Как получить группировку прямо в R с помощью Plotly
У меня есть некоторые проблемы, чтобы сгруппировать мои данные в Plotly под R. Для начала я использовал локальные данные из CSV-файла, читая их с помощью:
geogrid_data <- read.delim('geogrid.csv', row.names = NULL, stringsAsFactors = TRUE)
и заговор прошел хорошо, используя следующее:
library(plotly)
library(RColorBrewer)
x <- list(
title = 'Date'
)
p <- plotly::plot_ly(geogrid_data,
type = 'scatter',
x = ~ts_now,
y = ~absolute_v_sum,
text = paste('Table: ', geogrid_data$table_name,
'<br>Absolute_v_Sum: ', geogrid_data$absolute_v_sum),
hoverinfo = 'text',
mode = 'lines',
color = list(
color = colorRampPalette(RColorBrewer::brewer.pal(11,'Spectral'))(
length(unique(geogrid_data$table_name))
)
),
transforms = list(
list(
type = 'groupby',
groups = ~table_name
)
)
) %>% layout(showlegend = TRUE, xaxis = x)
Вот вывод:
Затем я собирался изменить источник данных в таблице базы данных Oracle, читая данные следующим образом, используя пакет ROracle:
# retrieve data into resultSet object
rs <- dbSendQuery(con, "SELECT * FROM GEOGRID_STATS")
# fetch records from the resultSet into a data.frame
geogrid_data <- fetch(rs)
# free resources occupied by resultSet
dbClearResult(rs)
dbUnloadDriver(drv)
# remove duplicates from dataframe (based on TABLE_NAME, TS_BEFORE, TS_NOW, NOW_SUM)
geogrid_data <- geogrid_data %>% distinct(TABLE_NAME, TS_BEFORE, TS_NOW, NOW_SUM, .keep_all = TRUE)
# alter date columns in place
geogrid_data$TS_BEFORE <- as.Date(geogrid_data$TS_BEFORE, format='%d-%m-%Y')
geogrid_data$TS_NOW <- as.Date(geogrid_data$TS_NOW, format='%d-%m-%Y')
и корректируя график для:
p <- plotly::plot_ly(
type = 'scatter',
x = geogrid_data$TS_NOW,
y = geogrid_data$ABSOLUTE_V_SUM,
text = paste('Table: ', geogrid_data$TABLE_NAME,
'<br>Absolute_v_Sum: ', geogrid_data$ABSOLUTE_V_SUM,
'<br>Date: ', geogrid_data$TS_NOW),
hoverinfo = 'text',
mode = 'lines',
color = list(
color = colorRampPalette(RColorBrewer::brewer.pal(11,'Spectral'))(
length(unique(geogrid_data$TABLE_NAME))
)
),
transforms = list(
list(
type = 'groupby',
groups = geogrid_data$TABLE_NAME
)
)
) %>% layout(showlegend = TRUE, xaxis = x)
К сожалению, это приводит к некоторой проблеме с группировкой, как кажется.
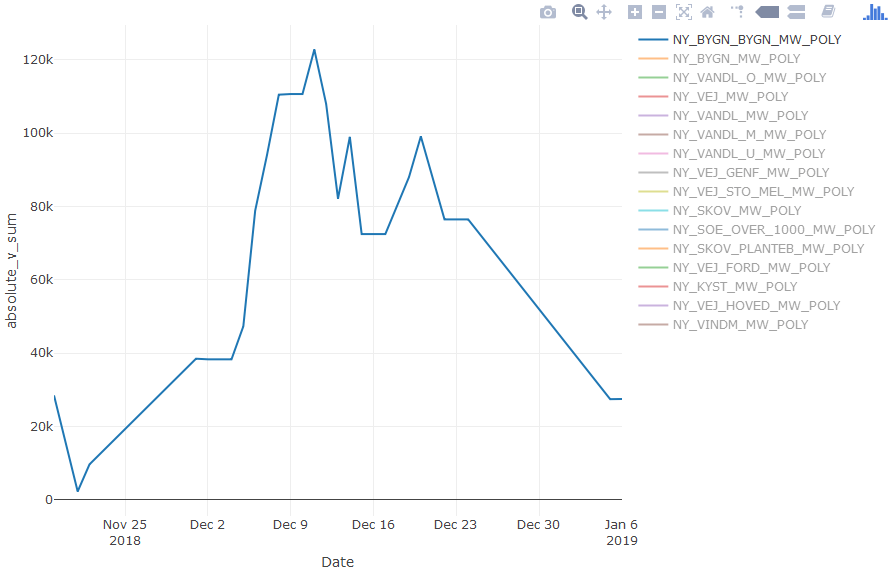
Как видно из текста метки при наведениикурсора на точку данных, точка представляет данные из NY_SKOV_PLANTEB_MW_POLY, а легенда настроена на отображение данных из NY_BYGN_MW_POLY. Глядя на другие точки данных на этом графике, я обнаружил дикое сочетание точек всех видов на этом графике, некоторые из которых представляют данные NY_BYGN_MW_POLY, большинство из которых нет.
Кроме того, построение графика относительно временной шкалы больше не работает, например, данные строятся с началом 11 декабря - 10 декабря - 10 декабря - 12 декабря - 20 декабря - 17 декабря - 16 декабря - 15 декабря
Где я могу ошибиться при обработке данных, и что я должен сделать, чтобы сделать это правильно?
1 ответ
Конечно, нужно посмотреть на данные... спасибо Марко, после твоего вопроса я посмотрел на свои данные.
Есть некоторые моменты, в которых я просто предполагал вещи. Причина, по которой все данные отображаются с данными из CSV-файла, проста. Вся информация, собранная вручную в файле CSV, поступила из информации в электронных письмах, которые были упорядочены по дате. Следовательно, я скомпилировал данные в CSV-файле, упорядоченный по дате, и у Plotly нет проблем с группировкой данных по table_name.
Посмотрев свои данные, я привел в порядок, сохранив только те данные, которые мне нужны для отображения на графике, и использовал dplyr для сортировки данных по времени.
geogrid_data <- dplyr::arrange(geogrid_data, TS_NOW)
Это только по времени, а не по времени и имени таблицы, потому что сортировка по имени таблицы в любом случае выполняется Plotly и оператором groupby.