Как сделать SPA SEO сканируемым?
Я работал над тем, чтобы сделать Google Crawlable SPA, основываясь на инструкциях Google. Несмотря на то, что существует довольно много общих объяснений, я нигде не смог найти более подробного пошагового руководства с реальными примерами. После этого я хотел бы поделиться своим решением, чтобы другие тоже могли его использовать и, возможно, улучшить.
я использую MVC с Webapi контроллеры, и Phantomjs на стороне сервера, и Durandal на стороне клиента с push-state включен; Я также использую Breezejs для взаимодействия данных между клиентом и сервером, что я настоятельно рекомендую, но я постараюсь дать достаточно общее объяснение, которое также поможет людям, использующим другие платформы.
7 ответов
Прежде чем начать, убедитесь, что вы понимаете, что требуется от Google, в частности, используйте красивые и уродливые URL-адреса. Теперь давайте посмотрим на реализацию:
Сторона клиента
На стороне клиента у вас есть только одна HTML-страница, которая динамически взаимодействует с сервером через вызовы AJAX. вот что такое SPA. Все a теги на стороне клиента создаются динамически в моем приложении, позже мы увидим, как сделать эти ссылки видимыми для бота Google на сервере. Каждый такой a тег должен иметь возможность иметь pretty URL в href тег, чтобы бот Google сканировал его. Вы не хотите href часть, которая будет использоваться, когда клиент нажимает на нее (даже если вы хотите, чтобы сервер мог ее проанализировать, мы увидим это позже), потому что мы можем не захотеть загружать новую страницу только для вызова AJAX получение некоторых данных для отображения на части страницы и изменение URL-адреса с помощью JavaScript (например, с использованием HTML5 pushstate или с Durandaljs). Итак, у нас есть href атрибут для Google, а также на onclick которая выполняет работу, когда пользователь нажимает на ссылку. Теперь, так как я использую push-state Я не хочу никаких # на URL, так что типичный a тег может выглядеть так: <a href="http://www.xyz.com/#!/category/subCategory/product111" onClick="loadProduct('category','subCategory','product111')>see product111...</a>
"Category" и "SubCategory", вероятно, будут другими фразами, такими как "связь" и "телефоны" или "компьютеры" и "ноутбуки" для магазина электротоваров. Очевидно, будет много разных категорий и подкатегорий. Как видите, ссылка непосредственно на категорию, подкатегорию и продукт, а не в качестве дополнительных параметров для конкретной страницы "магазина", такой как http://www.xyz.com/store/category/subCategory/product111, Это потому, что я предпочитаю более короткие и простые ссылки. Это означает, что у меня не будет категории с тем же именем, что и на одной из моих "страниц", то есть "около".
Я не буду вдаваться в то, как загрузить данные через AJAX (onclick часть), найдите его в Google, есть много хороших объяснений. Единственная важная вещь, о которой я хочу упомянуть, это то, что когда пользователь нажимает на эту ссылку, я хочу, чтобы URL в браузере выглядел так: http://www.xyz.com/category/subCategory/product111, И это URL не отправляется на сервер! помните, это SPA, где все взаимодействие между клиентом и сервером осуществляется через AJAX, никаких ссылок вообще! все "страницы" реализованы на стороне клиента, и другой URL не вызывает сервер (сервер должен знать, как обрабатывать эти URL в случае, если они используются в качестве внешних ссылок с другого сайта на ваш сайт, мы увидим это позже на стороне сервера). Теперь, с этим прекрасно справляется Дюрандаль. Я настоятельно рекомендую это сделать, но вы также можете пропустить эту часть, если предпочитаете другие технологии. Если вы выберете его, и вы также используете MS Visual Studio Express 2012 для Интернета, как я, вы можете установить Durandal Starter Kit, и там, в shell.js, используйте что-то вроде этого:
define(['plugins/router', 'durandal/app'], function (router, app) {
return {
router: router,
activate: function () {
router.map([
{ route: '', title: 'Store', moduleId: 'viewmodels/store', nav: true },
{ route: 'about', moduleId: 'viewmodels/about', nav: true }
])
.buildNavigationModel()
.mapUnknownRoutes(function (instruction) {
instruction.config.moduleId = 'viewmodels/store';
instruction.fragment = instruction.fragment.replace("!/", ""); // for pretty-URLs, '#' already removed because of push-state, only ! remains
return instruction;
});
return router.activate({ pushState: true });
}
};
});
Здесь следует отметить несколько важных вещей:
- Первый маршрут (с
route:'') для URL, в котором нет дополнительных данных, т.е.http://www.xyz.com, На этой странице вы загружаете общие данные, используя AJAX. Там может быть на самом деле нетaтеги вообще на этой странице. Вы захотите добавить следующий тег, чтобы бот Google знал, что с ним делать:<meta name="fragment" content="!">, Этот тег заставит бота Google преобразовать URL вwww.xyz.com?_escaped_fragment_=который мы увидим позже. - Маршрут "about" - это просто пример ссылки на другие "страницы", которые вы можете захотеть использовать в своем веб-приложении.
- Сложность в том, что здесь нет маршрута категории, и может быть много разных категорий, ни у одной из которых нет предопределенного маршрута. Это где
mapUnknownRoutesвходит. Он сопоставляет эти неизвестные маршруты с маршрутом "store", а также удаляет любые "!" с URL на случай, если этоpretty URLгенерируется поисковым движком Google. Маршрут store хранит информацию в свойстве фрагмента и вызывает AJAX-вызов для получения данных, их отображения и локального изменения URL-адреса. В моем приложении я не загружаю разные страницы для каждого такого вызова; Я изменяю только ту часть страницы, где эти данные имеют отношение, а также меняю местный URL. - Обратите внимание на
pushState:trueкоторый инструктирует Durandal использовать URL-адреса push-состояний.
Это все, что нам нужно на стороне клиента. Это может быть реализовано также с хешированными URL (в Durandal вы просто удаляете pushState:true для этого). Более сложной частью (по крайней мере для меня...) была серверная часть:
Сторона сервера
я использую MVC 4.5 на стороне сервера с WebAPI контроллеры. Сервер на самом деле должен обрабатывать 3 типа URL: сгенерированные Google - оба pretty а также ugly а также "простой" URL-адрес в том же формате, что и в браузере клиента. Давайте посмотрим, как это сделать:
Красивые и простые URL-адреса сначала интерпретируются сервером, как будто они пытаются сослаться на несуществующий контроллер. Сервер видит что-то вроде http://www.xyz.com/category/subCategory/product111 и ищет контроллер с именем "категория". Так в web.config Я добавляю следующую строку, чтобы перенаправить их на конкретный контроллер обработки ошибок:
<customErrors mode="On" defaultRedirect="Error">
<error statusCode="404" redirect="Error" />
</customErrors><br/>
Теперь это преобразует URL в нечто вроде: http://www.xyz.com/Error?aspxerrorpath=/category/subCategory/product111, Я хочу, чтобы URL-адрес отправлялся клиенту, который будет загружать данные через AJAX, поэтому хитрость здесь заключается в том, чтобы вызвать контроллер индекса по умолчанию, как если бы он не ссылался ни на один контроллер; Я делаю это путем добавления хеша к URL-адресу перед всеми параметрами 'category' и 'subCategory'; Для хешированного URL-адреса не требуется никакого специального контроллера, кроме контроллера по умолчанию "index", и данные отправляются клиенту, который затем удаляет хеш и использует информацию после хеша для загрузки данных через AJAX. Вот код контроллера обработчика ошибок:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net;
using System.Net.Http;
using System.Web.Http;
using System.Web.Routing;
namespace eShop.Controllers
{
public class ErrorController : ApiController
{
[HttpGet, HttpPost, HttpPut, HttpDelete, HttpHead, HttpOptions, AcceptVerbs("PATCH"), AllowAnonymous]
public HttpResponseMessage Handle404()
{
string [] parts = Request.RequestUri.OriginalString.Split(new[] { '?' }, StringSplitOptions.RemoveEmptyEntries);
string parameters = parts[ 1 ].Replace("aspxerrorpath=","");
var response = Request.CreateResponse(HttpStatusCode.Redirect);
response.Headers.Location = new Uri(parts[0].Replace("Error","") + string.Format("#{0}", parameters));
return response;
}
}
}
Но как насчет уродливых URL? Они создаются ботом Google и должны возвращать простой HTML, который содержит все данные, которые пользователь видит в браузере. Для этого я использую фантомы. Phantom - это безголовый браузер, который делает то же, что и браузер на стороне клиента, но на стороне сервера. Другими словами, фантом знает (среди прочего), как получить веб-страницу через URL-адрес, проанализировать ее, включая выполнение всего кода javascript (а также получение данных с помощью вызовов AJAX), и вернуть вам HTML, который отражает ДОМ. Если вы используете MS Visual Studio Express, многие хотят установить фантом по этой ссылке.
Но сначала, когда на сервер отправляется некрасивый URL, мы должны его перехватить; Для этого я добавил в папку "App_start" следующий файл:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Reflection;
using System.Web;
using System.Web.Mvc;
using System.Web.Routing;
namespace eShop.App_Start
{
public class AjaxCrawlableAttribute : ActionFilterAttribute
{
private const string Fragment = "_escaped_fragment_";
public override void OnActionExecuting(ActionExecutingContext filterContext)
{
var request = filterContext.RequestContext.HttpContext.Request;
if (request.QueryString[Fragment] != null)
{
var url = request.Url.ToString().Replace("?_escaped_fragment_=", "#");
filterContext.Result = new RedirectToRouteResult(
new RouteValueDictionary { { "controller", "HtmlSnapshot" }, { "action", "returnHTML" }, { "url", url } });
}
return;
}
}
}
Это вызывается из 'filterConfig.cs' также в 'App_start':
using System.Web.Mvc;
using eShop.App_Start;
namespace eShop
{
public class FilterConfig
{
public static void RegisterGlobalFilters(GlobalFilterCollection filters)
{
filters.Add(new HandleErrorAttribute());
filters.Add(new AjaxCrawlableAttribute());
}
}
}
Как вы можете видеть, AjaxCrawlableAttribute направляет некрасивые URL-адреса в контроллер с именем "HtmlSnapshot", и вот этот контроллер:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Web;
using System.Web.Mvc;
namespace eShop.Controllers
{
public class HtmlSnapshotController : Controller
{
public ActionResult returnHTML(string url)
{
string appRoot = Path.GetDirectoryName(AppDomain.CurrentDomain.BaseDirectory);
var startInfo = new ProcessStartInfo
{
Arguments = String.Format("{0} {1}", Path.Combine(appRoot, "seo\\createSnapshot.js"), url),
FileName = Path.Combine(appRoot, "bin\\phantomjs.exe"),
UseShellExecute = false,
CreateNoWindow = true,
RedirectStandardOutput = true,
RedirectStandardError = true,
RedirectStandardInput = true,
StandardOutputEncoding = System.Text.Encoding.UTF8
};
var p = new Process();
p.StartInfo = startInfo;
p.Start();
string output = p.StandardOutput.ReadToEnd();
p.WaitForExit();
ViewData["result"] = output;
return View();
}
}
}
Связанный view очень просто, всего одна строка кода: @Html.Raw( ViewBag.result )
Как вы можете видеть в контроллере, фантом загружает файл JavaScript с именем createSnapshot.js в папке, которую я создал, называется seo, Вот этот файл JavaScript:
var page = require('webpage').create();
var system = require('system');
var lastReceived = new Date().getTime();
var requestCount = 0;
var responseCount = 0;
var requestIds = [];
var startTime = new Date().getTime();
page.onResourceReceived = function (response) {
if (requestIds.indexOf(response.id) !== -1) {
lastReceived = new Date().getTime();
responseCount++;
requestIds[requestIds.indexOf(response.id)] = null;
}
};
page.onResourceRequested = function (request) {
if (requestIds.indexOf(request.id) === -1) {
requestIds.push(request.id);
requestCount++;
}
};
function checkLoaded() {
return page.evaluate(function () {
return document.all["compositionComplete"];
}) != null;
}
// Open the page
page.open(system.args[1], function () { });
var checkComplete = function () {
// We don't allow it to take longer than 5 seconds but
// don't return until all requests are finished
if ((new Date().getTime() - lastReceived > 300 && requestCount === responseCount) || new Date().getTime() - startTime > 10000 || checkLoaded()) {
clearInterval(checkCompleteInterval);
var result = page.content;
//result = result.substring(0, 10000);
console.log(result);
//console.log(results);
phantom.exit();
}
}
// Let us check to see if the page is finished rendering
var checkCompleteInterval = setInterval(checkComplete, 300);
Сначала я хочу поблагодарить Томаса Дэвиса за страницу, с которой я получил основной код:-).
Здесь вы заметите что-то странное: фантом продолжает загружать страницу до тех пор, пока checkLoaded() функция возвращает истину. Это почему? это потому, что мой специальный SPA делает несколько AJAX-вызовов, чтобы получить все данные и поместить их в DOM на моей странице, и фантом не может знать, когда все вызовы завершены, прежде чем вернуть мне обратно HTML-отражение DOM. То, что я сделал здесь, после последнего вызова AJAX, я добавляю <span id='compositionComplete'></span>, так что если этот тег существует, я знаю, что DOM завершен. Я делаю это в ответ на Durandal's compositionComplete событие, см. здесь для получения дополнительной информации. Если этого не произойдет в течение 10 секунд, я сдаюсь (это займет всего одну секунду, чтобы максимально). Возвращенный HTML-код содержит все ссылки, которые пользователь видит в браузере. Скрипт не будет работать должным образом, потому что <script> теги, которые существуют в снимке HTML, не ссылаются на правильный URL. Это также может быть изменено в фантомном файле javascript, но я не думаю, что это необходимо, потому что моментальный снимок HTML используется только Google для получения a ссылки и не запускать JavaScript; эти ссылки ссылаются на симпатичный URL-адрес, и если на самом деле, если вы попытаетесь просмотреть снимок HTML в браузере, вы получите ошибки javascript, но все ссылки будут работать правильно и на этот раз снова направят вас на сервер с симпатичным URL-адресом получить полностью рабочую страницу.
Это оно. Теперь сервер знает, как обрабатывать как красивые, так и некрасивые URL, с включенным push-состоянием как на сервере, так и на клиенте. Все уродливые URL обрабатываются одинаково с использованием фантома, поэтому нет необходимости создавать отдельный контроллер для каждого типа вызова.
Одна вещь, которую вы могли бы предпочесть изменить, это не сделать общий вызов category / subCategory / product, а добавить store, чтобы ссылка выглядела примерно так: http://www.xyz.com/store/category/subCategory/product111, Это позволит избежать проблемы в моем решении, заключающейся в том, что все недопустимые URL-адреса обрабатываются так, как будто они фактически являются вызовами контроллера "индекса", и я предполагаю, что они могут быть обработаны затем в контроллере "магазина" без добавления к web.config Я показал выше.
Google теперь может отображать страницы SPA: устарела наша схема сканирования AJAX
Вот ссылка на скринкаст с моего учебного класса Ember.js, который я провел в Лондоне 14 августа. В нем описывается стратегия как для вашего клиентского приложения, так и для вашего серверного приложения, а также дается живая демонстрация того, как реализация этих функций обеспечит вашему одностраничному приложению JavaScript постепенную деградацию даже для пользователей с отключенным JavaScript,
Он использует PhantomJS, чтобы помочь в сканировании вашего сайта.
Короче говоря, необходимые шаги:
- Если у вас есть размещаемая версия веб-приложения, которое вы хотите сканировать, на этом сайте должны быть ВСЕ данные, имеющиеся у вас в работе.
- Напишите JavaScript-приложение (PhantomJS Script) для загрузки вашего сайта
- Добавьте index.html (или "/") в список URL для сканирования
- Вставьте первый URL, добавленный в список сканирования
- Загрузить страницу и отобразить ее DOM
- Найдите любые ссылки на загруженной странице, которые ссылаются на ваш собственный сайт (фильтрация URL)
- Добавьте эту ссылку в список "просматриваемых" URL, если она еще не просканирована
- Сохраните обработанный DOM в файл в файловой системе, но сначала удалите ВСЕ скриптовые теги
- В конце создайте файл Sitemap.xml с просканированными URL
После того, как этот шаг будет выполнен, ваш сервер сможет использовать статическую версию HTML как часть тега noscript на этой странице. Это позволит Google и другим поисковым системам сканировать каждую страницу на вашем сайте, даже если ваше приложение изначально представляет собой приложение на одну страницу.
Ссылка на скринкаст с полной информацией:
я использовал
RendertronЧтобы решить проблему SEO в Angular на стороне клиента, это промежуточное программное обеспечение, которое различает запросы в зависимости от того, является ли он сканером или клиентом, поэтому, когда запрос поступает со стороны сканера, ответ генерируется быстро и быстро на лету.
отрендеренный сайт для обычных клиентов:
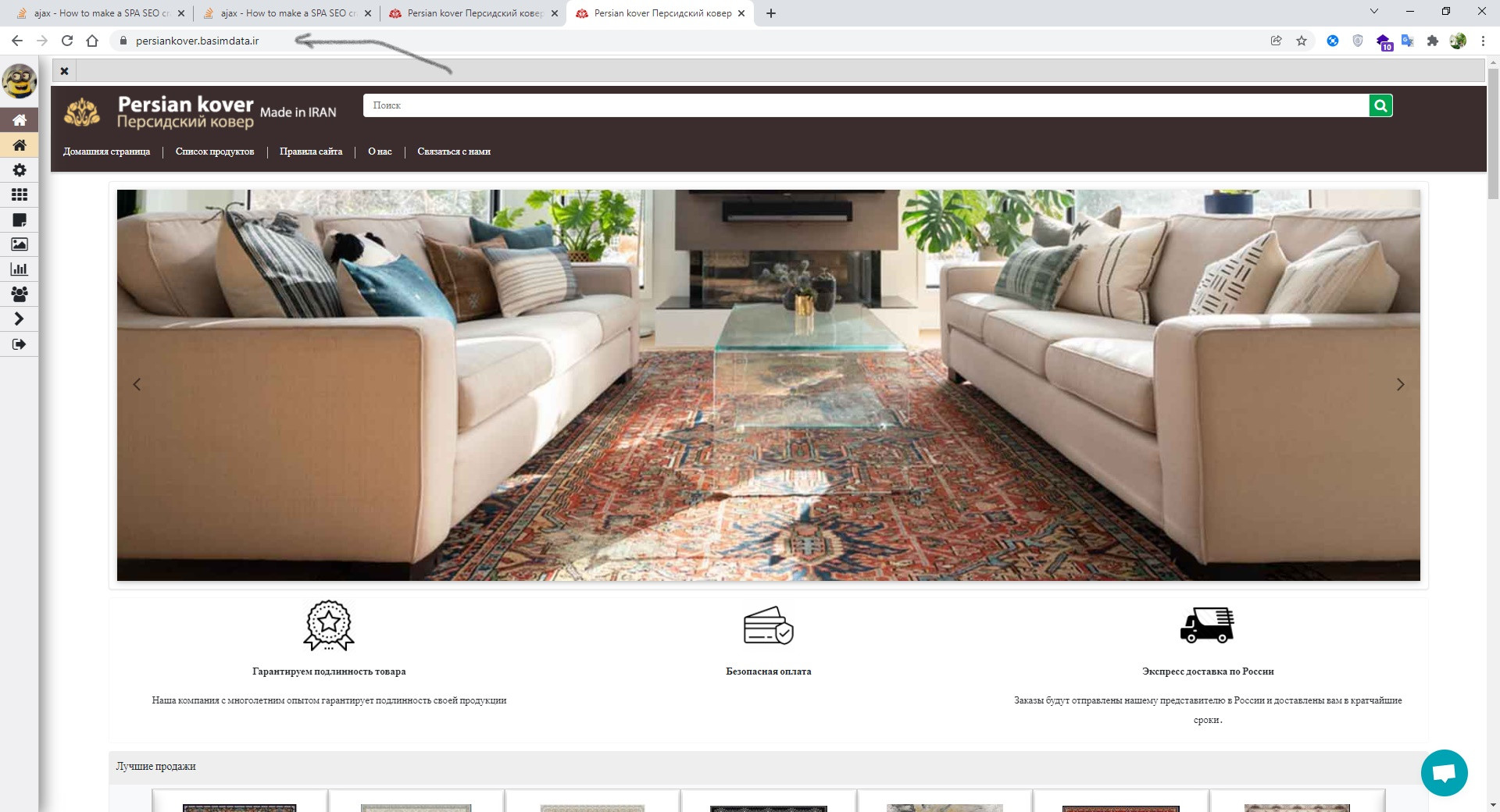
отрендеренный сайт для краулеров:
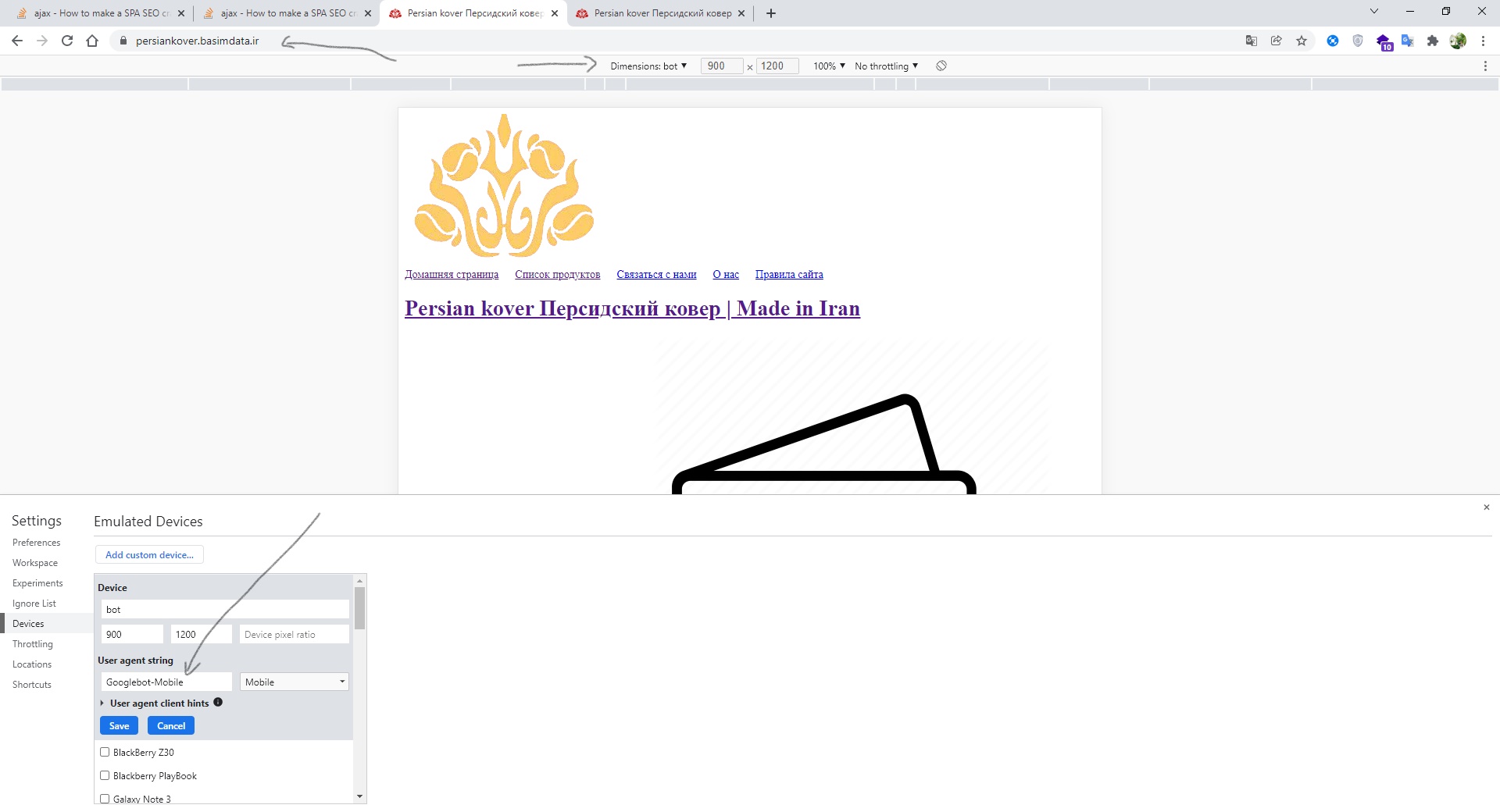
В
Startup.cs
Настройте сервисы рендертрона:
public void ConfigureServices(IServiceCollection services)
{
// Add rendertron services
services.AddRendertron(options =>
{
// rendertron service url
options.RendertronUrl = "http://rendertron:3000/render/";
// proxy url for application
options.AppProxyUrl = "http://webapplication";
// prerender for firefox
//options.UserAgents.Add("firefox");
// inject shady dom
options.InjectShadyDom = true;
// use http compression
options.AcceptCompression = true;
});
}
Это правда, что этот метод немного отличается и требует короткого кода для создания содержимого, характерного для сканера, но он полезен для небольших проектов, таких как CMS или сайт-портал и т. д.
Этот метод можно выполнить на большинстве языков программирования или серверных фреймворков, таких как
ASP.net core,
Python (Django),
Express.js,
Firebase.
Чтобы просмотреть исходный код и более подробную информацию: https://github.com/GoogleChrome/rendertron
Обновление 2021 года
SPA должен использовать History API , чтобы быть оптимизированным для SEO.
Переходы между SPA-страницами обычно осуществляются через
history.pushState(path)вызов. Дальнейшее зависит от фреймворка. В случае использования React компонент под названием React Router отслеживаетhistoryи отображает/рендерит компонент React, настроенный дляpathиспользовал.Добиться SEO для простого SPA несложно .
Достижение SEO для более продвинутого SPA (который использует выборочную предварительную отрисовку для повышения производительности) более сложно, как показано в статье . Я автор.
Вы можете использовать или создать свой собственный сервис для предварительной передачи вашего SPA с помощью службы, называемой prerender. Вы можете проверить это на его веб-сайте https://prerender.io/ и в его проекте github (он использует PhantomJS и обновляет ваш сайт для вас).
Это очень легко начать с. Вам нужно только перенаправить запросы сканерам в службу, и они получат визуализированный html.
Вы можете использовать http://sparender.com/ что позволяет правильно сканировать одностраничные приложения.