Добавьте метки подгруппы / элементы порядка на оси x в ggplot2 r
Я пытаюсь добавить sub-group labels и упорядочить наблюдения по оси X в моем ggplot2. Здесь уже есть несколько вопросов по этому поводу, но во всех ответах рекомендуется использовать фасетку (например, здесь). Мой сюжет уже огранен, так что эти ответы не работают для меня. Я пытался с помощью reorder(x, by_this_variable) но кажется, что это работает, только если by_this_variable является осью Y. Зачем? Если я пытаюсь изменить его порядок на другую переменную, я получаю предупреждение:
аргумент не является числовым или логическим
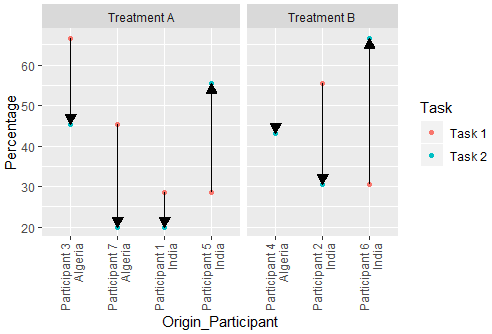
Чтобы быть более точным, я строю две точки (проценты от участника, полученные в двух разных задачах) для каждого дискретного значения оси X (1 для каждого участника) со стрелками, соединяющими точки для каждого участника. Это указывает на то, было ли на поведение участников оказано отрицательное или положительное влияние на задачи. Мои аспекты - это 2 разных состояния (лечение), в которые участники были случайным образом отсортированы. Теперь я хотел бы сгруппировать график с точками и стрелками в соответствии с различными источниками участников (возможный предиктор для разных ответов на лечение) и добавить эту информацию в качестве метки на оси X, но все, чего я могу достичь прямо сейчас, - это иметь значения отсортированы в алфавитном порядке (по умолчанию).
Этот сюжет может оказаться слишком занятым. Если есть лучший способ отобразить всю эту информацию (относительное изменение поведения по заданию, участнику, условию, происхождению) в одном графике, я открыт для предложений!
Мой код:
Data <- data.frame(c(28.5, 20, 55.4, 30.5, 66.6, 45.4, 43.2, 43.1, 28.5, 55.4, 30.5,
66.6, 45.4, 20), c("Participant 1", "Participant 1",
"Participant 2", "Participant 2", "Participant 3",
"Participant 3","Participant 4", "Participant 4","Participant 5",
"Participant 5", "Participant 6", "Participant 6", "Participant 7",
"Participant 7"),c("India", "India", "India", "India", "Algeria",
"Algeria", "Algeria", "Algeria", "India", "India", "India",
"India", "Algeria", "Algeria"),c("Treatment A", "Treatment A",
"Treatment B", "Treatment B","Treatment A", "Treatment A",
"Treatment B", "Treatment B", "Treatment A", "Treatment A",
"Treatment B", "Treatment B", "Treatment A", "Treatment A"),
c("Task 1", "Task 2", "Task 1", "Task 2", "Task 1", "Task 2",
"Task 1", "Task 2", "Task 1", "Task 2", "Task 1", "Task 2",
"Task 1", "Task 2"))
colnames(Data) <- c("Percentage", "Participant", "Origin", "Treatment", "Task")
ggplot(Data, aes(y=Percentage, x = Participant, group = Participant))+
geom_point(aes(color = Task))+
geom_line(arrow = arrow(length=unit(0.30,"cm"), type = "closed"), size = .3)+
facet_grid(~Treatment, scales = "free_x", space = "free_x")+
theme(axis.text.x = element_text(angle = 90, hjust = 1))
Это дает следующий сюжет:
Участники 1 и 5 - из Индии, а 3 и 7 - из Алжира, поэтому я хотел бы сгруппировать их по оси X и добавить метку происхождения.
РЕДАКТИРОВАТЬ:
Вышеприведенное предупреждение, по-видимому, связано с тем, что Origin является многоуровневым фактором (и переупорядочение, по-видимому, работает только с числовыми значениями), поэтому установка x = reorder(Participant, as.numeric(Origin)) упорядочит значения в соответствии с Origin, но как я могу добавить соответствующие метки Origin под сюжетом?
1 ответ
Одно из предложений - использовать упорядоченный фактор. Для уровней коэффициента сцепления Origin а также Participant, Для меток фактора, объединить Participant а также Origin,
# The unique values from the column 'Origin_Participant' will act as the levels
# of the factor. The order is imposed by 'Origin', so that participants from
# same country group together.
Data$Origin_Participant <- paste(Data$Origin, Data$Participant, sep = "\n")
# The unique values from 'Participant_Origin' column will be used for the
# factor' labels (what will end up on the plot).
Data$Participant_Origin <- paste(Data$Participant, Data$Origin, sep = "\n")
# Order data.frame by 'Origin_Participant'. Is also important so that the levels
# correspond to the labels of the factor when creating it below.
Data <- Data[order(Data$Origin_Participant),]
# Or in decreasing order if you need
# Data <- Data[order(Data$Origin_Participant, decreasing = TRUE),]
# Finally, create the needed factor.
Data$Origin_Participant <- factor(x = Data$Origin_Participant,
levels = unique(Data$Origin_Participant),
labels = unique(Data$Participant_Origin),
ordered = TRUE)
library(ggplot2)
# Reuse your code, but map the factor `Origin_Participant` into x. I think there
# is no need of a grouping factor. I also added vjust = 0.5 to align the labels
# on the vertical center.
ggplot(Data, aes(y=Percentage, x = Origin_Participant))+
geom_point(aes(color = Task))+
geom_line(arrow = arrow(length=unit(0.30,"cm"), type = "closed"), size = .3)+
facet_grid(~Treatment, scales = "free_x", space = "free_x")+
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5))
Если тебе все равно Origin сначала появляется в метках, затем на несколько шагов короче:
Data$Origin_Participant <- factor(x = paste(Data$Origin, Data$Participant, sep = "\n"),
ordered = TRUE)
ggplot(Data, aes(y=Percentage, x = Origin_Participant))+
geom_point(aes(color = Task))+
geom_line(arrow = arrow(length=unit(0.30,"cm"), type = "closed"), size = .3)+
facet_grid(~Treatment, scales = "free_x", space = "free_x")+
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5))