Forestplot R - расширение графика, редактирование имени переменной
Я подготовил код для визуализации моих данных:
library(forestplot)
test_data <- data.frame(coef=c(1.14, 0.31, 10.70),
low=c(1.01, 0.12, 1.14),
high=c(1.30, 0.83, 100.16),
boxsize=c(0.2, 0.2, 0.2))
row_names <- cbind(c("Variable", "Variable 1", "Variable 2", "So looooooong and nasty name of the variable"),
c("OR", test_data$coef), c("CI -95%", test_data$low), c("CI +95%", test_data$high) )
test_data <- rbind(rep(NA, 4), test_data)
forestplot(labeltext = row_names,
mean = test_data$coef, upper = test_data$high,
lower = test_data$low,
is.summary=c(TRUE, FALSE, FALSE, FALSE),
boxsize = test_data$boxsize,
zero = 1,
xlog = TRUE,
xlab = "OR (95% CI)",
col = fpColors(lines="black", box="black"),
title="My Happy Happy Title \n o happy happy title...\n",
ci.vertices = TRUE,
xticks = c(0.1, 1, 10, 100))
Это дает следующий лесной участок:
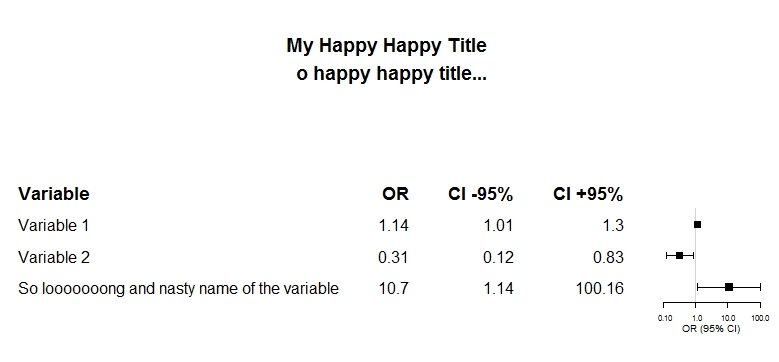
Я бы хотел:
1) разверните график и уменьшите шрифт деталей графика слева для лучшей визуализации
2) отредактируйте "So looooooong и противное имя переменной", чтобы переместить часть "name..." ниже строки, например: "So looooooong и противное имя переменной" Однако, когда я пишу как "/nSo.../ n "это дает другой ряд номера из столбцов" ИЛИ "и" КИ ".
Как это исправить?
1 ответ
Три возможности (на одну больше, чем вы просили):
1) изменить текст меток строк с помощью txt_gp,
2) сократить расстояние между столбцами по умолчанию от 6 мм до половины этого значения, передав colgap вызов сетки на единицу. Полное понимание вариантов forestplot требует понимания grid система построения.
3) добавить "\n" на этикетку (Я озадачен, что вы не видели такой возможности, так как у вас уже было "\n" в заголовке.)
row_names <- cbind(c("Variable", "Variable 1", "Variable 2", "So looooooong and \nnasty name of the variable"),
c("OR", test_data$coef), c("CI -95%", test_data$low), c("CI +95%", test_data$high) )
forestplot(labeltext = row_names,
mean = test_data$coef, upper = test_data$high,
lower = test_data$low,
is.summary=c(TRUE, FALSE, FALSE, FALSE),
boxsize = test_data$boxsize,
zero = 1, colgap = unit(3, "mm"), txt_gp=fpTxtGp(label= gpar(cex = 0.7),
title = gpar(cex = 1) ),
xlog = TRUE,
xlab = "OR (95% CI)",
col = fpColors(lines="black", box="black"),
title="My Happy Happy Title \n o happy happy title...\n",
ci.vertices = TRUE,
xticks = c(0.1, 1, 10, 100))
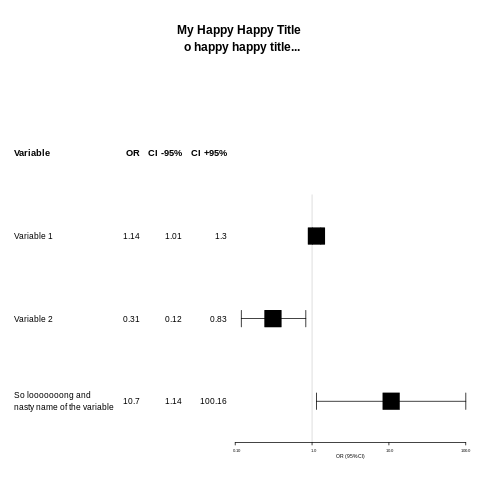
Если бы я использовал только cex 0,7 в звонке gpar переданный метке, это также повлияло на размер заголовка, поэтому мне нужно было "сбросить" cex заголовка обратно на 1.