Конфигурация приложения Spark Streaming с помощью YARN
Я пытаюсь выжать каждый бит из моего кластера при настройке приложения spark, но, похоже, я не совсем все понимаю. Итак, я запускаю приложение в кластере AWS EMR с 1 главным и 2 базовыми узлами типа m3.xlarge(15 ГБ оперативной памяти и 4 vCPU для каждого узла). Это означает, что по умолчанию 11,25 ГБ зарезервировано на каждом узле для приложений, запланированных по пряже. Таким образом, главный узел используется только диспетчером ресурсов (пряжа), а это означает, что оставшиеся 2 основных узла будут использоваться для планирования приложений (поэтому у нас есть 22,5 ГБ для этой цели). Все идет нормально. Но здесь идет та часть, которую я не понимаю. Я запускаю приложение spark со следующими параметрами:
--driver-memory 4G --num-executors 4 --executor-cores 7 --executor-memory 4G
По моим представлениям (из того, что я нашел в качестве информации) это означает, что для драйвера будет выделено 4G, и 4 исполнителя будут запущены с 4G каждый из них. Таким образом, приблизительная оценка составляет 5*4=20 ГБ (давайте сделаем их 21 ГБ с ожидаемыми резервами памяти), что должно быть хорошо, поскольку у нас есть 22,5 ГБ для приложений. Вот скриншот из пользовательского интерфейса пряжи hadoop после запуска:
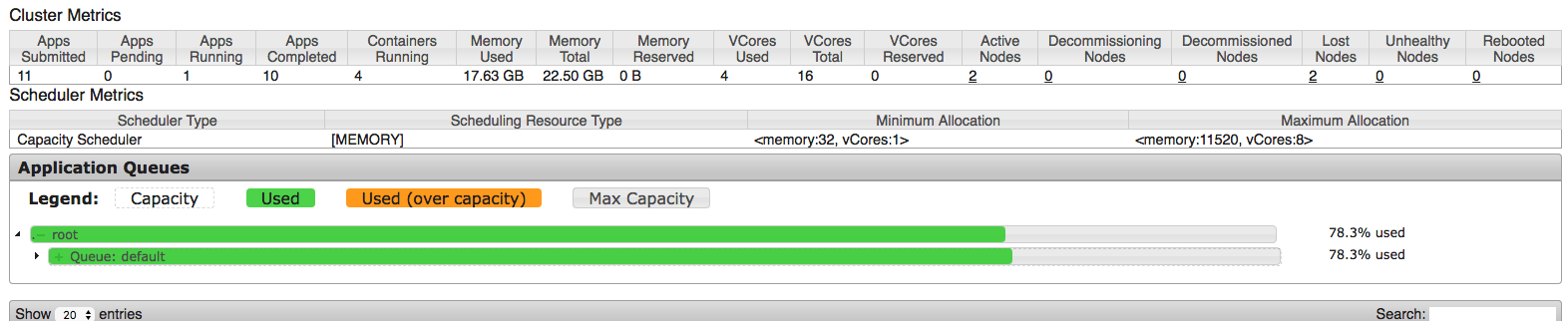
Мы можем видеть, что 17.63 используются приложением, но это немного меньше ожидаемого ~21G, и это вызывает первый вопрос: что здесь произошло?
Затем я перехожу на страницу исполнителей искрового интерфейса. Здесь возникает большой вопрос:
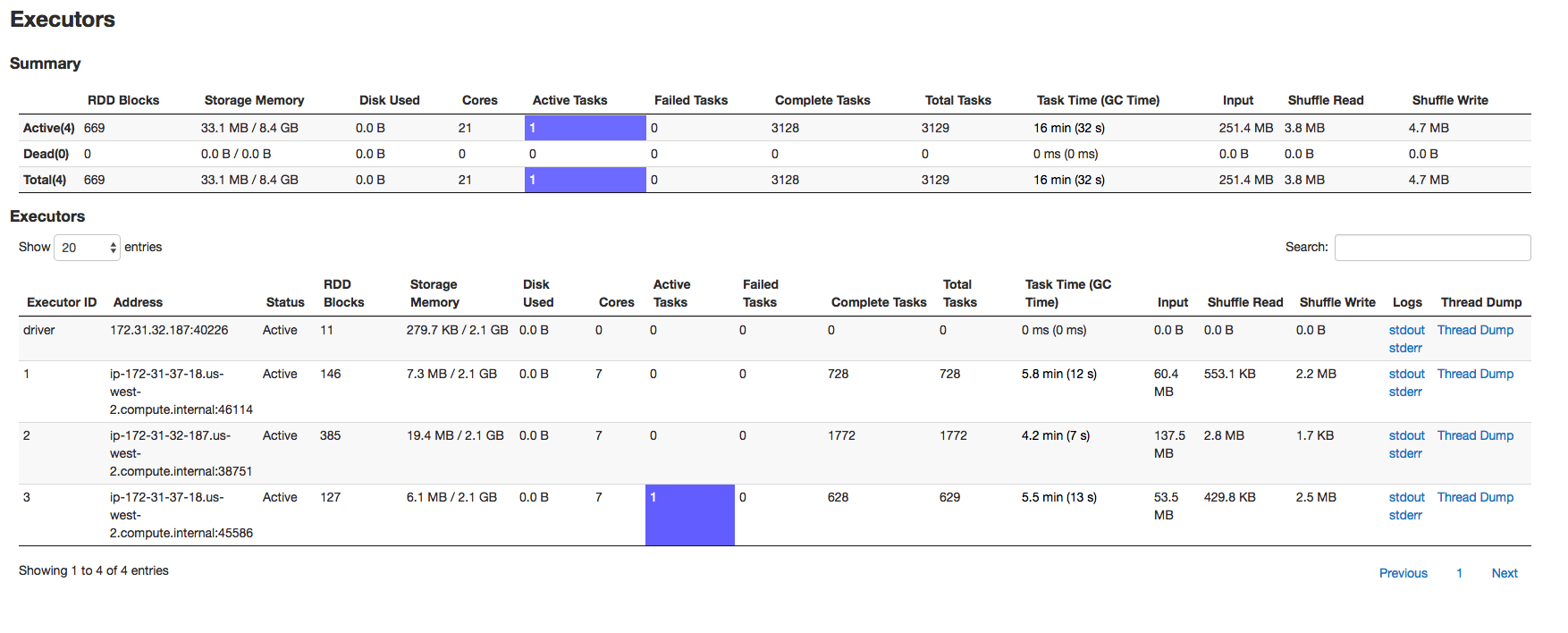
Исполнителей - 3(не 4), для них выделена память, а драйвер - 2,1 ГБ (не указано 4 ГБ). Итак, пряжа hadoop говорит, что используется 17,63G, а искра говорит, что выделено 8,4G. Итак, что здесь происходит? Связано ли это с планировщиком емкости (из документации я не смог прийти к такому выводу)?
1 ответ
Можете ли вы проверить, spark.dynamicAllocation.enabled включен Если это так, то приложение Spark может вернуть ресурсы кластеру, если они больше не используются. Минимальное количество исполнителей, которое будет запущено при запуске, будет определено spark.executor.instances,
Если это не так, каков ваш источник для приложения spark и какой размер раздела установлен для этого, spark будет буквально отображать размер раздела на ядра spark, если ваш источник имеет только 10 разделов, и когда вы пытаетесь выделить 15 ядер, он будет использовать только 10 ядер, потому что это то, что нужно. Я думаю, что это может быть причиной того, что spark запустил 3 исполнителя вместо 4. Что касается памяти, я бы порекомендовал пересмотреть, потому что вы запрашиваете 4 исполнителя и 1 драйвер с 4Gb каждый, который будет 5*4+5*384MB приблизительно равно 22GB и вы пытаетесь израсходовать все, и для вашей ОС и менеджера узлов осталось не так много, что было бы не идеальным способом.