Ошибка при извлечении изображения из PDF в python
Я пытаюсь извлечь все форматы изображений из PDF. Я немного погуглил и нашел эту страницу в Stackru. Я пробовал этот код, но я получаю эту ошибку:
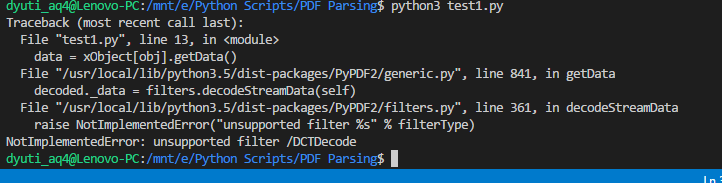
Я использую Python 3.x и вот код, который я использую. Я пытался просмотреть комментарии, но не смог понять. Пожалуйста, помогите мне решить это.
Вот образец PDF.
import PyPDF2
from PIL import Image
if __name__ == '__main__':
input1 = PyPDF2.PdfFileReader(open("Aadhaar1.pdf", "rb"))
page0 = input1.getPage(0)
xObject = page0['/Resources']['/XObject'].getObject()
for obj in xObject:
if xObject[obj]['/Subtype'] == '/Image':
size = (xObject[obj]['/Width'], xObject[obj]['/Height'])
data = xObject[obj].getData()
if xObject[obj]['/ColorSpace'] == '/DeviceRGB':
mode = "RGB"
else:
mode = "P"
if xObject[obj]['/Filter'] == '/FlateDecode':
img = Image.frombytes(mode, size, data)
img.save(obj[1:] + ".png")
elif xObject[obj]['/Filter'] == '/DCTDecode':
img = open(obj[1:] + ".jpg", "wb")
img.write(data)
img.close()
elif xObject[obj]['/Filter'] == '/JPXDecode':
img = open(obj[1:] + ".jp2", "wb")
img.write(data)
img.close()
Я читал некоторые комментарии и просматривал ссылки и обнаружил, что эта проблема решена на этой странице. Может кто-нибудь, пожалуйста, помогите мне реализовать это?
3 ответа
Это PyPDF2 ошибка библиотеки Попробуйте удалить и установить библиотеку с изменениями, или вы можете увидеть изменения в GitHub и отметить их. Надеюсь, это сработает.
Такая же ошибка у меня с Python 3.9 и PyPDF2 1.26 на момент написания этой статьи.
data = xObject[obj].getData()
была проблемная линия. В моем PDF-файле были изображения JPG, и эта строка не работала из-за того же исключения NotImlemented. Изменение строки для части /DCTDecode на;
data = xObject[obj]._data
вроде сработало для меня. Это дает простой поток JPG в формате PDF. Таким образом, отдельные строки данных = ... для каждого раздела if/filter, хотя часть JP2 не пробовали.
На сегодняшний день я все еще получаю сообщение об ошибке NotImplementedError: unsupported filter /DCTDecode
У меня установлен PyPDF2 v 1.26.0 с использованием Python3 3.7.5. Мой код Python такой же, как и выше.
Есть ли решение?