Путь от рекурсии к итерации
Я много использовал рекурсию в своих многолетних программах для решения простых задач, но я полностью осознаю, что иногда вам нужна итерация из-за проблем с памятью и скоростью.
Итак, когда-то в очень далеком прошлом я попытался найти, существует ли какой-либо "шаблон" или учебник, способ преобразования обычного рекурсивного подхода к итерации, и ничего не нашел. Или, по крайней мере, ничего, что я помню, это не помогло бы.
- Есть ли общие правила?
- Есть ли "шаблон"?
22 ответа
Обычно я заменяю рекурсивный алгоритм итеративным алгоритмом, помещая параметры, которые обычно передаются рекурсивной функции в стек. Фактически, вы заменяете программный стек одним своим.
Stack<Object> stack;
stack.push(first_object);
while( !stack.isEmpty() ) {
// Do something
my_object = stack.pop();
// Push other objects on the stack.
}
Примечание: если у вас есть более одного рекурсивного вызова внутри, и вы хотите сохранить порядок вызовов, вы должны добавить их в обратном порядке в стек:
foo(first);
foo(second);
должен быть заменен
stack.push(second);
stack.push(first);
Изменить: статья Стеки и устранение рекурсии (или ссылка Резервное копирование статьи) идет более подробно на эту тему.
Действительно, самый распространенный способ сделать это - сохранить свой собственный стек. Вот рекурсивная функция быстрой сортировки в C:
void quicksort(int* array, int left, int right)
{
if(left >= right)
return;
int index = partition(array, left, right);
quicksort(array, left, index - 1);
quicksort(array, index + 1, right);
}
Вот как мы могли бы сделать его итеративным, сохранив свой собственный стек:
void quicksort(int *array, int left, int right)
{
int stack[1024];
int i=0;
stack[i++] = left;
stack[i++] = right;
while (i > 0)
{
right = stack[--i];
left = stack[--i];
if (left >= right)
continue;
int index = partition(array, left, right);
stack[i++] = left;
stack[i++] = index - 1;
stack[i++] = index + 1;
stack[i++] = right;
}
}
Очевидно, что этот пример не проверяет границы стека... и на самом деле вы можете определить размер стека в зависимости от наихудшего случая с учетом левого и правого значений. Но ты получил идею.
Кажется, никто не обращался к тому, где рекурсивная функция вызывает себя более одного раза в теле и обрабатывает возврат к определенной точке рекурсии (то есть не является примитивно-рекурсивной). Говорят, что каждая рекурсия может быть превращена в итерацию, поэтому кажется, что это должно быть возможно.
Я только что придумал пример C#, как это сделать. Предположим, у вас есть следующая рекурсивная функция, которая действует как обход по порядку и что AbcTreeNode - это 3-арное дерево с указателями a, b, c.
public static void AbcRecursiveTraversal(this AbcTreeNode x, List<int> list) {
if (x != null) {
AbcRecursiveTraversal(x.a, list);
AbcRecursiveTraversal(x.b, list);
AbcRecursiveTraversal(x.c, list);
list.Add(x.key);//finally visit root
}
}
Итеративное решение:
int? address = null;
AbcTreeNode x = null;
x = root;
address = A;
stack.Push(x);
stack.Push(null)
while (stack.Count > 0) {
bool @return = x == null;
if (@return == false) {
switch (address) {
case A://
stack.Push(x);
stack.Push(B);
x = x.a;
address = A;
break;
case B:
stack.Push(x);
stack.Push(C);
x = x.b;
address = A;
break;
case C:
stack.Push(x);
stack.Push(null);
x = x.c;
address = A;
break;
case null:
list_iterative.Add(x.key);
@return = true;
break;
}
}
if (@return == true) {
address = (int?)stack.Pop();
x = (AbcTreeNode)stack.Pop();
}
}
Стремитесь сделать рекурсивный вызов Tail Recursion (рекурсия, где последним оператором является рекурсивный вызов). Как только вы это сделаете, преобразовать его в итерацию, как правило, довольно просто.
Ну, в общем, рекурсию можно имитировать как итерацию, просто используя переменную хранения. Обратите внимание, что рекурсия и итерация обычно эквивалентны; одно почти всегда может быть преобразовано в другое. Хвосто-рекурсивная функция очень легко преобразуется в итеративную. Просто сделайте переменную аккумулятора локальной, и выполняйте итерацию вместо recurse. Вот пример на C++ (если бы не использование аргумента по умолчанию):
// tail-recursive
int factorial (int n, int acc = 1)
{
if (n == 1)
return acc;
else
return factorial(n - 1, acc * n);
}
// iterative
int factorial (int n)
{
int acc = 1;
for (; n > 1; --n)
acc *= n;
return acc;
}
Зная меня, я, вероятно, допустил ошибку в коде, но идея есть.
Даже использование стека не преобразует рекурсивный алгоритм в итеративный. Обычная рекурсия - это рекурсия на основе функций, и если мы используем стек, то она становится рекурсией на основе стека. Но это все еще рекурсия.
Для рекурсивных алгоритмов сложность пространства равна O(N), а сложность времени равна O(N). Для итерационных алгоритмов сложность пространства равна O(1), а сложность времени равна O(N).
Но если мы используем стек вещей с точки зрения сложности остается тем же. Я думаю, что только хвостовая рекурсия может быть преобразована в итерацию.
Статья об удалении стеков и рекурсии отражает идею вывода кадра стека из кучи, но не предоставляет простой и воспроизводимый способ преобразования. Ниже один.
При преобразовании в итеративный код необходимо помнить, что рекурсивный вызов может происходить из произвольно глубокого блока кода. Это не только параметры, но и точка возврата к логике, которую еще предстоит выполнить, и состояние переменных, которые участвуют в последующих условных выражениях, которые имеют значение. Ниже приведен очень простой способ преобразования в итеративный код с наименьшими изменениями.
Рассмотрим этот рекурсивный код:
struct tnode
{
tnode(int n) : data(n), left(0), right(0) {}
tnode *left, *right;
int data;
};
void insertnode_recur(tnode *node, int num)
{
if(node->data <= num)
{
if(node->right == NULL)
node->right = new tnode(num);
else
insertnode(node->right, num);
}
else
{
if(node->left == NULL)
node->left = new tnode(num);
else
insertnode(node->left, num);
}
}
Итерационный код:
// Identify the stack variables that need to be preserved across stack
// invocations, that is, across iterations and wrap them in an object
struct stackitem
{
stackitem(tnode *t, int n) : node(t), num(n), ra(0) {}
tnode *node; int num;
int ra; //to point of return
};
void insertnode_iter(tnode *node, int num)
{
vector<stackitem> v;
//pushing a stackitem is equivalent to making a recursive call.
v.push_back(stackitem(node, num));
while(v.size())
{
// taking a modifiable reference to the stack item makes prepending
// 'si.' to auto variables in recursive logic suffice
// e.g., instead of num, replace with si.num.
stackitem &si = v.back();
switch(si.ra)
{
// this jump simulates resuming execution after return from recursive
// call
case 1: goto ra1;
case 2: goto ra2;
default: break;
}
if(si.node->data <= si.num)
{
if(si.node->right == NULL)
si.node->right = new tnode(si.num);
else
{
// replace a recursive call with below statements
// (a) save return point,
// (b) push stack item with new stackitem,
// (c) continue statement to make loop pick up and start
// processing new stack item,
// (d) a return point label
// (e) optional semi-colon, if resume point is an end
// of a block.
si.ra=1;
v.push_back(stackitem(si.node->right, si.num));
continue;
ra1: ;
}
}
else
{
if(si.node->left == NULL)
si.node->left = new tnode(si.num);
else
{
si.ra=2;
v.push_back(stackitem(si.node->left, si.num));
continue;
ra2: ;
}
}
v.pop_back();
}
}
Обратите внимание, что структура кода все еще остается верной рекурсивной логике, а модификации минимальны, что приводит к меньшему количеству ошибок. Для сравнения я пометил изменения с ++ и -. Большинство новых вставленных блоков, кроме v.push_back, являются общими для любой преобразованной итерационной логики
void insertnode_iter(tnode *node, int num)
{
+++++++++++++++++++++++++
vector<stackitem> v;
v.push_back(stackitem(node, num));
while(v.size())
{
stackitem &si = v.back();
switch(si.ra)
{
case 1: goto ra1;
case 2: goto ra2;
default: break;
}
------------------------
if(si.node->data <= si.num)
{
if(si.node->right == NULL)
si.node->right = new tnode(si.num);
else
{
+++++++++++++++++++++++++
si.ra=1;
v.push_back(stackitem(si.node->right, si.num));
continue;
ra1: ;
-------------------------
}
}
else
{
if(si.node->left == NULL)
si.node->left = new tnode(si.num);
else
{
+++++++++++++++++++++++++
si.ra=2;
v.push_back(stackitem(si.node->left, si.num));
continue;
ra2: ;
-------------------------
}
}
+++++++++++++++++++++++++
v.pop_back();
}
-------------------------
}
Поиск в Google для "Стиль продолжения прохождения". Существует общая процедура для преобразования в хвостовой рекурсивный стиль; Существует также общая процедура преобразования хвостовых рекурсивных функций в циклы.
Просто убивает время... Рекурсивная функция
void foo(Node* node)
{
if(node == NULL)
return;
// Do something with node...
foo(node->left);
foo(node->right);
}
может быть преобразован в
void foo(Node* node)
{
if(node == NULL)
return;
// Do something with node...
stack.push(node->right);
stack.push(node->left);
while(!stack.empty()) {
node1 = stack.pop();
if(node1 == NULL)
continue;
// Do something with node1...
stack.push(node1->right);
stack.push(node1->left);
}
}
Думая о вещах, которые действительно нуждаются в стеке:
Если мы рассмотрим шаблон рекурсии как:
if(task can be done directly) {
return result of doing task directly
} else {
split task into two or more parts
solve for each part (possibly by recursing)
return result constructed by combining these solutions
}
Например, классическая Ханойская башня
if(the number of discs to move is 1) {
just move it
} else {
move n-1 discs to the spare peg
move the remaining disc to the target peg
move n-1 discs from the spare peg to the target peg, using the current peg as a spare
}
Это может быть преобразовано в цикл, работающий с явным стеком, путем его преобразования:
place seed task on stack
while stack is not empty
take a task off the stack
if(task can be done directly) {
Do it
} else {
Split task into two or more parts
Place task to consolidate results on stack
Place each task on stack
}
}
Для Ханойской Башни это становится:
stack.push(new Task(size, from, to, spare));
while(! stack.isEmpty()) {
task = stack.pop();
if(task.size() = 1) {
just move it
} else {
stack.push(new Task(task.size() -1, task.spare(), task,to(), task,from()));
stack.push(new Task(1, task.from(), task.to(), task.spare()));
stack.push(new Task(task.size() -1, task.from(), task.spare(), task.to()));
}
}
Здесь есть большая гибкость в отношении того, как вы определяете свой стек. Вы можете сделать свой стек списком Command объекты, которые делают сложные вещи. Или вы можете пойти в противоположном направлении и составить список простых типов (например, "задача" может быть 4 элемента в стеке intвместо одного элемента в стеке Task).
Все это означает, что память для стека находится в куче, а не в стеке выполнения Java, но это может быть полезно, поскольку у вас больше контроля над ней.
Обычно метод, позволяющий избежать переполнения стека для рекурсивных функций, называется методом батута, который широко применяется разработчиками Java.
Однако для C# здесь есть небольшой вспомогательный метод, который превращает вашу рекурсивную функцию в итеративную, не требуя изменения логики или превращения кода в непонятный. C# - такой приятный язык, что с ним можно создавать удивительные вещи.
Он работает, оборачивая части метода вспомогательным методом. Например, следующая рекурсивная функция:
int Sum(int index, int[] array)
{
//This is the termination condition
if (int >= array.Length)
//This is the returning value when termination condition is true
return 0;
//This is the recursive call
var sumofrest = Sum(index+1, array);
//This is the work to do with the current item and the
//result of recursive call
return array[index]+sumofrest;
}
Превращается в:
int Sum(int[] ar)
{
return RecursionHelper<int>.CreateSingular(i => i >= ar.Length, i => 0)
.RecursiveCall((i, rv) => i + 1)
.Do((i, rv) => ar[i] + rv)
.Execute(0);
}
Один шаблон для поиска - это рекурсивный вызов в конце функции (так называемая хвостовая рекурсия). Это может быть легко заменено на некоторое время. Например, функция foo:
void foo(Node* node)
{
if(node == NULL)
return;
// Do something with node...
foo(node->left);
foo(node->right);
}
заканчивается звонком в foo. Это можно заменить на:
void foo(Node* node)
{
while(node != NULL)
{
// Do something with node...
foo(node->left);
node = node->right;
}
}
который устраняет второй рекурсивный вызов.
Общий способ преобразования рекурсивной функции в итеративное решение, которое будет применяться к любому случаю, - это имитировать процесс, который ЦП использует во время вызова функции и возврата из вызова.
Если взять пример, требующий несколько сложного подхода, у нас есть алгоритм быстрой сортировки с несколькими ключами. Эта функция имеет три последовательных рекурсивных вызова, и после каждого вызова выполнение начинается со следующей строки.
Состояние функции фиксируется в кадре стека, который помещается в стек выполнения. Когда
sort()вызывается изнутри себя и возвращается, фрейм стека, присутствующий во время вызова, восстанавливается. Таким образом, все переменные имеют те же значения, что и до вызова, если только они не были изменены вызовом.
Рекурсивная функция
def sort(a: list_view, d: int):
if len(a) <= 1:
return
p = pivot(a, d)
i, j = partition(a, d, p)
sort(a[0:i], d)
sort(a[i:j], d + 1)
sort(a[j:len(a)], d)
Взяв эту модель и имитируя ее, создается список, который действует как стек. В этом примере кортежи используются для имитации фреймов. Если бы это было закодировано на C, можно было бы использовать структуры. Данные могут содержаться в структуре данных, а не просто выдвигать одно значение за раз.
Переопределено как "итеративное"
# Assume `a` is view-like object where slices reference
# the same internal list of strings.
def sort(a: list_view):
stack = []
stack.append((LEFT, a, 0)) # Initial frame.
while len(stack) > 0:
frame = stack.pop()
if len(frame[1]) <= 1: # Guard.
continue
stage = frame[0] # Where to jump to.
if stage == LEFT:
_, a, d = frame # a - array/list, d - depth.
p = pivot(a, d)
i, j = partition(a, d, p)
stack.append((MID, a, i, j, d)) # Where to go after "return".
stack.append((LEFT, a[0:i], d)) # Simulate function call.
elif stage == MID: # Picking up here after "call"
_, a, i, j, d = frame # State before "call" restored.
stack.append((RIGHT, a, i, j, d)) # Set up for next "return".
stack.append((LEFT, a[i:j], d + 1)) # Split list and "recurse".
elif stage == RIGHT:
_, a, _, j, d = frame
stack.append((LEFT, a[j:len(a)], d)
else:
pass
Когда выполняется вызов функции, информация о том, где начать выполнение после возврата функции, включается в кадр стека. В этом примере блоки представляют точки, в которых выполнение начинается после возврата из вызова. В C это может быть реализовано как
switch утверждение.
В этом примере блокам присвоены метки; они произвольно помечаются тем, как список разделен внутри каждого блока. Первый блок «LEFT» разделяет список слева. Раздел «MID» представляет собой блок, который разбивает список посередине и т. Д.
При таком подходе имитация вызова выполняется в два этапа. Сначала в стек помещается кадр, который заставит выполнение возобновиться в блоке, следующем за текущим после того, как «вызов» «вернется». Значение в кадре указывает, в какую секцию следует попасть в цикл, следующий за «вызовом».
Затем кадр «вызова» помещается в стек. Это отправляет выполнение в первый, «ЛЕВЫЙ», блок в большинстве случаев для этого конкретного примера. Именно здесь выполняется фактическая сортировка независимо от того, какой раздел списка был разделен, чтобы туда попасть.
Перед началом цикла основной кадр, помещенный в верхнюю часть функции, представляет собой первоначальный вызов. Затем на каждой итерации появляется кадр. Значение / метка «LEFT/MID / RIGHT» из кадра используется для попадания в правильный блок
if/elif/elseутверждение. Кадр используется для восстановления состояния переменных, необходимых для текущей операции, затем на следующей итерации появляется кадр возврата, отправляя выполнение в следующий раздел.
Заключение
Подобные методы, которые преобразуют рекурсивные функции в итерационные функции, по существу также являются «рекурсивными». Вместо того, чтобы использовать стек процессов для фактических вызовов функций, его место занимает другой программно реализованный стек.
Что получено? Возможно небольшое улучшение скорости. Или это может служить способом обойти ограничения стека, налагаемые некоторыми компиляторами. В некоторых случаях количество данных, помещаемых в стек, можно уменьшить. Компенсируют ли выигрыши сложность кода, имитируя то, что мы получаем автоматически с рекурсивной реализацией?
В случае алгоритма сортировки найти способ реализовать этот конкретный алгоритм без стека может быть непросто, к тому же существует так много доступных алгоритмов итеративной сортировки, которые работают намного быстрее. Было сказано, что любой рекурсивный алгоритм можно реализовать итеративно. Конечно ... но некоторые алгоритмы плохо конвертируются без модификации до такой степени, что это уже не тот же алгоритм.
Возможно, это не такая уж хорошая идея преобразовывать рекурсивные алгоритмы только ради их преобразования. В любом случае, как бы то ни было, описанный выше подход представляет собой общий способ преобразования, который должен применяться практически ко всему.
Вопрос, который был закрыт как дубликат этого, имел очень специфическую структуру данных:
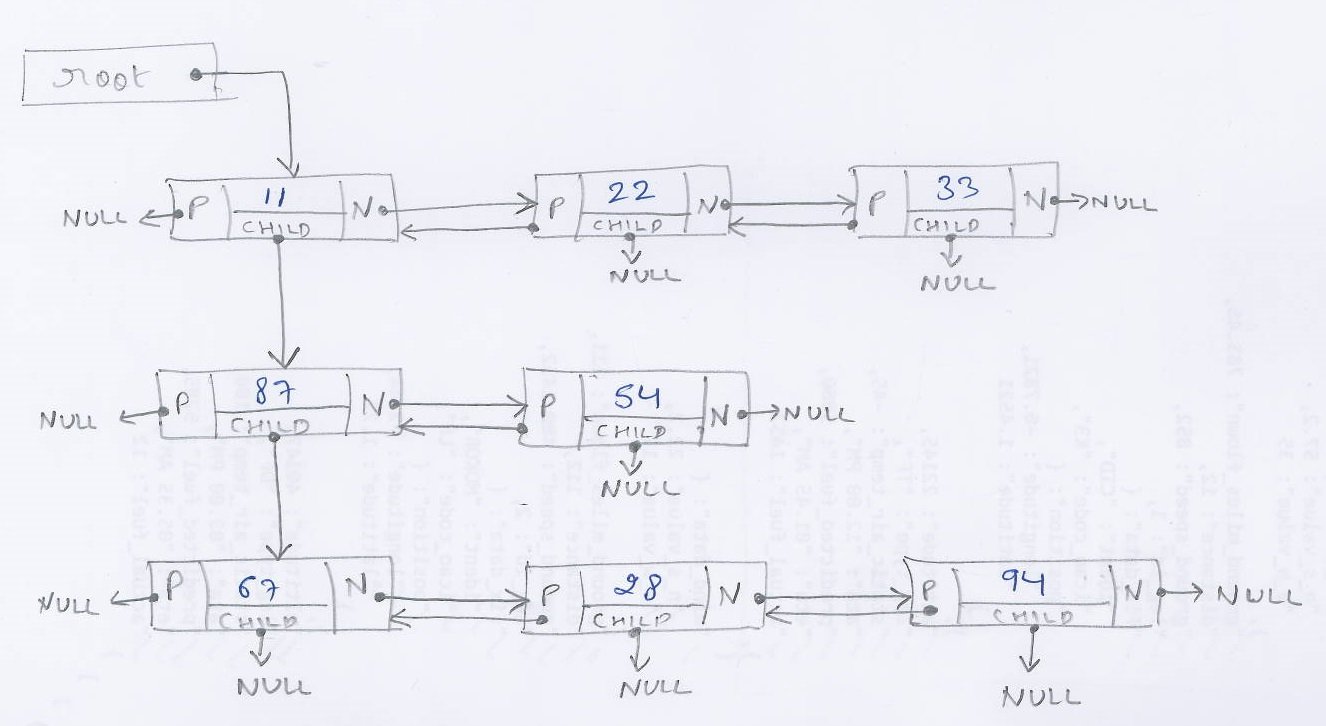
Узел имел следующую структуру:
typedef struct {
int32_t type;
int32_t valueint;
double valuedouble;
struct cNODE *next;
struct cNODE *prev;
struct cNODE *child;
} cNODE;
Функция рекурсивного удаления выглядела так:
void cNODE_Delete(cNODE *c) {
cNODE*next;
while (c) {
next=c->next;
if (c->child) {
cNODE_Delete(c->child)
}
free(c);
c=next;
}
}
В общем, не всегда возможно избежать стека для рекурсивных функций, которые вызывают себя более одного раза (или даже один раз). Однако для этой конкретной структуры это возможно. Идея состоит в том, чтобы объединить все узлы в один список. Это достигается путем помещения текущего узла child в конце списка верхнего ряда.
void cNODE_Delete (cNODE *c) {
cNODE *tmp, *last = c;
while (c) {
while (last->next) {
last = last->next; /* find last */
}
if ((tmp = c->child)) {
c->child = NULL; /* append child to last */
last->next = tmp;
tmp->prev = last;
}
tmp = c->next; /* remove current */
free(c);
c = tmp;
}
}
Этот метод может быть применен к любой связанной с данными структуре, которая может быть сведена к DAG с детерминированным топологическим упорядочением. Текущие дочерние узлы переставляются так, что последний дочерний элемент принимает всех остальных дочерних элементов. Затем текущий узел может быть удален, и обход может затем перейти к оставшемуся дочернему элементу.
Рекурсия - это не что иное, как процесс вызова одной функции из другой, только этот процесс выполняется путем вызова самой функции. Как мы знаем, когда одна функция вызывает другую функцию, первая функция сохраняет свое состояние (свои переменные), а затем передает управление вызываемой функции. Вызываемая функция может быть вызвана с использованием одного и того же имени переменных. Ex fun1(a) может вызвать fun2(a). Когда мы делаем рекурсивный вызов, ничего нового не происходит. Одна функция вызывает себя, передавая один и тот же тип и похожие по имени переменные (но, очевидно, значения, хранящиеся в переменных, различны, только имя остается тем же самым). Но перед каждым вызовом функция сохраняет свое состояние, и этот процесс сохранения продолжается. ЭКОНОМИЯ СДЕЛАНА НА СТЕКЕ.
СЕЙЧАС СТЕК ВХОДИТ В ИГРА.
Поэтому, если вы пишете итеративную программу и каждый раз сохраняете состояние в стеке, а затем извлекаете значения из стека, когда это необходимо, вы успешно преобразовали рекурсивную программу в итеративную!
Доказательство простое и аналитическое.
В рекурсии компьютер поддерживает стек, а в итерационной версии вам придется вручную поддерживать стек.
Подумайте об этом, просто преобразуйте рекурсивную программу поиска в глубину (на графиках) в итерационную программу dfs.
Всего наилучшего!
Я только что проголосовал за ответ, предлагающий использовать явный стек, который, я думаю, является правильным решением и имеет общую применимость.
Я имею в виду, что вы можете использовать его для преобразования любой рекурсивной функции в итерационную функцию. Просто проверьте, какие значения сохраняются при рекурсивных вызовах, те, которые должны быть локальными для рекурсивной функции, и замените вызовы циклом, в котором вы поместите их в стек. Когда стек пуст, рекурсивная функция была бы прервана.
Я не могу не сказать, что доказательство того, что каждая рекурсивная функция эквивалентна итерационной функции для другого типа данных, является одним из моих самых дорогих воспоминаний о моих университетских временах. Это был курс (и профессор), который действительно помог мне понять, что такое компьютерное программирование.
Это старый вопрос, но я хочу добавить другой аспект в качестве решения. В настоящее время я работаю над проектом, в котором я использовал алгоритм заливки с использованием C#. Обычно я сначала реализовал этот алгоритм с рекурсией, но, очевидно, это вызвало переполнение стека. После этого я изменил метод с рекурсии на итерацию. Да, это сработало, и я больше не получал ошибку переполнения стека. Но на этот раз, поскольку я применил метод заливки к очень большим структурам, программа зашла в бесконечный цикл. По этой причине мне пришло в голову, что функция могла повторно войти в места, которые она уже посещала. В качестве окончательного решения этой проблемы я решил использовать словарь посещенных точек. Если этот узел (x,y) уже был добавлен в структуру стека впервые, этот узел (x,y) будет сохранен в словаре как ключ. Даже если тот же узел позже попытается снова добавить, он не будет добавлен в структуру стека, потому что узел уже находится в словаре. Посмотрим на псевдокод:
startNode = pos(x,y)
Stack stack = new Stack();
Dictionary visited<pos, bool> = new Dictionary();
stack.Push(startNode);
while(stack.count != 0){
currentNode = stack.Pop();
if "check currentNode if not available"
continue;
if "check if already handled"
continue;
else if "run if it must be wanted thing should be handled"
// make something with pos currentNode.X and currentNode.X
// then add its neighbor nodes to the stack to iterate
// but at first check if it has already been visited.
if(!visited.Contains(pos(x-1,y)))
visited[pos(x-1,y)] = true;
stack.Push(pos(x-1,y));
if(!visited.Contains(pos(x+1,y)))
...
if(!visited.Contains(pos(x,y+1)))
...
if(!visited.Contains(pos(x,y-1)))
...
}
Еще один простой и полный пример превращения рекурсивной функции в итеративную с использованием стека.
#include <iostream>
#include <stack>
using namespace std;
int GCD(int a, int b) { return b == 0 ? a : GCD(b, a % b); }
struct Par
{
int a, b;
Par() : Par(0, 0) {}
Par(int _a, int _b) : a(_a), b(_b) {}
};
int GCDIter(int a, int b)
{
stack<Par> rcstack;
if (b == 0)
return a;
rcstack.push(Par(b, a % b));
Par p;
while (!rcstack.empty())
{
p = rcstack.top();
rcstack.pop();
if (p.b == 0)
continue;
rcstack.push(Par(p.b, p.a % p.b));
}
return p.a;
}
int main()
{
//cout << GCD(24, 36) << endl;
cout << GCDIter(81, 36) << endl;
cin.get();
return 0;
}
Мои примеры написаны на Clojure, но их довольно легко перевести на любой язык.
Учитывая эту функцию, Stackrus для больших значений n:
(defn factorial [n]
(if (< n 2)
1
(*' n (factorial (dec n)))))
мы можем определить версию, использующую собственный стек, следующим образом:
(defn factorial [n]
(loop [n n
stack []]
(if (< n 2)
(return 1 stack)
;; else loop with new values
(recur (dec n)
;; push function onto stack
(cons (fn [n-1!]
(*' n n-1!))
stack)))))
где return определяется как:
(defn return
[v stack]
(reduce (fn [acc f]
(f acc))
v
stack))
Это работает и для более сложных функций, например, для функции Аккермана:
(defn ackermann [m n]
(cond
(zero? m)
(inc n)
(zero? n)
(recur (dec m) 1)
:else
(recur (dec m)
(ackermann m (dec n)))))
можно преобразовать в:
(defn ackermann [m n]
(loop [m m
n n
stack []]
(cond
(zero? m)
(return (inc n) stack)
(zero? n)
(recur (dec m) 1 stack)
:else
(recur m
(dec n)
(cons #(ackermann (dec m) %)
stack)))))
Существует общий способ преобразования рекурсивного обхода в итератор с помощью ленивого итератора, который объединяет несколько поставщиков итераторов (лямбда-выражение, которое возвращает итератор). Посмотрите мое преобразование рекурсивного обхода в итератор.
Грубое описание того, как система берет любую рекурсивную функцию и выполняет ее, используя стек:
Это призвано показать идею без подробностей. Рассмотрим эту функцию, которая будет распечатывать узлы графа:
function show(node)
0. if isleaf(node):
1. print node.name
2. else:
3. show(node.left)
4. show(node)
5. show(node.right)
Например, график: A->B A->C show(A) выведет B, A, C
Вызов функции означает сохранение локального состояния и точки продолжения, чтобы вы могли вернуться и затем перейти к функции, которую вы хотите вызвать.
Например, предположим, что шоу (A) начинает работать. Вызов функции в строке 3. show(B) означает - Добавить элемент в стек, что означает "вам нужно продолжить со строки 2 с локальной переменной state node=A" - Перейти к строке 0 с node=B.
Чтобы выполнить код, система выполняет инструкции. Когда происходит вызов функции, система отправляет информацию, необходимую для возврата туда, где она была, запускает код функции, а когда функция завершается, выдает информацию о том, куда ей нужно перейти, чтобы продолжить.
Эта ссылка дает некоторое объяснение и предлагает идею сохранения "местоположения", чтобы иметь возможность добраться до точного места между несколькими рекурсивными вызовами:
Однако все эти примеры описывают сценарии, в которых рекурсивный вызов выполняется фиксированное количество раз. Все становится сложнее, когда у вас есть что-то вроде:
function rec(...) {
for/while loop {
var x = rec(...)
// make a side effect involving return value x
}
}