Сглаживание мелкого списка в Python
Есть ли простой способ сгладить список итераций с помощью понимания списка или, если это не так, что бы вы все сочли лучшим способом сгладить такой мелкий список, как баланс производительности и читабельности?
Я пытался сгладить такой список с помощью понимания вложенного списка, например:
[image for image in menuitem for menuitem in list_of_menuitems]
Но я попал в беду NameError разнообразие там, потому что name 'menuitem' is not defined, Погуглив и поглядев на Stack Overflow, я получил желаемый результат с reduce заявление:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
Но этот метод довольно нечитаем, потому что мне это нужно list(x) позвонить туда, потому что х Джанго QuerySet объект.
Вывод:
Спасибо всем, кто внес вклад в этот вопрос. Вот краткое изложение того, что я узнал. Я также делаю это вики-сообществом на случай, если другие захотят добавить или исправить эти наблюдения.
Мое оригинальное сокращение является избыточным и лучше написано так:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
Это правильный синтаксис для понимания вложенного списка (Brilliant summary dF.!):
>>> [image for mi in list_of_menuitems for image in mi]
Но ни один из этих методов не так эффективен, как использование itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
И, как отмечает @cdleary, вероятно, лучше избегать магии * оператора, используя chain.from_iterable вот так:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
23 ответа
Если вы просто хотите перебрать упрощенную версию структуры данных и не нуждаетесь в индексируемой последовательности, рассмотрите itertools.chain и компанию.
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
Он будет работать на всем, что итерируется, что должно включать в себя итерацию Джанго QuerySet s, который, кажется, вы используете в вопросе.
Редактировать: В любом случае это, вероятно, так же хорошо, как и уменьшение, потому что сокращение будет иметь те же издержки, что и копирование элементов в расширяемый список. chain это (то же самое) будет нести, если вы запустите list(chain) в конце.
Мета-редактирование: На самом деле, это меньше накладных расходов, чем предложенное решение вопроса, потому что вы отбрасываете временные списки, которые вы создаете, когда вы расширяете оригинал временным.
Редактировать: как JF Себастьян говорит itertools.chain.from_iterable избегает распаковки, и вы должны использовать это, чтобы избежать * волшебство, но приложение timeit показывает незначительную разницу в производительности.
У вас почти есть это! Способ сделать понимание вложенного списка состоит в том, чтобы поместить for операторы в том же порядке, что и обычные вложенные for заявления.
Таким образом, это
for inner_list in outer_list:
for item in inner_list:
...
соответствует
[... for inner_list in outer_list for item in inner_list]
Так ты хочешь
[image for menuitem in list_of_menuitems for image in menuitem]
@ S.Lott: Вы вдохновили меня на создание приложения timeit.
Я полагал, что это также будет зависеть от количества разделов (количество итераторов в списке контейнеров) - в вашем комментарии не упоминалось, сколько было разделов из тридцати элементов. Этот сюжет сплющивает тысячи предметов за каждый проход, с разным количеством перегородок. Элементы равномерно распределены между перегородками.
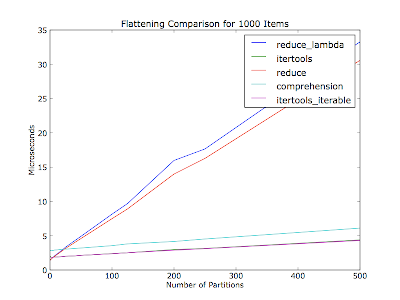
Код (Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
Изменить: Решил сделать это сообщество вики.
Замечания: METHODS Вероятно, следует собирать с декоратором, но я думаю, что людям было бы легче читать таким образом.
sum(list of lists, []) сгладит это.
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
Это решение работает для произвольной глубины вложения, а не только для глубины "списка списков", которой некоторые (все?) Другие решения ограничены:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
Это рекурсия, которая допускает произвольное вложение глубины - конечно, пока вы не достигнете максимальной глубины рекурсии...
В Python 2.6, используя chain.from_iterable():
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
Избегает создания промежуточного списка.
Результаты деятельности. Перераб.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
Я сплющил двухуровневый список из 30 предметов 1000 раз
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
Уменьшать всегда плохой выбор.
Там, кажется, путаница с operator.add! Когда вы добавляете два списка вместе, правильный термин для этого concat, не добавить. operator.concat это то, что вам нужно использовать.
Если вы думаете, функционально, это так просто, как это:
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
Вы видите, что Reduced уважает тип последовательности, поэтому, когда вы предоставляете кортеж, вы получаете обратно кортеж. давайте попробуем со списком::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Ага, вы получите список обратно.
Как насчет производительности::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable довольно быстрый! Но это не сравнить, чтобы уменьшить с Конкат.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
Вот правильное решение с использованием списочных представлений (они задом наперед):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
В вашем случае это будет
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
или вы могли бы использовать join и скажи
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
В любом случае, Гоча была вложением for петли.
От макушки головы можно избавиться от лямбды:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
Или даже исключить карту, так как у вас уже есть список-комп:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
Вы также можете просто выразить это как сумму списков:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
Эта версия является генератором. Настройте его, если вы хотите список.
def list_or_tuple(l):
return isinstance(l,(list,tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/tuple
def flatten(seq,predicate=list_or_tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
Вы можете добавить предикат, если хотите сгладить те, которые удовлетворяют условию
Взято из питонской кулинарной книги
Если вам нужно выстроить более сложный список с не повторяемыми элементами или с глубиной более 2, вы можете использовать следующую функцию:
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
Он вернет объект генератора, который вы можете преобразовать в список с помощью list() функция. Заметить, что yield from синтаксис доступен в python3.3, но вместо этого вы можете использовать явную итерацию.
Пример:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
Вот версия, работающая для нескольких уровней списка с использованием collectons.Iterable:
import collections
def flatten(o):
result = []
for i in o:
if isinstance(i, collections.Iterable):
result.extend(flatten(i))
else:
result.append(i)
return result
Если вы ищете встроенный, простой, однострочный, вы можете использовать:
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
возвращается
[1, 2, 3, 4, 5, 6]
По моему опыту, наиболее эффективный способ сгладить список списков:
flat_list = []
map(flat_list.extend, list_of_list)
Некоторые сравнения времени с другими предлагаемыми методами:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
Теперь прирост эффективности выглядит лучше при обработке более длинных списков:
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
И этот метод также работает с любым итеративным объектом:
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
Вы пытались сгладить? Из matplotlib.cbook.flatten (seq, scalarp =)?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
ОБНОВЛЕНИЕ Что дало мне другую идею:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Итак, чтобы проверить, насколько это эффективно, когда рекурсив становится глубже: насколько глубже?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Бьюсь об заклад "flattenlist" Я собираюсь использовать это вместо matploblib в течение длительного долгого времени, если я не хочу генератор доходности и быстрый результат, как "flatten" использует в matploblib.cbook
Это быстро.
- И вот код
:
typ=(list,tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
def flatten(items):
for i in items:
if hasattr(i, '__iter__'):
for m in flatten(i):
yield m
else:
yield i
Тестовое задание:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
Как насчет:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
Но Гвидо рекомендует не выполнять слишком много в одной строке кода, поскольку это снижает удобочитаемость. Существует минимальный выигрыш в производительности, если вы выполняете то, что вы хотите в одной строке против нескольких строк.
Простая альтернатива - использовать сцепление numpy, но оно преобразует содержимое в float:
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
Если каждый элемент в списке является строкой (и любые строки внутри этих строк используют " ", а не " ", вы можете использовать регулярные выражения (re модуль)
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
Приведенный выше код преобразует in_list в строку, использует регулярное выражение, чтобы найти все подстроки в кавычках (т.е. каждый элемент списка), и выплевывает их в виде списка.
Самый простой способ добиться этого в Python 2 или 3 - использовать библиотеку morph, используя pip install morph,
Код является:
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
В Python 3.4 вы сможете делать:
[*innerlist for innerlist in outer_list]