Как сделать добавочную загрузку в SSIS
У меня есть источник Oracle 12C и место назначения SQL Server. В таблицах фактов мне нужно делать ежедневный снимок (не все данные), а в таблицах измерений мне нужно брать только новые строки, а не всю таблицу. Похоже, что невозможно использовать переменные на стороне Oracle. Каков наилучший подход?
1 ответ
**
Принимая только сегодняшние данные:
** У меня был очень хороший успех при использовании соединителей Oracle Attunity. Когда вы используете их для настройки источника Oracle, вы можете определить источник либо как имя таблицы / представления, либо как запрос SQL. Когда вы сделаете это, вы можете добавить WHERE условия к вашему запросу.
Простая версия этой техники будет выглядеть так:
Но если вы хотите использовать дату, которая не жестко запрограммирована в запросе, вам нужно создать выражение. Это похоже, но вы добавляете Execute SQL Task перед потоком данных, и построить там динамический SQL-запрос и сохранить его в переменной. Затем вы можете использовать эту переменную для определения выражения для запроса исходного кода Oracle.
Используя ту же таблицу, что и раньше, вот как я извлекаю последние 3 месяца записей:
Затем выберите задачу "Поток данных" и посмотрите в окно "Свойства". В разделе "Разное" вы должны увидеть строку для вашего [Oracle Source].[SqlCommand], Вы можете зайти в редактор выражений здесь и установить свою переменную как SqlCommand.
Взятие только обновленных строк:
Для этого вы можете использовать метод, который сравнивает значения хеш-функции из вашего источника с значениями в месте назначения, чтобы определить, изменилась ли строка.
Первое, что вам нужно сделать, это импортировать все ваши данные, включая хэш данных строки.
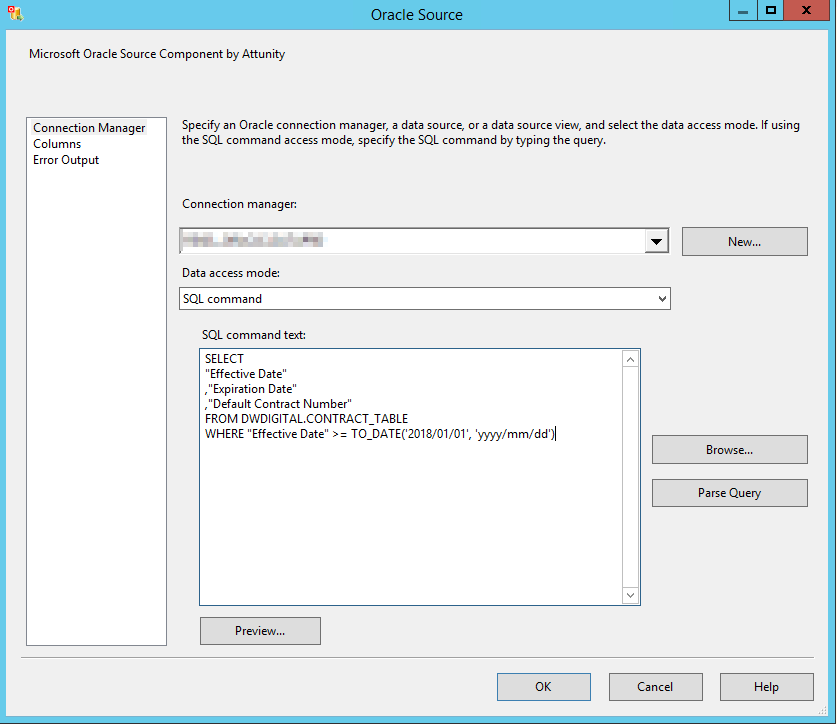
Определите ваш источник Oracle для использования команды SQL в качестве режима доступа к данным. Вот пример с моей таблицей:
SELECT
CAST("Data Source Code" AS VARCHAR2(3)) AS "DataSourceCode"
,"Matrix Id" AS "MatrixId"
,CAST("Primary Matrix Type" AS VARCHAR2(11)) AS "PrimaryMatrixType"
,CAST("Branch Number" AS VARCHAR2(4)) AS "BranchId"
,"Effective Date" AS "EffectiveDate"
,"Expiration Date" AS "ExpirationDate"
,"Spa Flag" AS "SpaFlag"
,CAST("Default Contract Number" AS VARCHAR2(50)) AS "DefaultContractNumber"
,CAST("Direct Contract Number" AS VARCHAR2(50)) AS "DirectContractNumber"
,"Refresh Date" AS "RefreshDate"
,CAST(UPPER(RAWTOHEX(SYS.DBMS_OBFUSCATION_TOOLKIT.MD5(input_string =>
CAST("Data Source Code" AS VARCHAR2(3)) || '|' ||
"Matrix Id" || '|' ||
CAST("Primary Matrix Type" AS VARCHAR2(11)) || '|' ||
CAST("Branch Number" AS VARCHAR2(4)) || '|' ||
CAST("Effective Date" AS VARCHAR2(30)) || '|' ||
CAST("Expiration Date" AS VARCHAR2(30)) || '|'||
"Spa Flag" || '|' ||
CAST("Default Contract Number" AS VARCHAR2(50)) || '|' ||
CAST("Direct Contract Number" AS VARCHAR2(50))
))) AS VARCHAR2(32)) AS "HashVal"
FROM DWDIGITAL.CONTRACT_TABLE
WHERE "Effective Date" >= TO_DATE('2018/01/01', 'yyyy/mm/dd')
я использую SYS.DBMS_OBFUSCATION_TOOLKIT здесь, чтобы сгенерировать хеш-значение MD5, используя объединенную строку всех данных столбца строки (убедитесь, что все столбцы преобразованы в строки для хэша). я использую SYS.DBMS_OBFUSCATION_TOOLKIT вместо ORA_HASH потому что у меня ограниченные разрешения на сервере Oracle, и SYS.DBMS_OBFUSCATION_TOOLKIT не нуждается в расширенных привилегиях, таких как ORA_HASH делает. Я также выбираю MD5 здесь, потому что если мне нужно сгенерировать хеш-значение на стороне SQL, после этого я все равно могу сгенерировать те же хеш-значения, поскольку SQL Server также может использовать алгоритм MD5. Если бы у вас был доступ к ORA_HASH Вы можете использовать один из алгоритмов SHA*. Также обратите внимание, что я добавляю | между каждым столбцом в расчете хеша. Это так что "My"+"text" а также "Myt"+"ext" будет генерировать различные хэши и предотвращать ложный положительный результат, потому что My|text а также Myt|ext разные.
Итак, теперь у вас есть таблица назначения, загруженная вашими данными и хешами ваших данных. Чтобы создать итеративную загрузку, сначала необходимо создать "кэш" ключей и значений хеш-функции из пункта назначения. Добавьте задачу "Поток данных" и создайте исходное соединение, которое указывает на таблицу назначения, и направьте этот поток в Cache Transform,
Преобразование кэша будет использоваться для выполнения преобразований поиска в следующем DFT. Вам необходимо настроить файл кэша и столбцы для кэширования.
Мой первичный ключ установлен в положение индекса 1.
Следующий поток данных будет выглядеть примерно так:
Соединение с источником здесь будет использовать тот же запрос, который вы использовали во время начальной загрузки выше. Затем вы создаете преобразование "Уточняющий запрос" и добавляете кэшированный HashVal в качестве нового столбца.
У вас должно быть два выхода здесь. Вывод "Нет совпадения" - это строки из источника, где ключ не существует в месте назначения. Это новые строки для вставки. Затем возьмите "Соответствующий" вывод и укажите его на "Условное разделение". Условный Split будет сравнивать HashVals. Соответствующие HashVals указывают на отсутствие изменений в строке. Несоответствие HashVals указывает, что запись изменилась. Я загружаю эти записи в промежуточную таблицу и использую хранимый вызов proc, чтобы сделать UPDATE операция.