Pentaho Импорт уникальных записей в базу данных
Я совершенно новичок в Pentaho Spoon, и я хотел бы импортировать записи файла CSV в таблицу базы данных. Однако в таблицу базы данных должны быть импортированы только уникальные записи. Вот почему мне нужно сравнить КАЖДУЮ запись со всеми записями таблицы базы данных, чтобы определить, следует ли импортировать запись или нет.
До сих пор я опробовал предложенный CRUD-шаблон, который выглядит следующим образом: 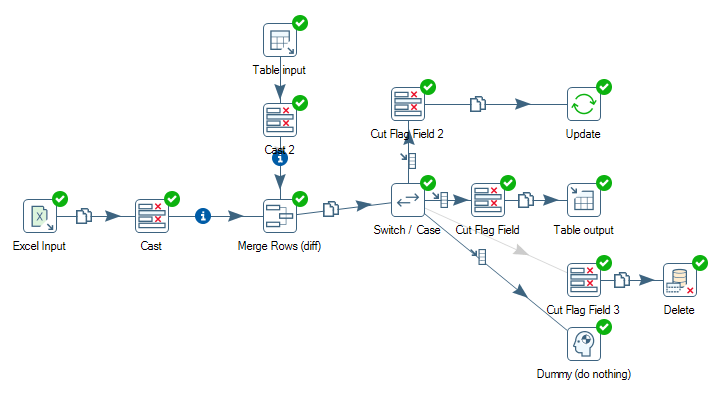
Как вы можете видеть на рисунке, я объединяю входные данные Excel и входные данные таблицы (не обращайте внимания на шаги приведения. Мне нужно было привести значение, потому что они отличались форматом float: формат базы данных был #.000000 и формат csv float был #.0)
После объединения слиянием я сравниваю флаг (который задается строками слияния (diff) и, если сравниваемые записи являются новыми, я импортирую их в таблицу базы данных, если они изменяются, я обновляю запись, и если они удаляются или идентично, я просто ничего не делаю. Пока все хорошо.
Но вот проблема: если я перетасую записи csv-input-file и заново запускаю преобразование, все записи импортируются заново и, следовательно, они дублируются в моей таблице базы данных (чего я хотел избежать). Подчеркнем еще раз: правильный способ решить эту проблему состоит в том, что каждая строка csv-input-file сравнивается со ВСЕМИ записями в таблице базы данных.
Как я могу это понять? Какие-либо предложения? Огромное спасибо заранее!!
2 ответа
Вы можете использовать элемент управления поиском / обновлением Dimension, который предоставляет те же функциональные возможности, которых вы пытаетесь достичь.
Спасибо нилеш
Merge Rows (diff) ожидать, что вход будет отсортирован. Обычно вы были предупреждены об этом всплывающим окном.
Положить Sort rows войти в поток вывода ввода Excel, прежде чем он достигнет Merge Rows (diff),
Вы должны сделать то же самое между Table Input и Merge Rows (diff), Конечно, вы можете подумать, что вы можете сделать это в SQL-выражении Table Input,
Однако здесь есть ловушка для начинающих. У вас есть 3 других шага Output Rows, Update а также Delete который работает на том же столе. И эти шаги могут заблокировать стол. Так как в Kettle все шаги выполняются одновременно, вы не знаете, какие шаги будут запущены первыми, и таблица может быть заблокирована и никогда не сможет прочитать даже первую запись. В жаргоне это известно как автоблокировка, и для ее решения нужно поставить Sort Row шаг в качестве буфера.