Почему IO 99,99 %, хотя чтение и запись на диск кажется очень маленьким
Один из наших брокеров Kafka имел очень высокую среднюю нагрузку (в среднем около 8) на 8-ядерном компьютере. Хотя это должно быть хорошо, но наш кластер, похоже, все еще сталкивается с проблемами, и производители не могли сбрасывать сообщения в обычном темпе.
После дальнейшего изучения я обнаружил, что мой Java-процесс слишком долго ждал ввода-вывода, почти 99,99% времени, и на данный момент я считаю, что это проблема.
Помните, что это происходило даже тогда, когда нагрузка была относительно низкой (около 100–150 Кбит / с), я видел, что она отлично работает даже при вводе данных в кластер со скоростью 2 Мбит / с.
Я не уверен, является ли эта проблема из-за Кафки, я предполагаю, что это не потому, что все другие брокеры работали хорошо в течение этого времени, и наши данные отлично разделены между 5 брокерами.
Пожалуйста, помогите мне найти причину проблемы. Куда мне обратиться, чтобы найти проблему? Есть ли другие инструменты, которые могут помочь мне отладить эту проблему?
Мы используем установленный том EBS объемом 1 ТБ на большой машине m5.2x.
Пожалуйста, не стесняйтесь задавать любые вопросы.
GC Logs Snapshot 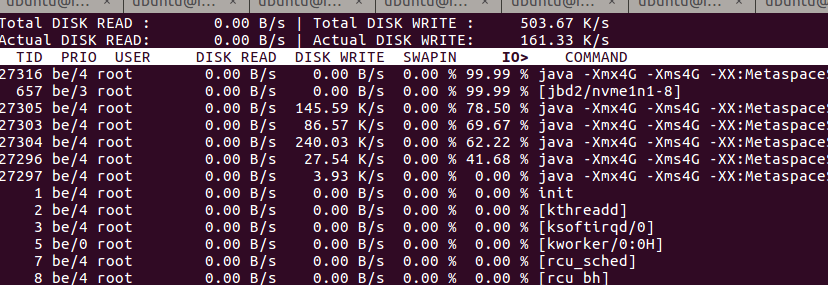
1 ответ
Отвечая на мой собственный вопрос после выяснения проблемы.
Оказывается, что настоящая проблема была связана с тем, как работает жесткий диск st1, а не с kafka или GC.
Тип тома жесткого диска st1 оптимизирован для рабочих нагрузок с большим последовательным вводом-выводом и очень плохо работает с небольшими случайными ввода-выводами. Вы можете прочитать больше об этом здесь. Хотя это должно было работать нормально только для Kafka, но мы записывали журналы приложений Kafka на тот же жесткий диск, который много добавлял к операциям ввода-вывода READ/WRITE и впоследствии очень быстро истощал наши пакетные кредиты в пиковое время. Наш кластер работал нормально до тех пор, пока у нас были доступные кредиты и производительность снизилась после того, как кредиты истощились.
Есть несколько решений этой проблемы:
- Сначала удалите все внешние приложения, добавляющие нагрузку ввода-вывода на диск st1, так как они не предназначены для небольших случайных операций ввода-вывода.
- Увеличение количества таких параллельных дисков st1 делит нагрузку. Это легко сделать с помощью Kafka, поскольку она позволяет нам хранить данные в разных каталогах на разных дисках. Но только новые темы будут разделены, поскольку разделы назначаются каталогам при создании темы.
- Используйте жесткие диски gp2, поскольку они отлично справляются с обоими видами нагрузки. Но это дорого.
- Используйте диски большего размера st1, подходящие для вашего варианта использования, так как пропускная способность и размер пакета зависят от размера диска. ЧИТАЙТЕ ЗДЕСЬ
Эта статья очень помогла мне разобраться в проблеме.
Благодарю.