Python time.clock() против точности time.time()?
Что лучше использовать для синхронизации в Python? time.clock() или time.time()? Какой из них обеспечивает большую точность?
например:
start = time.clock()
... do something
elapsed = (time.clock() - start)
против
start = time.time()
... do something
elapsed = (time.time() - start)
17 ответов
Начиная с 3.3, time.clock () устарела, и вместо него предлагается использовать time.process_time() или time.perf_counter().
Ранее в 2.7, согласно документам модуля времени:
time.clock ()
В Unix верните текущее время процессора в виде числа с плавающей запятой, выраженного в секундах. Точность и, собственно, само определение значения "процессорного времени" зависит от точности функции C с тем же именем, но в любом случае эту функцию следует использовать для тестирования Python или алгоритмов синхронизации.
В Windows эта функция возвращает настенные часы, прошедшие с момента первого вызова этой функции, в виде числа с плавающей запятой на основе функции Win32 QueryPerformanceCounter(). Разрешение обычно лучше, чем одна микросекунда.
Кроме того, есть модуль timeit для сравнительного анализа фрагментов кода.
Короткий ответ: большую часть времени time.clock() будет лучше. Однако, если вы синхронизируете какое-то оборудование (например, какой-то алгоритм, который вы вставляете в графический процессор), тогда time.clock() избавится от этого времени и time.time() это единственное оставшееся решение.
Примечание: какой бы метод ни использовался, время будет зависеть от факторов, которые вы не можете контролировать (когда произойдет переключение процесса, как часто, ...), это хуже с time.time() но существует также с time.clock()Таким образом, вы никогда не должны запускать только один тест синхронизации, но всегда выполнять серию тестов и смотреть на среднее / дисперсию времени.
Следует помнить одну вещь: изменение системного времени влияет time.time() но нет time.clock(),
Мне нужно было контролировать выполнение некоторых автоматических тестов. Если один шаг тестового примера занимал больше определенного времени, этот TC был прерван, чтобы перейти к следующему.
Но иногда необходимо было изменить шаг системного времени (чтобы проверить модуль планировщика тестируемого приложения), поэтому после установки системного времени через несколько часов время тайм-аута TC истекло, и контрольный пример был прерван. Я должен был переключиться с time.time() в time.clock() чтобы справиться с этим правильно.
clock() -> число с плавающей запятой
Возврат времени ЦП или реального времени с начала процесса или с момента первого вызова clock(), Это имеет такую же точность, как и системные записи.
time() -> число с плавающей запятой
Вернуть текущее время в секундах с начала эпохи. Доли секунды могут присутствовать, если их обеспечивают системные часы.
Обычно time() точнее, потому что операционные системы не хранят время выполнения процесса с точностью, в которой они хранят системное время (т. е. фактическое время)
Зависит от того, что вы заботитесь. Если вы имеете в виду WALL TIME (как, например, время на часах на вашей стене), time.clock() НЕТ точности, поскольку она может управлять временем процессора.
Для себя practice. time() имеет лучшую точность, чем clock() в линуксе clock() имеет точность менее 10 мс. В то время как time() дает префект точность. Мой тест на CentOS 6.4, python 2.6
using time():
1 requests, response time: 14.1749382019 ms
2 requests, response time: 8.01301002502 ms
3 requests, response time: 8.01491737366 ms
4 requests, response time: 8.41021537781 ms
5 requests, response time: 8.38804244995 ms
using clock():
1 requests, response time: 10.0 ms
2 requests, response time: 0.0 ms
3 requests, response time: 0.0 ms
4 requests, response time: 10.0 ms
5 requests, response time: 0.0 ms
6 requests, response time: 0.0 ms
7 requests, response time: 0.0 ms
8 requests, response time: 0.0 ms
Как отметили другие time.clock() не рекомендуется в пользу time.perf_counter() или же time.process_time(), но Python 3.7 вводит синхронизацию разрешения наносекунды с time.perf_counter_ns(), time.process_time_ns(), а также time.time_ns() наряду с 3 другими функциями.
Эти 6 новых функций разрешения наносекунд детально описаны в PEP 564:
time.clock_gettime_ns(clock_id)
time.clock_settime_ns(clock_id, time:int)
time.monotonic_ns()
time.perf_counter_ns()
time.process_time_ns()
time.time_ns()Эти функции аналогичны версии без суффикса _ns, но возвращают количество наносекунд в виде Python int.
Как и другие отмечали, используйте timeit модуль времени функций и небольшие фрагменты кода.
Разница очень зависит от платформы.
Например, clock() в Windows сильно отличается от Linux.
Для тех примеров, которые вы описываете, вы, вероятно, захотите использовать модуль timeit.
time.clock()был удален в Python 3.8, поскольку его поведение зависело от платформы:
- В Unix вернуть текущее время процессора в виде числа с плавающей запятой, выраженного в секундах.
В Windows эта функция возвращает время в секундах, прошедшее с момента первого вызова этой функции, в виде числа с плавающей запятой.
print(time.clock()); time.sleep(10); print(time.clock()) # Linux : 0.0382 0.0384 # see Processor Time # Windows: 26.1224 36.1566 # see Wall-Clock Time
Итак, какую функцию выбрать вместо этого?
Время процессора: это время, в течение которого данный процесс активно выполняется на ЦП. Спящий режим, ожидание веб-запроса или время, когда выполняются только другие процессы, этому не повлияют.
- Использовать
time.process_time()
- Использовать
Время настенных часов: это относится к тому, сколько времени прошло "на часах, висящих на стене", то есть вне реального времени.
Использовать
time.perf_counter()time.time()также измеряет время на настенных часах, но их можно сбросить, чтобы вы могли вернуться во времениtime.monotonic()не может быть сброшен (монотонный = идет только вперед), но имеет меньшую точность, чемtime.perf_counter()
Я использую этот код для сравнения 2 методов. Моя ОС Windows 8, процессорное ядро i5, RAM 4 ГБ
import time
def t_time():
start=time.time()
time.sleep(0.1)
return (time.time()-start)
def t_clock():
start=time.clock()
time.sleep(0.1)
return (time.clock()-start)
counter_time=0
counter_clock=0
for i in range(1,100):
counter_time += t_time()
for i in range(1,100):
counter_clock += t_clock()
print "time() =",counter_time/100
print "clock() =",counter_clock/100
выход:
время () = 0.0993799996376
часы () = 0.0993572257367
В Unix time.clock() измеряет количество процессорного времени, которое использовалось текущим процессом, так что это бесполезно для измерения прошедшего времени с некоторого момента в прошлом. В Windows он будет измерять количество секунд, прошедших с момента первого вызова функции. В любой системе time.time() будет возвращать секунды, прошедшие с начала эпохи.
Если вы пишете код, предназначенный только для Windows, любой из них будет работать (хотя вы будете использовать их по-разному - для time.clock()) вычитание не требуется. Если это будет работать в системе Unix или вы хотите, чтобы код, который гарантированно был переносимым, вы захотите использовать time.time().
Краткий ответ: используйте time.clock() для синхронизации в Python.
В *nix системах clock () возвращает время процессора в виде числа с плавающей запятой, выраженного в секундах. В Windows он возвращает секунды, прошедшие с момента первого вызова этой функции, в виде числа с плавающей запятой.
time() возвращает секунды с начала эпохи в формате UTC как число с плавающей запятой. Нет гарантии, что вы получите лучшую точность, чем 1 секунда (хотя time() возвращает число с плавающей запятой). Также обратите внимание, что если системные часы были установлены обратно между двумя вызовами этой функции, второй вызов функции вернет меньшее значение.
Насколько я понимаю, time.clock() имеет столько точности, сколько позволяет ваша система.
Правильный ответ: они оба имеют одинаковую длину дроби.
Но который быстрее, если subject является time?
Маленький тестовый пример:
import timeit
import time
clock_list = []
time_list = []
test1 = """
def test(v=time.clock()):
s = time.clock() - v
"""
test2 = """
def test(v=time.time()):
s = time.time() - v
"""
def test_it(Range) :
for i in range(Range) :
clk = timeit.timeit(test1, number=10000)
clock_list.append(clk)
tml = timeit.timeit(test2, number=10000)
time_list.append(tml)
test_it(100)
print "Clock Min: %f Max: %f Average: %f" %(min(clock_list), max(clock_list), sum(clock_list)/float(len(clock_list)))
print "Time Min: %f Max: %f Average: %f" %(min(time_list), max(time_list), sum(time_list)/float(len(time_list)))
Я не работаю в швейцарских лабораториях, но я проверил..
Исходя из этого вопроса: time.clock() лучше, чем time.time()
Редактировать: time.clock() внутренний счетчик, поэтому не может использоваться снаружи, есть ограничения max 32BIT FLOAT, не могу продолжить подсчет, если не сохранить первые / последние значения. Не могу объединить еще один счетчик...
Сравнение результатов теста между Ubuntu Linux и Windows 7.
На Ubuntu
>>> start = time.time(); time.sleep(0.5); (time.time() - start)
0.5005500316619873
В Windows 7
>>> start = time.time(); time.sleep(0.5); (time.time() - start)
0.5
Чтобы расширить результаты @Hill, вот тест с использованием python 3.4.3 на Xubuntu 16.04 через wine:
(timeit.default_timer будет использовать time.clock(), потому что видит ОС как 'win32')
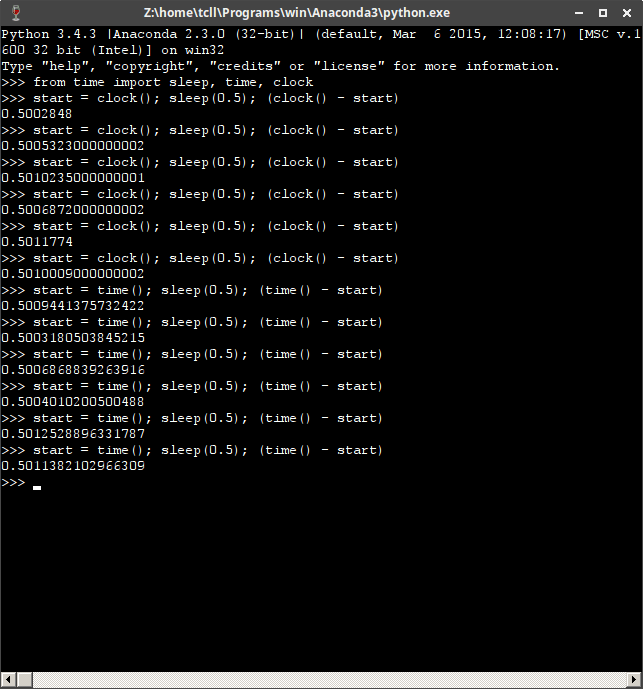
при использовании Windows функция clock () обычно более точна, но это не относится к Wine...
Здесь вы можете увидеть, что time () точнее, чем clock (), что обычно имеет место в Linux и Mac.