Как мне изменить этот набор данных в пандах Python?
Скажем, у меня есть такой набор данных:
is_a is_b is_c population infected
1 0 1 50 20
1 1 0 100 10
0 1 1 20 10
...
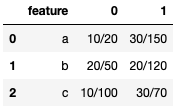
Как мне изменить это, чтобы выглядеть так?
feature 0 1
a 10/20 30/150
b 20/50 20/120
c 10/100 30/70
...
В исходном наборе данных у меня есть особенности a, b, а также c как свои отдельные столбцы. В преобразованном наборе данных эти же переменные перечислены в столбце featureи две новые колонки 0 а также 1 производятся в соответствии со значениями, которые могут принимать эти функции.
В исходном наборе данных, где is_a является 0, добавлять infected ценности и разделить их на population ценности. куда is_a является 1сделать то же самое, добавить infected ценности и разделить их на population ценности. Промыть и повторить для is_b а также is_c, Новый набор данных будет иметь эти доли (или десятичные дроби), как показано. Спасибо!
я пробовал pd.pivot_table а также pd.melt но ничто не приближается к тому, что мне нужно.
3 ответа
После выполнения wide_to_long, ваш вопрос понятнее
df=pd.wide_to_long(df,['is'],['population','infected'],j='feature',sep='_',suffix='\w+').reset_index()
df
population infected feature is
0 50 20 a 1
1 50 20 b 0
2 50 20 c 1
3 100 10 a 1
4 100 10 b 1
5 100 10 c 0
6 20 10 a 0
7 20 10 b 1
8 20 10 c 1
df.groupby(['feature','is']).apply(lambda x : sum(x['infected'])/sum(x['population'])).unstack()
is 0 1
feature
a 0.5 0.200000
b 0.4 0.166667
c 0.1 0.428571
Я пробовал это на вашем маленьком фрейме данных, но я не уверен, что он будет работать с большим набором данных.
dic_df = {}
for letter in ['a', 'b', 'c']:
dic_da = {}
dic_da[0] = df[df['is_'+str(letter)] == 0].infected.sum()/df[df['is_'+str(letter)] == 0].population.sum()
dic_da[1] = df[df['is_'+str(letter)] == 1].infected.sum()/df[df['is_'+str(letter)] == 1].population.sum()
dic_df[letter] = dic_da
dic_df
dic_df_ = pd.DataFrame(data = dic_df).T.reset_index().rename(columns= {'index':'feature'})
feature 0 1
0 a 0.5 0.200000
1 b 0.4 0.166667
2 c 0.1 0.428571
Здесь DF будет вашим оригинальным DataFrame
Aux_NewDF = [{'feature': feature,
0 : '{}/{}'.format(DF['infected'][DF['is_{}'.format(feature.lower())]==0].sum(), DF['population'][DF['is_{}'.format(feature.lower())]==0].sum()),
1 : '{}/{}'.format(DF['infected'][DF['is_{}'.format(feature.lower())]==1].sum(), DF['population'][DF['is_{}'.format(feature.lower())]==1].sum())} for feature in ['a','b','c']]
NewDF = pd.DataFrame(Aux_NewDF)