Чрезмерная нагрузка на профилировщик с NVidia Visual Profiler
Я получаю много профилирования при попытке профилировать мой код с помощью nvvp (или с nvprof):
 Общее время составляет 98 мс, и я получаю 85 мс "Instrumentation" при первом запуске ядра.
Общее время составляет 98 мс, и я получаю 85 мс "Instrumentation" при первом запуске ядра.
Как я могу уменьшить эту нагрузку на профилирование или увеличить масштаб только той части, которая мне интересна?
Фон
Я запускаю это с "Не запускать запуск с включенным профилированием", и я ограничил использование профилирования cudaProfilerStart/cudaProfilerStop вот так:
/* --- generate data etc --- */
// Call the function once to warm up the FFT plan cache
applyConvolution( T, N, stride, plans, yData, phiW, fData, y_dwt );
gpuErrchk( cudaDeviceSynchronize() );
// Call it once for profiling
cudaProfilerStart();
applyConvolution( T, N, stride, plans, yData, phiW, fData, y_dwt );
gpuErrchk( cudaDeviceSynchronize() );
cudaProfilerStop();
где applyConvolution() это функция, которую я профилирую.
Я использую CUDA Toolkit 8.0 в Ubuntu 16.04 с GTX 1080.
2 ответа
Когда я писал этот вопрос, я подумал, что постараюсь поэкспериментировать с настройками профилировщика, чтобы попытаться исключить некоторые потенциальные материалы для ответов в комментариях.
К моему удивлению, отключение "Включить параллельное профилирование ядра" полностью избавило от накладных расходов профилировщика:
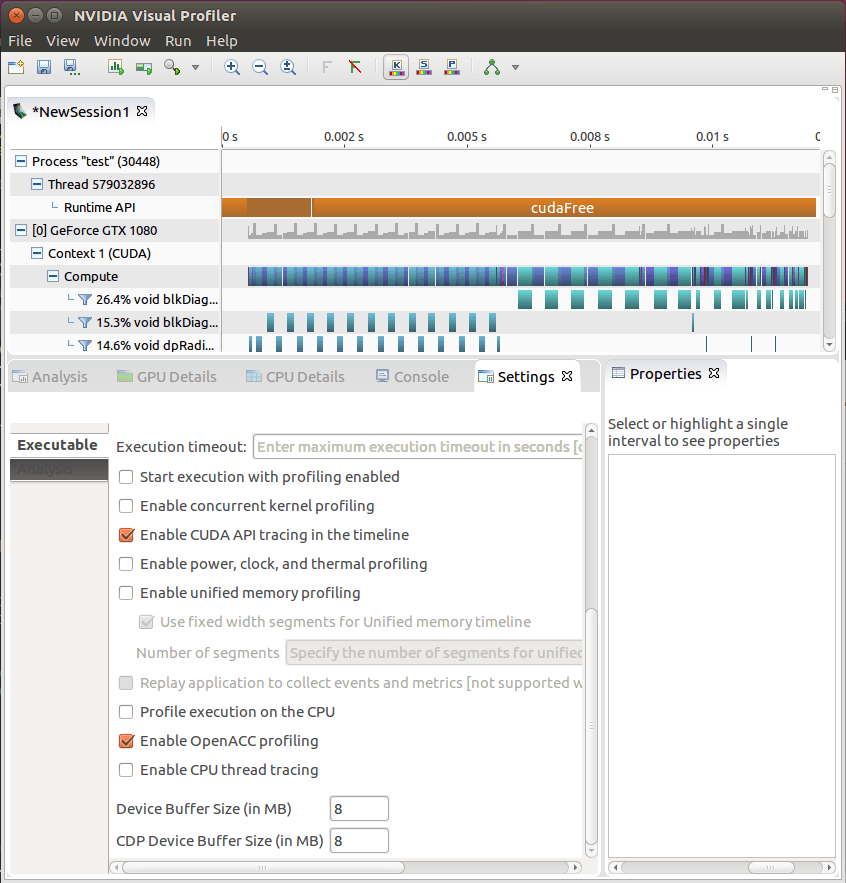
Но, возможно, это не должно было стать сюрпризом:
Включить параллельное профилирование ядра - этот параметр следует выбрать для приложения, использующего потоки CUDA для запуска ядер, которые могут выполняться одновременно. Если приложение использует только один поток (и, следовательно, не может одновременно выполнять ядро), отмена выбора этого параметра может снизить издержки профилирования.
(взято с http://docs.nvidia.com/cuda/profiler-users-guide/)
Более ранняя версия Руководства пользователя CUDA Profiler также отмечала в разделе "Ограничения профилирования", что:
Параллельный режим ядра может добавить значительные издержки, если используется в ядрах, которые выполняют большое количество блоков и имеют короткую продолжительность выполнения.
Ну что ж. Размещение этого вопроса / ответа в любом случае на случай, если это поможет кому-то другому избежать этого раздражения.
Я вижу нечто подобное, но это, возможно, только смутно связано. Но так как приведенный выше ответ помог, я добавлю свои наблюдения.
При профилировании Quadro GV100 наблюдается явное изменение производительности для довольно простых ядер по сравнению с картами паскаль-поколения (например, 1080). Я тоже запускаю nvvp с отключенным профилированием и активирую его в той части кода, которая мне интересна. Затем я случайно не включил его, и все, что я получил, это наши ручные маркеры событий (используя nvtxRangePush & nvtxRangePop). Что вы знаете, десятикратное ускорение. Так сказать; на Quadro GV100 есть огромные накладные расходы на профилирование, которых нет на GPU более ранних поколений.
Отключение параллельного профилирования, как вы это сделали, НЕ помогает, но отключение трассировки API НЕ ДАЕТ.
Хотя по сравнению с ручным nvtx все еще есть значительные накладные расходы, но, по крайней мере, это дает некоторое представление о производительности ядра на GV100. Большие ядра кажутся менее затронутыми, что естественно, если это связано с накладными расходами с фиксированной стоимостью или отслеживанием API. Осталось неизвестное, почему отслеживание API так дорого стоит именно для GV100, но я не могу спекулировать, по крайней мере, пока.
Я скомпилировал специфичные для sm двоичные файлы, используя gcc/5.4 и cuda/9.0 для вышеупомянутых тестов, и запустил однопоточную RELION для простого тестового примера.