Почему RDBMS не допускает разбиения в теореме CAP и почему она доступна?
Два момента, которые я не понимаю, о том, что СУБД - это CA в теореме CAP:
1) В нем говорится, что RDBMS не допускает разделения, но как RDBMS менее терпимо относится к разделу, чем другие технологии, такие как MongoDB или Cassandra? Существует ли настройка СУБД, в которой мы отказываемся от CA, чтобы сделать его AP или CP?
2) Как это CAP-доступно? Это через настройку ведущий-ведомый? Как в случае, когда мастер умирает, раб берет на себя записи?
Я новичок в архитектуре БД и теореме CAP, поэтому, пожалуйста, потерпите меня.
2 ответа
Очень легко неправильно понять свойства CAP, поэтому я привожу несколько иллюстраций, чтобы упростить задачу.
Согласованность: запрос Q даст один и тот же ответ A независимо от узла, обрабатывающего запрос. Чтобы гарантировать полную согласованность, нам необходимо убедиться, что все узлы всегда согласовывают одно и то же значение. Не следует путать с конечной согласованностью, при которой сеть движется к согласованности всех данных, но есть периоды времени, в которые это не так.
Доступность: если распределенная система получает запрос Q, она всегда будет давать ответ на этот запрос. Это не следует путать с "высокой доступностью", речь идет не о способности обрабатывать более высокую производительность запросов, а о том, чтобы не отказываться от ответа.
Допуск раздела: система продолжает функционировать, несмотря на наличие раздела. Речь идет не о наличии механизмов "исправления" раздела, а о том, чтобы выдержать разделение, то есть продолжать работу, несмотря на разделение.
Обратите внимание, что следующие примеры не охватывают все возможные сценарии. Обратите внимание на следующую подпись:

Пример для CP:

Система терпима к разделам, потому что ее узлы продолжают принимать запросы, несмотря на разделение; он согласован, потому что единственные узлы, предоставляющие ответы, - это те, которые поддерживают соединение с главным узлом, который обрабатывает все запросы на запись; он недоступен, потому что узлы в другом разделе не дают ответа на полученные запросы.
Примеры для AP:
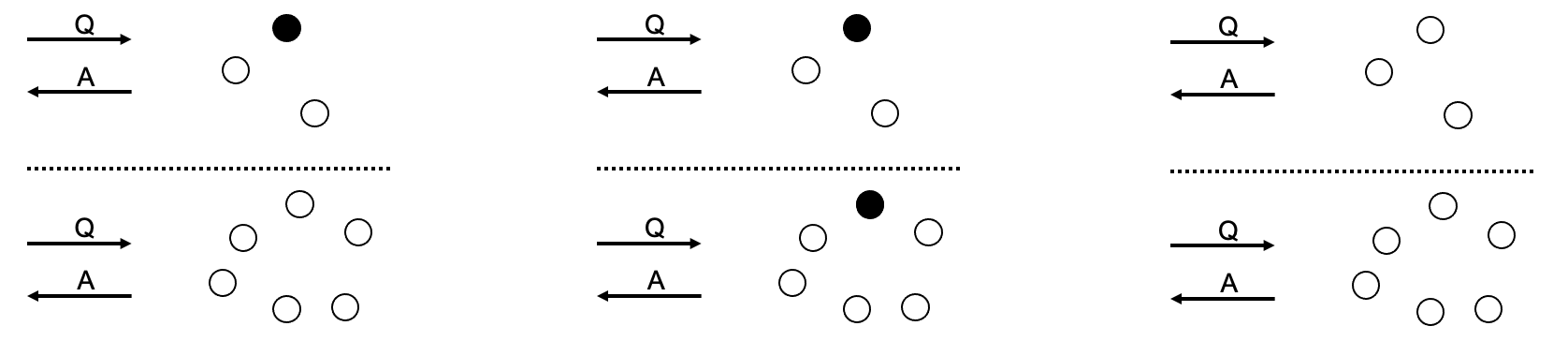
Либо потому, что (соответственно) у нас есть подчиненные узлы, отвечающие на запросы, независимо от того, могут ли они связаться с главным, либо потому, что подчиненные узлы в другом разделе выбирают нового главного, либо потому что у нас есть кластер без главного, доступность достигается, потому что все вопросы возникают ответ - согласованность нарушена, потому что оба раздела отвечают, потенциально приводя к разным состояниям.
Примеры для CA:

Если мы отключаем узлы при возникновении раздела, мы можем гарантировать, что у нас будет не более одного раздела, что в конечном итоге означает, что сеть больше не разделена, или просто нет службы вообще. Это противоположно допустимому разделению, потому что система избегает разделения, вместо того, чтобы работать, несмотря на это. Согласованность и доступность сохраняются в этих частично или полностью отключенных системах, потому что все рабочие узлы (если есть) имеют одинаковое состояние, и все полученные запросы (если есть) получат ответ - узлы выключения не получают запросы.
Чтобы ответить на вопросы:
В конфигурациях по умолчанию такие базы данных, как Cassandra и MongoDB, терпимы к разделам, поскольку они не отключают узлы, чтобы справиться с разделами, в отличие от СУБД, таких как MySQL.
Доступность имеет мало общего с настройкой ведущий / ведомый, например, Cassandra не имеет ведущего и очень доступна, потому что на самом деле не имеет значения, какой узел умирает. Что касается доступности в настройке "ведущий / ведомый", нет причин прекращать отвечать на все запросы, когда ведущее устройство не работает, но вам может потребоваться приостановить операции записи при выборе нового.
Многие базы данных в настоящее время фактически имеют разные конфигурации и, в зависимости от установленных вами настроек, это могут быть CA, CP, AP и т. Д., Но они не могут достичь всех трех одновременно. Некоторые базы данных на самом деле прилагают усилия для поддержки всех трех, но все же определяют их приоритеты определенным образом.
Например, MySQL может быть CP и CA в зависимости от конфигурации. По умолчанию это CA, поскольку он следует парадигме "ведущий-ведомый", данные которой реплицируются на ведомые. Допуск на разделы приносится в жертву в том случае, если набор рабов теряет связь с мастером и поэтому решает выбрать нового мастера, создав двух мастеров с собственным набором рабов.
Тем не менее, MySQL также имеет другую конфигурацию, которая является кластерной конфигурацией. Это определяет приоритет CP над доступностью, например. кластер отключится, если не будет достаточно живых узлов для обслуживания всех данных.
Вероятно, существует больше конфигураций для MySQL, которые позволяют ему удовлетворять другим комбинациям теоремы CAP, но в целом я просто хотел сказать, что это зависит от того, что требуется вашей системе. Иногда базы данных лучше подходят для одной конфигурации по сравнению с другой, поэтому лучше посмотреть, какие проблемы могут возникнуть при использовании определенной конфигурации.
Что касается реализации теоремы CAP, я бы посоветовал еще раз взглянуть на различные базы данных и на то, как они реализуют приоритеты для теоремы CAP. Существует слишком много разных способов их реализации, например. как правило, модель "ведущий-ведомый" используется для систем CA, хэш-кольцо для систем AP и т. д.
Теорема CAP проблематична и применима только к системам распределенных баз данных. Когда у вас есть распределенные базы данных, могут произойти сбой сетевого раздела и узла. И когда происходит разделение сети, вы должны иметь допуск раздела (P вашего CAP).
Итак, чтобы ответить на ваш вопрос № 1) Это либо СР, либо АР. Это может быть настроено как будет сказано.
Подробнее о том, почему допуск раздела является обязательным: https://codahale.com/you-cant-sacrifice-partition-tolerance/
Подробнее о проблемах, связанных с теоремой CAP: https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html
Я согласен, что RDBMS может иметь все свойства CAP. Я начал изучать базы данных noSQL и имел опыт работы с IBM DB2.
Вот как IBM DB2 удовлетворяет всем 3 свойствам CAP
C: Согласованность: каждая реляционная база данных удовлетворяет этому из-за транзакционной природы СУБД.
A: Доступность: Доступность означает, что когда выполняется запрос к существующим данным, они должны быть возвращены. Опять же, реляционная база данных разработана, чтобы сделать это легко.
П: Толерантность к разделу: это самый интересный. С точки зрения DB2, в приложении, над которым я работал, у нас было 2 базы данных, распределенные по разным центрам обработки данных. Один был первичным и общался со вторичным через сердцебиение. Каждая из этих первичных и вторичных баз данных имела 12 физических экземпляров, где данные распространялись на основе некоторой предопределенной логики. Если первичный выходит из строя, вторичный обнаруживает это и занимает место первичного. Поскольку первичный и вторичный всегда были синхронизированы, данные также остаются согласованными.
Вот как я думаю, что СУБД удовлетворяет всем 3 свойствам теоремы CAP.
Я могу ошибаться и открыта для обсуждения по этому вопросу.