (IC +3) где IC > 0
Для любого данного IC общее количество выбывших мопов одинаково. Кроме того, число мопов в слитом домене равно количеству мопов в неиспользованном домене. Это хорошо, потому что это действительно упрощает анализ и позволяет нам проводить справедливое сравнение производительности между различными значениями IC,
По сравнению с кодом из вопроса есть дополнительная инструкция, mov rbx, 1, так что общее число мопов во внешнем цикле равно 4 Это позволяет нам использовать LSD.CYCLES_4_UOPS событие производительности в дополнение к LSD.CYCLES_ACTIVE а также BR_MISP_RETIRED.CONDITIONAL, Обратите внимание, что поскольку существует только один порт выполнения ветви, каждая итерация внешнего цикла занимает не менее 2 циклов (или, согласно таблице Агнера, 1-2 цикла). См. Также: Может ли ЛСД выдавать uOP от следующей итерации обнаруженного цикла?,
Общее количество прыжков:
OC + IC * OC = 100M / (IC +3) + IC * 100M / (IC +3)
= 100M (IC + 1) / (IC +3)
Предполагая, что максимальная пропускная способность скачкообразного перехода равна 1 за цикл, оптимальное время выполнения составляет 100M (IC + 1) / (IC +3) циклы. На IvB мы можем вместо этого использовать максимальную пропускную способность при прыжке 0,9/c, если мы хотим быть строгими. Было бы полезно разделить это на количество внутренних итераций:
OPT = (100M (IC + 1) / (IC +3)) / (100 млн IC / (IC +3)) =
100M (IC +1) * (IC +3) / (IC +3) * 100М IC знак равно
(IC + 1) / IC = 1 + 1 / IC
Следовательно, 1 < OPT <= 1,5 для IC > 1. Человек, разрабатывающий ЛСД, может использовать это для сравнения различных конструкций ЛСД. Мы также будем использовать это в ближайшее время. Другими словами, оптимальная производительность достигается, когда общее количество циклов, деленное на общее количество переходов, равно 1 (или 0,9 на IvB).
Предполагая, что прогноз для двух скачков независимы и учитывая, что jnz .loop_outer легко предсказуемо, производительность зависит от прогноза jnz .loop_inner, При неправильном предсказании, которое меняет управление на uop вне заблокированного цикла, LSD завершает цикл и пытается обнаружить другой цикл. ЛСД может быть представлен как конечный автомат с тремя состояниями. В одном состоянии ЛСД ищет циклическое поведение. Во втором состоянии ЛСД изучает границы и количество итераций цикла. В третьем состоянии ЛСД воспроизводит цикл. Когда цикл существует, состояние изменяется с третьего на первое.
Как мы узнали из предыдущего набора экспериментов, на SnB будут дополнительные события ЛСД, когда возникнут связанные с бэкэндом киоски с проблемами. Таким образом, цифры должны быть поняты соответственно. Обратите внимание, что случай, когда IC = 1 не был протестирован в предыдущем разделе. Это будет обсуждаться здесь. Напомним также, что как на IvB, так и на SnB внутренний цикл может быть развернут. Внешний цикл никогда не будет развернут, потому что он содержит более одного мопа. Кстати, LSD.CYCLES_4_UOPS работает как положено (извините, никаких сюрпризов).
Следующие цифры показывают необработанные результаты. Я только показал результаты до IC = 13 и IC = 9 на IvB и SnB соответственно. В следующем разделе я расскажу, что происходит для больших значений. Обратите внимание, что когда знаменатель равен нулю, значение не может быть вычислено и поэтому не отображается.
LSD.UOPS/100M это отношение количества выполненных мсек из ЛСД к общему количеству мопов. LSD.UOPS/OC является средним числом мопов, выпущенных из LSD за внешнюю итерацию. LSD.UOPS/(OC*IC) является средним числом мопов, выпущенных из LSD за внутреннюю итерацию. BR_MISP_RETIRED.CONDITIONAL/OC это среднее число отклоненных условных ветвлений, которые были ошибочно предсказаны за внешнюю итерацию, которое для всех IvB и SnB явно равно нулю для всех IC,
За IC = 1 на IvB, все мопы были выпущены из ЛСД. Внутренняя условная ветвь всегда не берется. LSD.CYCLES_4_UOPS/LSD.CYCLES_ACTIVE Показатель, показанный на втором рисунке, показывает, что во всех циклах, в которых активен LSD, LSD выдает 4 мопа за цикл. Из предыдущих экспериментов мы узнали, что когда LSD выдает 2 прыжковых мопа в одном цикле, он не может выдавать прыжковые мопы в следующем цикле из-за некоторых структурных ограничений, поэтому он остановится. LSD.CYCLES_ACTIVE/cycles показывает, что ЛСД останавливается (почти) каждый второй цикл. Мы ожидаем, что для выполнения внешней итерации потребуется около 2 циклов, но cycles показывает, что требуется около 1,8 циклов. Вероятно, это связано с пропускной способностью 0,9 на Uv, которую мы видели ранее.
Дело IC = 1 на SnB похож, за исключением двух вещей. Во-первых, внешний цикл фактически занимает 2 цикла, как и ожидалось, а не 1.8. Во-вторых, все три количества ЛСД событий вдвое превышают ожидаемые. Они могут быть скорректированы, как обсуждалось в предыдущем разделе.
Прогноз ветвления особенно интересен, когда IC > 1. Давайте проанализируем IC = 2 случая в деталях. LSD.CYCLES_ACTIVE а также LSD.CYCLES_4_UOPS Покажите, что примерно в 32% всех циклов ЛСД активен, а в 50% этих циклов ЛСД выдает 4 мопа за цикл. Таким образом, существуют либо неправильные прогнозы, либо то, что LSD занимает много времени в состоянии обнаружения цикла или в состоянии обучения. Тем не менее, cycles / (OC * IC) составляет около 1,6, или, другими словами, cycles / jumps 1,07, что близко к оптимальной производительности. Трудно понять, какие мопы выпускаются в группах по 4 из ЛСД и какие мопы выпускаются в группах размером менее 4 из ЛСД. На самом деле, мы не знаем, как ЛСД события учитываются при наличии ложных прогнозов. Потенциальное развертывание добавляет еще один уровень сложности. Количество событий LSD можно рассматривать как верхние границы для полезных мопов, выпущенных ЛСД, и циклов, в которых ЛСД выдавал полезные мопы.
Как IC увеличить, оба LSD.CYCLES_ACTIVE а также LSD.CYCLES_4_UOPS снижение и производительность ухудшается медленно, но последовательно (помните, что cycles / (OC * IC) следует сравнивать с OPT). Это как если бы последняя итерация внутреннего цикла была неправильно предсказана, но ее штраф за неправильное предсказание увеличивается с IC, Обратите внимание, что BPU всегда правильно предсказывает количество итераций внутреннего цикла.
Ответ
Я буду обсуждать, что происходит для любого IC почему производительность ухудшается для большего IC и каковы верхние и нижние границы производительности. В этом разделе будет использоваться следующий код:
mov rcx, 100000000/(IC+2)
.loop_outer:
mov rax, IC
.loop_inner:
dec rax
jnz .loop_inner
dec rcx
jnz .loop_outer
По сути это то же самое, что и код из вопроса. Единственное отличие состоит в том, что количество внешних итераций настраивается так, чтобы поддерживать одинаковое количество динамических мопов. Обратите внимание, что LSD.CYCLES_4_UOPS в этом случае бесполезен, потому что у LSD никогда не будет 4 мопов для выдачи в любом цикле. Все приведенные ниже цифры предназначены только для IvB. Не беспокойтесь, однако, как SnB отличается, будет упомянуто в тексте.
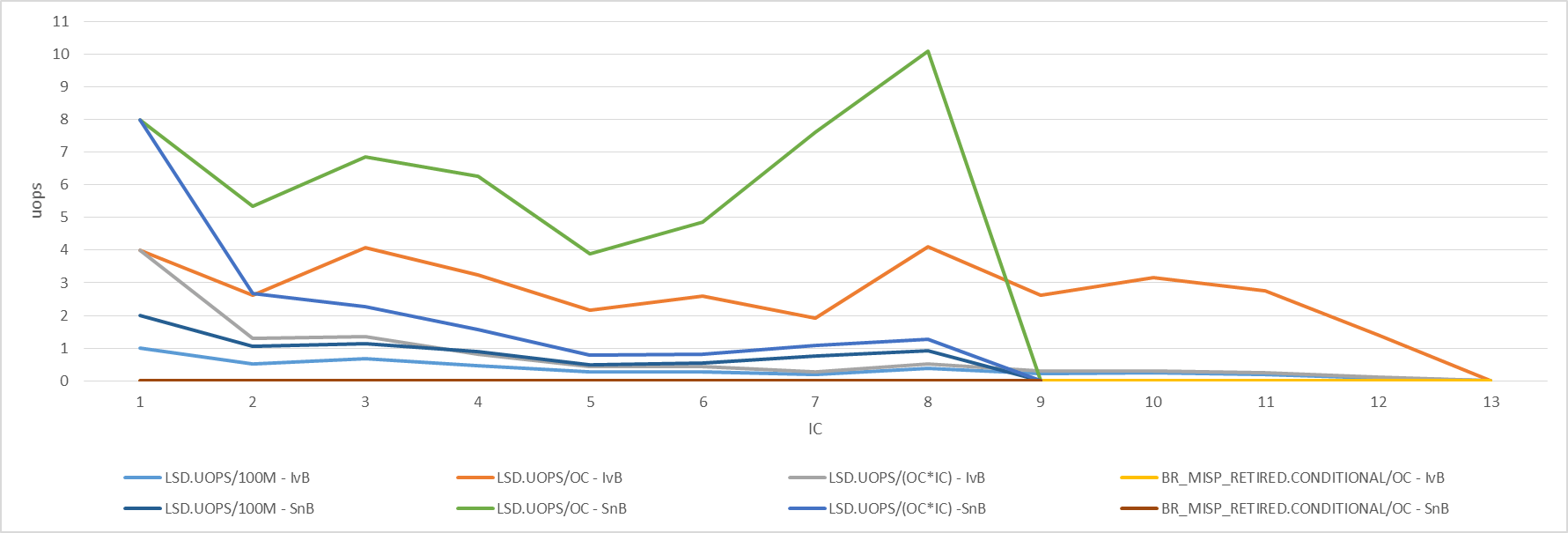
когда IC = 1, cycles / прыжки составляет 0,7 (1,0 на SnB), что даже ниже, чем 0,9. Я не знаю, как достигается эта пропускная способность. Производительность уменьшается при больших значениях IC, что коррелирует с уменьшением активных циклов ЛСД. когда IC =13-27 (9-27 на SnB), ноль мопов выдаются из ЛСД. Я думаю, что в этом диапазоне LSD считает, что влияние на производительность из-за неправильного прогнозирования последней внутренней итерации больше некоторого порога, он решает никогда не блокировать цикл и запоминает свое решение. когда IC <13, ЛСД выглядит агрессивным и, возможно, считает цикл более предсказуемым. За IC >27 количество активных циклов ЛСД медленно растет, что коррелирует с постепенным улучшением производительности. Хотя не показано на рисунке, как IC растет далеко за пределы 64, большинство мопов будет поступать из ЛСД и cycles / скачки устанавливается на 0,9.
Результаты по ассортименту IC = 13-27 особенно полезно. Циклы задержки выдачи составляют примерно половину общего числа циклов и также равны циклам задержки отправки. Именно по этой причине внутренний цикл выполняется на 2.0c/iter; потому что прыжки мопов внутреннего цикла выдается / отправляется каждый второй цикл. Когда LSD не активен, мопы могут поступать из DSB, MITE или MSROM. Ассистенты микрокода не требуются для нашего цикла, поэтому, возможно, есть ограничение в DSB, MITE или в обоих. Мы можем дополнительно исследовать, чтобы определить, где ограничения используют события производительности внешнего интерфейса. Я сделал это, и результаты показывают, что около 80-90% всех мопов происходят из DSB. Сам DSB имеет много ограничений, и кажется, что цикл поражает их. Кажется, что DSB занимает 2 цикла, чтобы доставить прыжок, который нацеливается на себя. Кроме того, для полной IC В диапазоне, задержки из-за переключения MITE-DSB составляют до 9% всех циклов. Опять же, причина этих коммутаторов связана с ограничениями в самой DSB. Обратите внимание, что до 20% доставляется с пути MITE. Предполагая, что значения uops не превышают полосу пропускания 16B/c пути MITE, я думаю, что цикл был бы выполнен со скоростью 1c/iter, если бы не было DSB.
На приведенном выше рисунке также показана частота неверного прогнозирования BPU (за итерацию внешнего цикла). На IvB это ноль для IC =1-33, кроме случаев, когда IC =21, 0-1, когда IC =34-45, и это ровно 1, когда IC >46. На SnB это ноль для IC = 1-33 и 1 в противном случае.
(Частичный ответ / предположение, что я не закончил писать до того, как Хади опубликовал подробный анализ; часть этого продолжается из комментариев)
Утверждение Агнера, что "буфер цикла не имеет измеримого эффекта в тех случаях, когда кэш UOP не является узким местом..." неверно? Потому что это, безусловно, измеримый эффект, и кэш-память UOP не является узким местом, поскольку кэш-память имеет емкость ~1,5 КБ.
Да, Агнер называет это буфером обратной связи. Его утверждение заключается в том, что добавление ЛСД в дизайн не ускоряет код. Но да, это кажется неправильным для очень узких циклов, по крайней мере для вложенных циклов. Очевидно SnB/IvB действительно нуждается в буфере цикла, чтобы выпустить или выполнить циклы 1c / iter. Если микроархитектурное узкое место заключается в извлечении мопов из кеша мопов после ветвления, и в этом случае его предостережение покрывает это.
Есть и другие случаи, кроме пропусков uop-cache, когда чтение uop-кэша может быть узким местом. например, если моп не очень хорошо упакован из-за эффектов выравнивания, или если они используют большие непосредственные значения и / или смещения, которые требуют дополнительных циклов для чтения из кеша мопов. См. Раздел "Песчаный мост" руководства по поиску Агнера Фога для получения более подробной информации об этих эффектах. Ваше предположение о том, что емкость (до 1,5 тыс. Моп, если они идеально упакованы) является единственной причиной, по которой она может быть медленной, очень ошибочно.
Кстати, обновление микрокода для Skylake полностью отключило LSD, чтобы исправить ошибку слияния с частичным регистром, ошибку SKL150 1, и это фактически не имело никакого эффекта, за исключением случаев, когда крошечный цикл охватывает границу 32B и требует 2 строки кэша.
Но Агнер списки JMP rel8/32 и взял пропускную способность JCC как 1-2 цикла на HSW/SKL, против 2 на IvB. Так что что-то о взятых ветвях могло ускориться после IvB, кроме самого ЛСД.
Там может быть какая-то часть (и) ЦП, кроме LSD, которая также имеет особый случай для длительных крошечных циклов, которые позволяют им запускать 1 сделанный прыжок за такт на Haswell и позже. Я не проверял, какие условия вызывают пропускную способность ветвления 1 на 2 цикла в HSW/SKL. Также обратите внимание, что Агнер измерял перед обновлением микрокода для ошибки SKL150.
сноска 1: См. Как именно выполняют частичные регистры на Haswell/Skylake? Написание AL, похоже, ложно зависит от RAX, а AH несовместимо, и обратите внимание, что SKX и Kaby Lake поставляются с микрокодом, который уже включает это. Наконец, он снова включен в Coffee Lake, что исправило ошибочную аппаратную логику, так что LSD можно безопасно включить снова. https://en.wikichip.org/wiki/intel/microarchitectures/coffee_lake