Как применить отдельную ord_cartesian() для "увеличения" отдельных панелей facet_grid()?
Вдохновленный Q Находя локоть / колено в кривой, я начал играть с smooth.spline(),
В частности, я хочу визуализировать, как параметр df (степень свободы) влияет на приближение и первую и вторую производную. Обратите внимание, что этот вопрос касается не аппроксимации, а конкретной проблемы (или граничного случая) при визуализации с ggplot2,
Первая попытка: простая facet_grid()
library(ggplot2)
ggplot(ap, aes(x, y)) +
geom_point(data = dp, alpha = 0.2) +
geom_line() +
facet_grid(deriv ~ df, scales = "free_y", labeller = label_both) +
theme_bw()

dp является таблицей данных, содержащей точки данных, для которых ищется приближение, и ap является таблицей данных с аппроксимированными данными плюс производные (данные приведены ниже).
Для каждого ряда facet_grid() с scales = "free_y" выбрал шкалу, которая отображает все данные. К сожалению, одна панель имеет своего рода "выбросы", которые затрудняют просмотр деталей на других панелях. Итак, я хочу "увеличить".
"Увеличить" с помощью coord_cartesian()
ggplot(ap, aes(x, y)) +
geom_point(data = dp, alpha = 0.2) +
geom_line() +
facet_grid(deriv ~ df, scales = "free_y", labeller = label_both) +
theme_bw() +
coord_cartesian(ylim = c(-200, 50))

С выбранным вручную диапазоном, больше деталей на панелях строки 3 стало видимым. Но предел был применен ко всем панелям сетки. Итак, в строке 1 детали вряд ли можно выделить.
То, что я ищу, это способ применения coord_cartesian() с конкретными параметрами отдельно для каждой отдельной панели (или группы панелей, например, в ряд) сетки. Например, можно ли манипулировать ggplot объект потом?
Обходной путь: Объедините отдельные участки с cowplot
В качестве обходного пути мы можем создать три отдельных графика и затем объединить их, используя cowplot пакет:
g0 <- ggplot(ap[deriv == 0], aes(x, y)) +
geom_point(data = dp, alpha = 0.2) +
geom_line() +
facet_grid(deriv ~ df, scales = "free_y", labeller = label_both) +
theme_bw()
g1 <- ggplot(ap[deriv == 1], aes(x, y)) +
geom_line() +
facet_grid(deriv ~ df, scales = "free_y", labeller = label_both) +
theme_bw() +
coord_cartesian(ylim = c(-50, 50))
g2 <- ggplot(ap[deriv == 2], aes(x, y)) +
geom_line() +
facet_grid(deriv ~ df, scales = "free_y", labeller = label_both) +
theme_bw() +
coord_cartesian(ylim = c(-200, 100))
cowplot::plot_grid(g0, g1, g2, ncol = 1, align = "v")

К сожалению, это решение
- требует написания кода для создания трех отдельных участков,
- дублирует полосы и оси и добавляет пробелы, которые недоступны для отображения данных.
Является facet_wrap() альтернатива?
Мы можем использовать facet_wrap() вместо facet_grid():
ggplot(ap, aes(x, y)) +
# geom_point(data = dp, alpha = 0.2) + # this line causes error message
geom_line() +
facet_wrap(~ deriv + df, scales = "free_y", labeller = label_both, nrow = 3) +
theme_bw()

Теперь, оси Y каждой панели масштабируются индивидуально, показывая детали некоторых панелей. К сожалению, мы все еще не можем "увеличить" нижнюю правую панель, потому что coord_cartesian() повлияет на все панели.
Кроме того, линия
geom_point(data = dp, alpha = 0.2)
странно вызывает
Ошибка в gList(список (x = 0.5, y = 0.5, width = 1, height = 1, just = "center",: в "gList" разрешены только "grobs")
Я должен был закомментировать эту строку, поэтому точки данных, которые должны быть аппроксимированы, не отображаются.
Данные
library(data.table)
# data points
dp <- data.table(
x = c(6.6260, 6.6234, 6.6206, 6.6008, 6.5568, 6.4953, 6.4441, 6.2186,
6.0942, 5.8833, 5.7020, 5.4361, 5.0501, 4.7440, 4.1598, 3.9318,
3.4479, 3.3462, 3.1080, 2.8468, 2.3365, 2.1574, 1.8990, 1.5644,
1.3072, 1.1579, 0.95783, 0.82376, 0.67734, 0.34578, 0.27116, 0.058285),
y = 1:32,
deriv = 0)
# approximated data points and derivatives
ap <- rbindlist(
lapply(seq(2, length(dp$x), length.out = 4),
function(df) {
rbindlist(
lapply(0:2,
function(deriv) {
result <- as.data.table(
predict(smooth.spline(dp$x, dp$y, df = df), deriv = deriv))
result[, c("df", "deriv") := list(df, deriv)]
})
)
})
)
0 ответов
Поздний ответ, но следующий взлом только что произошел со мной. Будет ли это работать для вашего случая использования?
Шаг 1 Создайте альтернативную версию предполагаемого графика, ограничив диапазон значений y так, чтобы scales = "free_y" дает желаемый диапазон шкалы для каждого ряда фасетов. Также создайте предполагаемый фасетный график с полным диапазоном данных:
library(ggplot2)
library(dplyr)
# alternate plot version with truncated data range
p.alt <- ap %>%
group_by(deriv) %>%
mutate(upper = quantile(y, 0.75),
lower = quantile(y, 0.25),
IQR.multiplier = (upper - lower) * 10) %>%
ungroup() %>%
mutate(is.outlier = y < lower - IQR.multiplier | y > upper + IQR.multiplier) %>%
mutate(y = ifelse(is.outlier, NA, y)) %>%
ggplot(aes(x, y)) +
geom_point(data = dp, alpha = 0.2) +
geom_line() +
facet_grid(deriv ~ df, scales = "free_y", labeller = label_both) +
theme_bw()
# intended plot version with full data range
p <- p.alt %+% ap
Шаг 2 использование ggplot_build() генерировать данные графика для обоих объектов ggplot. Примените параметры панели альтернативной версии к предполагаемой версии:
p <- ggplot_build(p)
p.alt <- ggplot_build(p.alt)
p$layout$panel_params <- p.alt$layout$panel_params
rm(p.alt)
Шаг 3 Создайте предполагаемый график из измененных данных графика и подготовьте результат:
p <- ggplot_gtable(p)
grid::grid.draw(p)
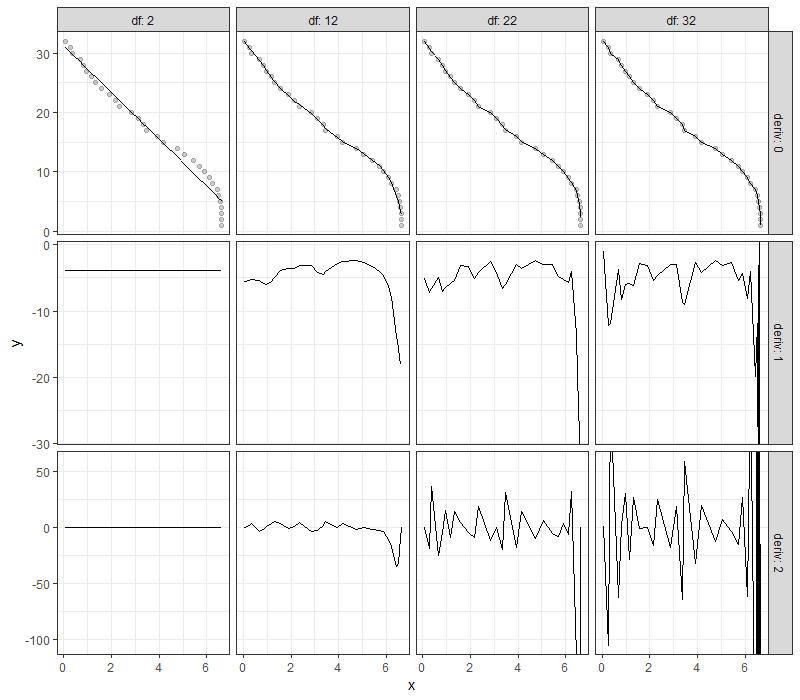
Примечание: в этом примере я обрезал диапазон данных, установив все значения более 10*IQR от верхнего / нижнего квартиля в каждой строке фасетов как NA. Это может быть заменено любой другой логикой для определения выбросов.