Проблемы настройки производственного кластера Apache kafka
Мы пытались настроить производственный уровень кластера Kafka на машинах AWS Linux, и до сих пор у нас не получалось.
Кафка версия: 2.1.0
Машины:
5 r5.xlarge machines for 5 Kafka brokers.
3 t2.medium zookeeper nodes
1 t2.medium node for schema-registry and related tools. (a Single instance of each)
1 m5.xlarge machine for Debezium.
Конфигурация брокера по умолчанию:
num.partitions=15
min.insync.replicas=1
group.max.session.timeout.ms=2000000
log.cleanup.policy=compact
default.replication.factor=3
zookeeper.session.timeout.ms=30000
Наша проблема в основном связана с огромными данными. Мы пытаемся перенести наши существующие таблицы в темы кафки, используя дебезиум. Многие из этих таблиц довольно огромны и содержат более 50000000 строк.
До сих пор мы пробовали много вещей, но наш кластер дает сбой каждый раз по одной или нескольким причинам.
ОШИБКА Неопределенное исключение в запланированной задаче "истечение срока действия isr" (kafka.utils.KafkaScheduler) org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Срок действия сеанса истек для /brokers/themes/__consumer_offsets/partitions/0/state at org. zookeeper.KeeperException.create(KeeperException.java:130) по адресу org.apache.zookeeper.KeeperException.create(KeeperException.java:54)..
Ошибка 2:
] INFO [Partition xxx.public.driver_operation-14 broker = 3] Кэшированный zkVersion [21] не равен значению в zookeeper, пропустите обновление ISR (kafka.cluster.Partition) [2018-12-12 14:07:26,551] ИНФО [Partition xxx.public.hub-14 broker=3] Сокращение ISR с 1,3 до 3 (kafka.cluster.Partition) [2018-12-12 14: 07: 26,556] ИНФОРМАЦИЯ [Partition xxx.public.hub-14 broker=3] Кэшированный zkVersion [3] не равен значению в zookeeper, пропустите обновление ISR (kafka.cluster.Partition) [2018-12-12 14:07:26,556] INFO [Partition xxx.public.field_data_12_2018-7 broker=3] Сокращение ISR с 1,3 до 3 (kafka.cluster.Partition)
Ошибка 3:
изоляция Level=READ_UNCOMMITTED, toForget=, метаданные =(sessionId=888665879, epoch=INITIAL)) (kafka.server.ReplicaFetcherThread) java.io.IOException: соединение с 3 было отключено до того, как ответ был прочитан в org.apache.kafka.c.NetworkClientUtils.sendAndReceive(NetworkClientUtils.java:97)
Еще несколько ошибок:
- Частые отключения среди брокеров, что, вероятно, является причиной непрерывного сокращения и расширения ISR без автоматического восстановления.
- Реестр схемы истекает. Я не знаю, как это влияет на реестр схем. Я не вижу слишком большой нагрузки на этом сервере. Я что-то пропустил? Должен ли я использовать балансировщик нагрузки для нескольких экземпляров схемы Registry в качестве аварийного переключения?, В теме __schemas всего 28 сообщений. Точное сообщение об ошибке RestClientException: регистрация операции истекло. Код ошибки: 50002
Иногда скорость передачи сообщений превышает 100000 сообщений в секунду, иногда она падает до 2000 сообщений в секунду? размер сообщения может вызвать это?
Чтобы решить некоторые из вышеперечисленных проблем, мы увеличили количество брокеров и увеличили zookeeper.session.timeout.ms=30000, но я не уверен, действительно ли это решило нашу проблему, и если да, то как?.
У меня есть несколько вопросов:
- Достаточно ли хорош наш кластер для обработки такого большого количества данных?
- Есть ли что-то очевидное, чего нам не хватает?
- Как я могу загрузить тестирование моей установки, прежде чем перейти на уровень производства?
- Что может вызвать тайм-ауты сеанса между брокерами и реестром схемы.
- Лучший способ справиться с проблемой реестра схемы.
Сетевая нагрузка на одного из наших брокеров.
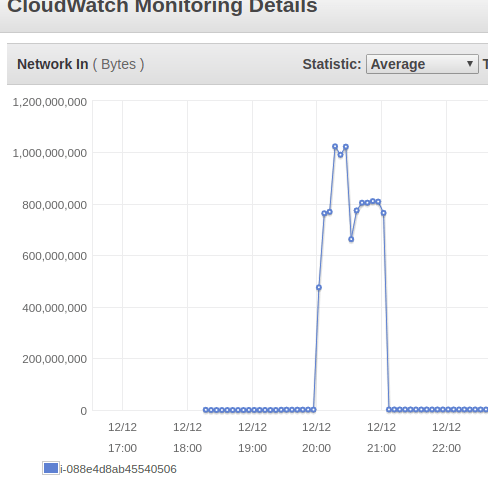
Не стесняйтесь спрашивать больше информации.
0 ответов
Пожалуйста, используйте последнюю официальную версию Confluent для вашего кластера.
На самом деле вы можете улучшить его, увеличив количество разделов ваших тем, а также увеличивtasks.max(конечно, в ваших соединителях раковины) больше 1 в вашем соединителе, чтобы работать более одновременно и быстрее.
Увеличьте количество тем Kafka-Connect и используйте распределенный режим Kafka-Connect, чтобы повысить высокую доступность вашего кластера Kafka-connect. вы можете сделать это, установив количество факторов репликации в конфигурации Kafka-Connect и Schema-Registry, например:
config.storage.replication.factor=2
status.storage.replication.factor=2
offset.storage.replication.factor=2
Пожалуйста, установите topic compression к snappyдля ваших больших столов. это увеличит пропускную способность тем, и это поможет соединителю Debezium работать быстрее, а также не использовать JSON Converter, рекомендуется использовать Avro Convertor!
Также используйте балансировщик нагрузки для своего реестра схем.
Для тестирования кластера можно создать коннектор только с одной таблицей (я имею в виду большую таблицу!) С database.whitelist и установить snapshot.mode к initial
И по поводу схемы-реестра! Пользователь схемы-реестра как Kafka, так и Zookeeper с настройкой этих конфигураций:
bootstrap.servers
kafkastore.connection.url
И в этом причина простоя вашего кластера shema-registry