Кластеризация слов с использованием numpy и nltk или CLUTO в программировании на Python
Я пытаюсь объединить некоторые слова.
Некоторая часть моих данных, как показано ниже (это просто пример).
cat dog horse ostrich
cat 8 2.3 3.4 4.7
dog 7 8 3 2.4
horse 3.4 2.5 8 1.5
ostrich 3.4 3.2 4.4 8
Большее число означает, что сходство между двумя словами выше. Основываясь на данных этого формата, я хочу сделать кластеры (например, (кошка, собака), (лошадь), (страус) всего 3 кластера).
Сначала я попытался использовать CLUTO..., чтобы создать несколько кластеров и (очень красивый) график, как показано ниже.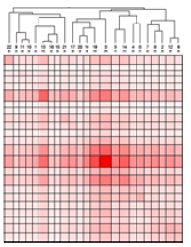
Но я не могу... Я уже видел руководства, но это не так легко понять. Итак, я попытался использовать некоторые библиотеки кластеризации в nltk, такие как k-means..etc. Но я не знаю, как я могу создать график, как указано выше. (также я должен сделать несколько кластеров на основе входных данных)
1 ответ
Представленное вами изображение представляет собой иерархический кластер. В отличие от "типичного" кластерного анализа, он показывает не один способ кластеризации данных, а все возможные способы сделать это для всех возможных количеств кластеров. Вы получаете один "набор кластеров", подсчитывая пересечения иерархии с произвольной горизонтальной линией в изображении иерархии.
Алгоритм K-средних, OTOH, зависит от того, сколько вы предоставляете нужных вам кластеров, поэтому вы не можете создать иерархию из него. NLTK , похоже, не предоставляет инструментов для иерархического кластерного анализа.
Вероятно, вам следует ознакомиться с основными концепциями кластеризации, прежде чем решить, какой выход вы хотите