Установка правильной кодировки при передаче стандартного вывода в Python
При передаче результатов Python-программы интерпретатор Python запутывается в кодировке и устанавливает для нее значение None. Это означает такую программу:
# -*- coding: utf-8 -*-
print u"åäö"
будет нормально работать при нормальной работе, но не с:
UnicodeEncodeError: кодек 'ascii' не может кодировать символ u'\xa0' в позиции 0: порядковый номер не в диапазоне (128)
при использовании в последовательности труб.
Каков наилучший способ сделать эту работу при обвязке? Могу ли я просто сказать ему использовать любую кодировку оболочки / файловой системы / что бы она ни использовала?
До сих пор я видел предложения по прямой модификации вашего site.py или жесткому кодированию defaultencoding с помощью этого хака:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
print u"åäö"
Есть ли лучший способ заставить трубопровод работать?
13 ответов
Ваш код работает при запуске в скрипте, потому что Python кодирует выходные данные в любую кодировку, используемую вашим терминальным приложением. Если вы используете трубопровод, вы должны закодировать его самостоятельно.
Практическое правило: всегда используйте Unicode для внутреннего использования. Расшифруйте то, что вы получаете, и закодируйте то, что вы отправляете.
# -*- coding: utf-8 -*-
print u"åäö".encode('utf-8')
Другим дидактическим примером является программа на Python, конвертирующая между ISO-8859-1 и UTF-8, делающая все в верхнем регистре между ними.
import sys
for line in sys.stdin:
# Decode what you receive:
line = line.decode('iso8859-1')
# Work with Unicode internally:
line = line.upper()
# Encode what you send:
line = line.encode('utf-8')
sys.stdout.write(line)
Установка системной кодировки по умолчанию - плохая идея, потому что некоторые модули и библиотеки, которые вы используете, могут полагаться на факт, что это ASCII. Не делай этого.
Во-первых, относительно этого решения:
# -*- coding: utf-8 -*-
print u"åäö".encode('utf-8')
Непрактично каждый раз явно печатать с заданной кодировкой. Это было бы повторяющимся и подверженным ошибкам.
Лучшее решение - изменить sys.stdout в начале вашей программы для кодирования с выбранной кодировкой. Вот одно решение, которое я нашел на Python: Как выбрать sys.stdout.encoding?, в частности комментарий от "Тока":
import sys
import codecs
sys.stdout = codecs.getwriter('utf8')(sys.stdout)
Вы можете попробовать изменить переменную среды "PYTHONIOENCODING" на "utf_8". Я написал страницу в моем испытании с этой проблемой.
Tl; dr поста в блоге:
import sys, locale, os
print(sys.stdout.encoding)
print(sys.stdout.isatty())
print(locale.getpreferredencoding())
print(sys.getfilesystemencoding())
print(os.environ["PYTHONIOENCODING"])
print(chr(246), chr(9786), chr(9787))
дает тебе
utf_8
False
ANSI_X3.4-1968
ascii
utf_8
ö ☺ ☻
export PYTHONIOENCODING=utf-8
сделать работу, но не могу установить его на самом Python...
то, что мы можем сделать, это проверить, если не установлен, и сказать пользователю установить его перед вызовом скрипта с помощью
if __name__ == '__main__':
if (sys.stdout.encoding is None):
print >> sys.stderr, "please set python env PYTHONIOENCODING=UTF-8, example: export PYTHONIOENCODING=UTF-8, when write to stdout."
exit(1)
Обновление, чтобы ответить на комментарий: проблема просто существует при передаче в стандартный вывод. Я тестировал в Fedora 25 Python 2.7.13
python --version
Python 2.7.13
кот б.пи
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import sys
print sys.stdout.encoding
работает./b.py
UTF-8
работает./b.py | Меньше
None
Я удивлен, что этот ответ еще не опубликован здесь
Начиная с Python 3.7 вы можете изменить кодировку стандартных потоков с помощью
reconfigure():sys.stdout.reconfigure(encoding='utf-8')Вы также можете изменить способ обработки ошибок кодирования, добавив
errorsпараметр.
/questions/9271885/kak-ustanovit-kodirovku-sysstdout-v-python-3/9271895#9271895
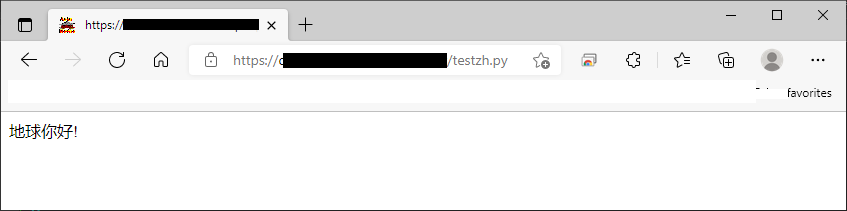
Начиная с Python 3.7, мы можем использовать режим Python UTF-8, используя параметр командной строки -X utf8:
python -X utf8 testzh.py
Скрипт testzh.py содержит
print("Content-type: text/html; charset=UTF-8\n")
print("地球你好!")
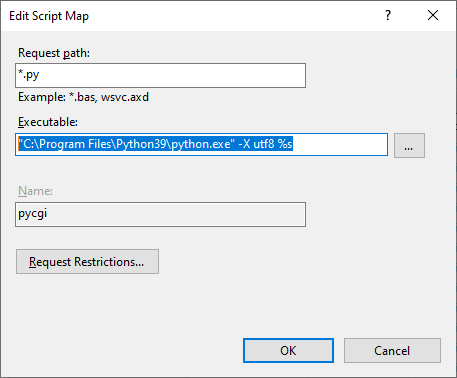
Чтобы установить IIS интернет-службы Windows 10 в качестве обработчика сценария CGI,
Мы устанавливаем исполняемый файл следующим образом:
"C:\Program Files\Python39\python.exe" -X utf8 %s
Это работает для китайских идеограмм, как и ожидалось, в браузере Microsoft.Edge, как на этом снимке экрана: В противном случае возникает ошибка.
У меня была похожая проблема на прошлой неделе. Это было легко исправить в моей IDE (PyCharm).
Вот мое исправление:
Начиная с строки меню PyCharm: Файл -> Настройки... -> Редактор -> Кодировки файлов, затем установите: "Кодировка IDE", "Кодировка проекта" и "Кодировка по умолчанию для файлов свойств" ВСЕ в UTF-8, и теперь она работает Как колдовство.
Надеюсь это поможет!
Спорная санированная версия ответа Крейга МакКуина.
import sys, codecs
class EncodedOut:
def __init__(self, enc):
self.enc = enc
self.stdout = sys.stdout
def __enter__(self):
if sys.stdout.encoding is None:
w = codecs.getwriter(self.enc)
sys.stdout = w(sys.stdout)
def __exit__(self, exc_ty, exc_val, tb):
sys.stdout = self.stdout
Использование:
with EncodedOut('utf-8'):
print u'ÅÄÖåäö'
Я просто подумал, что упомяну здесь кое-что, с чем мне пришлось потратить много времени на эксперименты, прежде чем я наконец понял, что происходит. Это может быть настолько очевидным для всех здесь, что они не потрудились упомянуть об этом. Но это помогло бы мне, если бы они имели, так по этому принципу...!
NB: я использую Jython специально, v 2.7, так что, возможно, это не относится к CPython...
NB2: первые две строки моего файла.py здесь:
# -*- coding: utf-8 -*-
from __future__ import print_function
Механизм построения строки "%" (AKA "оператор интерполяции") также вызывает ДОПОЛНИТЕЛЬНЫЕ проблемы... Если кодировка "среды" по умолчанию - ASCII, и вы пытаетесь сделать что-то вроде
print( "bonjour, %s" % "fréd" ) # Call this "print A"
У вас не будет проблем с запуском в Eclipse... В Windows CLI (окно DOS) вы обнаружите, что кодировка - это кодовая страница 850 (моя ОС Windows 7) или что-то подобное, которая может обрабатывать европейские символы с акцентом по крайней мере, так что буду работать
print( u"bonjour, %s" % "fréd" ) # Call this "print B"
тоже будет работать.
Если, OTOH, вы перенаправляете файл из CLI, кодировкой stdout будет None, которая по умолчанию будет ASCII (в любом случае, в моей ОС), которая не сможет обрабатывать ни один из вышеперечисленных отпечатков... (страшная кодировка ошибка).
Итак, вы можете подумать о перенаправлении стандартного вывода с помощью
sys.stdout = codecs.getwriter('utf8')(sys.stdout)
и попробуйте запустить в CLI трубопровод к файлу... Как ни странно, печать A выше будет работать... Но печать B выше вызовет ошибку кодирования! Следующее, однако, будет работать нормально:
print( u"bonjour, " + "fréd" ) # Call this "print C"
Вывод, к которому я пришел (условно), заключается в том, что если строка, указанная как строка Unicode с префиксом "u", передается в механизм%-handling, то она, по-видимому, предполагает использование кодировки среды по умолчанию, независимо от установили ли вы stdout для перенаправления!
Как люди справляются с этим - вопрос выбора. Я хотел бы, чтобы эксперт по Unicode рассказал, почему это происходит, правильно ли я понял это, каким образом это предпочтительное решение, применимо ли это также к CPython, происходит ли это в Python 3 и т. Д., И т. Д., И т. Д.
Я столкнулся с этой проблемой в унаследованном приложении, и было трудно определить, где что было напечатано. Я помог себе с этим взломать:
# encoding_utf8.py
import codecs
import builtins
def print_utf8(text, **kwargs):
print(str(text).encode('utf-8'), **kwargs)
def print_utf8(fn):
def print_fn(*args, **kwargs):
return fn(str(*args).encode('utf-8'), **kwargs)
return print_fn
builtins.print = print_utf8(print)
Поверх моего скрипта test.py:
import encoding_utf8
string = 'Axwell Λ Ingrosso'
print(string)
Обратите внимание, что это изменяет ВСЕ вызовы на печать для использования кодировки, поэтому ваша консоль напечатает это:
$ python test.py
b'Axwell \xce\x9b Ingrosso'
Я мог бы "автоматизировать" это с помощью вызова:
def __fix_io_encoding(last_resort_default='UTF-8'):
import sys
if [x for x in (sys.stdin,sys.stdout,sys.stderr) if x.encoding is None] :
import os
defEnc = None
if defEnc is None :
try:
import locale
defEnc = locale.getpreferredencoding()
except: pass
if defEnc is None :
try: defEnc = sys.getfilesystemencoding()
except: pass
if defEnc is None :
try: defEnc = sys.stdin.encoding
except: pass
if defEnc is None :
defEnc = last_resort_default
os.environ['PYTHONIOENCODING'] = os.environ.get("PYTHONIOENCODING",defEnc)
os.execvpe(sys.argv[0],sys.argv,os.environ)
__fix_io_encoding() ; del __fix_io_encoding
Да, здесь можно получить бесконечный цикл, если этот "setenv" не работает.
В Windows у меня очень часто возникала эта проблема при запуске кода Python из редактора (например, Sublime Text), но не при его запуске из командной строки.
В этом случае проверьте параметры вашего редактора. В случае SublimeText этоPython.sublime-build решил это:
{
"cmd": ["python", "-u", "$file"],
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"selector": "source.python",
"encoding": "utf8",
"env": {"PYTHONIOENCODING": "utf-8", "LANG": "en_US.UTF-8"}
}
В Ubuntu 12.10 и GNOME Terminal ошибка не возникает, когда программа печатает на стандартный вывод или подключается к каналу для других программ. Кодировка файла и кодирование терминала - UTF-8.
$ cat a.py
# -*- coding: utf-8 -*-
print "åäö"
$ python a.py
åäö
$ python a.py | tee out
åäö
Какую ОС и эмулятор терминала вы используете? Я слышал, что у некоторых из моих коллег есть похожие проблемы при использовании iTerm 2 и OS X; iTerm 2 может быть виновником.
Обновление: этот ответ неправильный - подробности см. В комментариях