Каков наилучший способ удалить акценты в строке Unicode Python?
У меня есть строка Unicode в Python, и я хотел бы удалить все акценты (диакритические знаки).
Я нашел в Интернете элегантный способ сделать это на Java:
- преобразовать строку Unicode в ее длинную нормализованную форму (с отдельным символом для букв и диакритических знаков)
- удалить все символы, у которых тип Unicode "диакритический".
Нужно ли устанавливать такую библиотеку, как pyICU, или это возможно только с помощью стандартной библиотеки python? А как насчет Python 3?
Важное примечание: я бы хотел избежать кода с явным отображением символов с акцентом на их не акцентированный аналог.
16 ответов
Unidecode - правильный ответ для этого. Он транслитерирует любую строку Юникода в максимально близкое представление в тексте ascii.
Пример:
accented_string = u'Málaga'
# accented_string is of type 'unicode'
import unidecode
unaccented_string = unidecode.unidecode(accented_string)
# unaccented_string contains 'Malaga'and is of type 'str'
Как насчет этого:
import unicodedata
def strip_accents(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
Это работает и на греческих буквах:
>>> strip_accents(u"A \u00c0 \u0394 \u038E")
u'A A \u0394 \u03a5'
>>>
Категория персонажа "Mn" обозначает Nonspacing_Mark, что похоже на unicodedata.combining в ответе MiniQuark (я не думал об unicodedata.combining, но, вероятно, это лучшее решение, потому что оно более явное).
И имейте в виду, что эти манипуляции могут значительно изменить смысл текста. Акценты, умлауты и т. Д. Не являются "украшением".
Я только что нашел этот ответ в Интернете:
import unicodedata
def remove_accents(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str)
only_ascii = nfkd_form.encode('ASCII', 'ignore')
return only_ascii
Он отлично работает (например, для французского), но я думаю, что второй шаг (удаление акцентов) может быть обработан лучше, чем удаление символов, не входящих в ASCII, потому что это не удастся для некоторых языков (например, греческого). Лучшим решением, вероятно, будет явное удаление символов Юникода, помеченных как диакритические знаки.
Изменить: это делает трюк:
import unicodedata
def remove_accents(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str)
return u"".join([c for c in nfkd_form if not unicodedata.combining(c)])
unicodedata.combining(c) вернет истину, если персонаж c может сочетаться с предыдущим символом, то есть главным образом, если это диакритический знак.
Изменить 2: remove_accents ожидает Unicode- строку, а не байтовую строку. Если у вас есть строка байтов, то вы должны декодировать ее в строку Unicode, например:
encoding = "utf-8" # or iso-8859-15, or cp1252, or whatever encoding you use
byte_string = b"café" # or simply "café" before python 3.
unicode_string = byte_string.decode(encoding)
На самом деле я работаю над проектами, совместимыми с Python 2.6, 2.7 и 3.4, и мне нужно создавать идентификаторы из бесплатных записей пользователя.
Благодаря вам, я создал эту функцию, которая творит чудеса.
import re
import unicodedata
def strip_accents(text):
"""
Strip accents from input String.
:param text: The input string.
:type text: String.
:returns: The processed String.
:rtype: String.
"""
try:
text = unicode(text, 'utf-8')
except (TypeError, NameError): # unicode is a default on python 3
pass
text = unicodedata.normalize('NFD', text)
text = text.encode('ascii', 'ignore')
text = text.decode("utf-8")
return str(text)
def text_to_id(text):
"""
Convert input text to id.
:param text: The input string.
:type text: String.
:returns: The processed String.
:rtype: String.
"""
text = strip_accents(text.lower())
text = re.sub('[ ]+', '_', text)
text = re.sub('[^0-9a-zA-Z_-]', '', text)
return text
результат:
text_to_id("Montréal, über, 12.89, Mère, Françoise, noël, 889")
>>> 'montreal_uber_1289_mere_francoise_noel_889'
Это обрабатывает не только акценты, но и "удары" (как в ø и т. Д.):
import unicodedata as ud
def rmdiacritics(char):
'''
Return the base character of char, by "removing" any
diacritics like accents or curls and strokes and the like.
'''
desc = ud.name(unicode(char))
cutoff = desc.find(' WITH ')
if cutoff != -1:
desc = desc[:cutoff]
return ud.lookup(desc)
Это самый изящный способ, которым я могу придумать (и он был упомянут Алексисом в комментарии на этой странице), хотя я не думаю, что это действительно очень элегантно.
Есть еще специальные буквы, которые не обрабатываются этим, такие как перевернутые и перевернутые буквы, так как их имя в юникоде не содержит "WITH". Это зависит от того, что вы хотите сделать в любом случае. Иногда мне требовалось удаление акцента для достижения порядка сортировки словаря.
На мой взгляд, предлагаемые решения НЕ ДОЛЖНЫ быть принятыми ответами. Исходный вопрос просит убрать акценты , поэтому правильный ответ должен делать только это, а не плюс другие, неуказанные, изменения.
Просто посмотрите на результат этого кода, который является принятым ответом. где я заменил "Málaga" на "Málagueña:
accented_string = u'Málagueña'
# accented_string is of type 'unicode'
import unidecode
unaccented_string = unidecode.unidecode(accented_string)
# unaccented_string contains 'Malaguena'and is of type 'str'
Есть дополнительное изменение (ñ -> n), которое не запрашивается в OQ.
Простая функция, которая выполняет запрошенную задачу в более низкой форме:
def f_remove_accents(old):
"""
Removes common accent characters, lower form.
Uses: regex.
"""
new = old.lower()
new = re.sub(r'[àáâãäå]', 'a', new)
new = re.sub(r'[èéêë]', 'e', new)
new = re.sub(r'[ìíîï]', 'i', new)
new = re.sub(r'[òóôõö]', 'o', new)
new = re.sub(r'[ùúûü]', 'u', new)
return new
gensim.utils.deaccent(текст) от Gensim - тема моделирования для людей:
deaccent("Šéf chomutovských komunistů dostal poštou bílý prášek")
'Sef chomutovskych komunistu dostal postou bily prasek'
Другое решение - unidecode.
Не то, чтобы предлагаемое решение с unicodedata обычно удаляло акценты только в некотором символе (например, это поворачивает 'ł' в '', а не в 'l').
В ответ на ответ @MiniQuark:
Я пытался прочитать в CSV-файл, который был наполовину французским (с акцентами), а также некоторые строки, которые в конечном итоге стали бы целыми числами и числами с плавающей точкой. В качестве теста я создал test.txt файл, который выглядел так:
Монреаль, über, 12.89, Mère, Франсуаза, noël, 889
Я должен был включить строки 2 а также 3 чтобы заставить его работать (что я нашел в билете на Python), а также включить комментарий @Jabba:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import csv
import unicodedata
def remove_accents(input_str):
nkfd_form = unicodedata.normalize('NFKD', unicode(input_str))
return u"".join([c for c in nkfd_form if not unicodedata.combining(c)])
with open('test.txt') as f:
read = csv.reader(f)
for row in read:
for element in row:
print remove_accents(element)
Результат:
Montreal
uber
12.89
Mere
Francoise
noel
889
(Примечание: я нахожусь на Mac OS X 10.8.4 и использую Python 2.7.3)
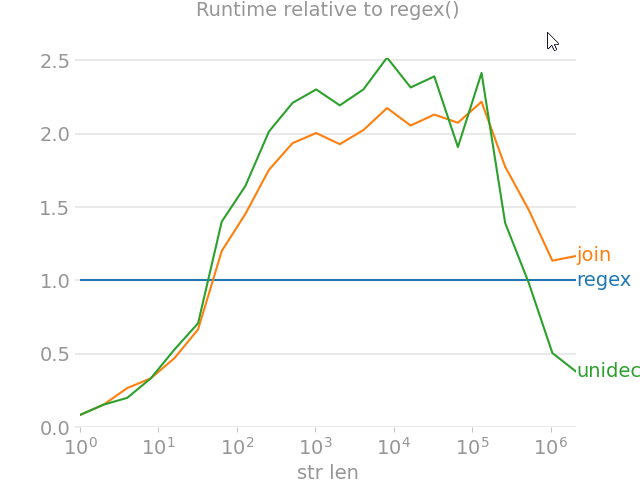
import unicodedata
from random import choice
import perfplot
import regex
import text_unidecode
def remove_accent_chars_regex(x: str):
return regex.sub(r'\p{Mn}', '', unicodedata.normalize('NFKD', x))
def remove_accent_chars_join(x: str):
# answer by MiniQuark
# https://stackoverflow.com/a/517974/7966259
return u"".join([c for c in unicodedata.normalize('NFKD', x) if not unicodedata.combining(c)])
perfplot.show(
setup=lambda n: ''.join([choice('Málaga François Phút Hơn 中文') for i in range(n)]),
kernels=[
remove_accent_chars_regex,
remove_accent_chars_join,
text_unidecode.unidecode,
],
labels=['regex', 'join', 'unidecode'],
n_range=[2 ** k for k in range(22)],
equality_check=None, relative_to=0, xlabel='str len'
)
import unicodedata
s = 'Émission'
search_string = ''.join((c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn'))
Для Python 3.X
print (search_string)
Для Python 2.X
print search_string
Вот короткая функция, которая удаляет диакритические знаки, но сохраняет нелатинские символы. Большинство случаев (например,
"à"->
"a") обрабатываются
unicodedata(стандартная библиотека), но несколько (например,
"æ"->
"ae") полагаются на заданные параллельные строки.
Код
from unicodedata import combining, normalize
LATIN = "ä æ ǽ đ ð ƒ ħ ı ł ø ǿ ö œ ß ŧ ü "
ASCII = "ae ae ae d d f h i l o o oe oe ss t ue"
def remove_diacritics(s, outliers=str.maketrans(dict(zip(LATIN.split(), ASCII.split())))):
return "".join(c for c in normalize("NFD", s.lower().translate(outliers)) if not combining(c))
NB.Аргумент по умолчанию
outliersоценивается один раз и не предназначен для предоставления вызывающей стороной.
Предполагаемое использование
В качестве ключа для сортировки списка строк в более «естественном» порядке:
sorted(['cote', 'coteau', "crottez", 'crotté', 'côte', 'côté'], key=remove_diacritics)
Выход:
['cote', 'côte', 'côté', 'coteau', 'crotté', 'crottez']
Если в ваших строках смешаны тексты и числа, вам может быть интересно составить
remove_diacritics()с функцией
string_to_pairs()отдаю в другом месте .
Тесты
Чтобы убедиться, что поведение соответствует вашим потребностям, взгляните на панграммы ниже:
examples = [
("hello, world", "hello, world"),
("42", "42"),
("你好,世界", "你好,世界"),
(
"Dès Noël, où un zéphyr haï me vêt de glaçons würmiens, je dîne d’exquis rôtis de bœuf au kir, à l’aÿ d’âge mûr, &cætera.",
"des noel, ou un zephyr hai me vet de glacons wuermiens, je dine d’exquis rotis de boeuf au kir, a l’ay d’age mur, &caetera.",
),
(
"Falsches Üben von Xylophonmusik quält jeden größeren Zwerg.",
"falsches ueben von xylophonmusik quaelt jeden groesseren zwerg.",
),
(
"Љубазни фењерџија чађавог лица хоће да ми покаже штос.",
"љубазни фењерџија чађавог лица хоће да ми покаже штос.",
),
(
"Ljubazni fenjerdžija čađavog lica hoće da mi pokaže štos.",
"ljubazni fenjerdzija cadavog lica hoce da mi pokaze stos.",
),
(
"Quizdeltagerne spiste jordbær med fløde, mens cirkusklovnen Walther spillede på xylofon.",
"quizdeltagerne spiste jordbaer med flode, mens cirkusklovnen walther spillede pa xylofon.",
),
(
"Kæmi ný öxi hér ykist þjófum nú bæði víl og ádrepa.",
"kaemi ny oexi her ykist þjofum nu baedi vil og adrepa.",
),
(
"Glāžšķūņa rūķīši dzērumā čiepj Baha koncertflīģeļu vākus.",
"glazskuna rukisi dzeruma ciepj baha koncertfligelu vakus.",
)
]
for (given, expected) in examples:
assert remove_diacritics(given) == expected
Вариант с сохранением корпуса
LATIN = "ä æ ǽ đ ð ƒ ħ ı ł ø ǿ ö œ ß ŧ ü Ä Æ Ǽ Đ Ð Ƒ Ħ I Ł Ø Ǿ Ö Œ SS Ŧ Ü "
ASCII = "ae ae ae d d f h i l o o oe oe ss t ue AE AE AE D D F H I L O O OE OE SS T UE"
def remove_diacritics(s, outliers=str.maketrans(dict(zip(LATIN.split(), ASCII.split())))):
return "".join(c for c in normalize("NFD", s.translate(outliers)) if not combining(c))
Здесь уже много ответов, но это ранее не рассматривалось: с помощью sklearn
from sklearn.feature_extraction.text import strip_accents_ascii, strip_accents_unicode
accented_string = u'Málagueña®'
print(strip_accents_unicode(accented_string)) # output: Malaguena®
print(strip_accents_ascii(accented_string)) # output: Malaguena
Это особенно полезно, если вы уже используете sklearn для обработки текста. Это функции, внутренне вызываемые такими классами, как CountVectorizer , для нормализации строк: при использовании
strip_accents='ascii'тогда
strip_accents_asciiназывается и когда
strip_accents='unicode'используется, то
strip_accents_unicodeназывается.
Подробнее
Наконец, рассмотрим эти детали из его строки документации:
Signature: strip_accents_ascii(s)
Transform accentuated unicode symbols into ascii or nothing
Warning: this solution is only suited for languages that have a direct
transliteration to ASCII symbols.
а также
Signature: strip_accents_unicode(s)
Transform accentuated unicode symbols into their simple counterpart
Warning: the python-level loop and join operations make this
implementation 20 times slower than the strip_accents_ascii basic
normalization.
Некоторые языки объединяют диакритические знаки в виде букв языка и диакритических знаков акцента для определения акцента.
Я думаю, что более безопасно явно указать, какие диалектики вы хотите удалить:
def strip_accents(string, accents=('COMBINING ACUTE ACCENT', 'COMBINING GRAVE ACCENT', 'COMBINING TILDE')):
accents = set(map(unicodedata.lookup, accents))
chars = [c for c in unicodedata.normalize('NFD', string) if c not in accents]
return unicodedata.normalize('NFC', ''.join(chars))
Если вы надеетесь получить функциональность, аналогичную Elasticsearch
asciifoldingфильтр, вы можете захотеть рассмотреть свертывание в ascii , которое [само по себе]...
Порт Python для Apache Lucene ASCII Folding Filter, который преобразует буквенные, числовые и символьные символы Unicode, которых нет в первых 127 символах ASCII (блок Unicode «Basic Latin»), в эквиваленты ASCII, если они существуют.
Вот пример со страницы, упомянутой выше:
from fold_to_ascii import fold
s = u'Astroturf® paté'
fold(s)
> u'Astroturf pate'
fold(s, u'?')
> u'Astroturf? pate'
Сделать это можно следующим образом, после установки библиотеки unidecode:
import unidecode
normalize_text = unidecode.unidecode
x = 'ÁâúuùÚ'
normalized_x = normalize_text(x)
print(normalized_x)
# 'AaúuuU'
Результатом будет «AaúuuU», как показано в последней строке.
Я придумал вот это (специально для латинских букв - лингвистических целей)
import string
from functools import lru_cache
import unicodedata
# This can improve performance by avoiding redundant computations when the function is
# called multiple times with the same arguments.
@lru_cache
def lookup(
l: str, case_sens: bool = True, replace: str = "", add_to_printable: str = ""
):
r"""
Look up information about a character and suggest a replacement.
Args:
l (str): The character to look up.
case_sens (bool, optional): Whether to consider case sensitivity for replacements. Defaults to True.
replace (str, optional): The default replacement character when not found. Defaults to ''.
add_to_printable (str, optional): Additional uppercase characters to consider as printable. Defaults to ''.
Returns:
dict: A dictionary containing the following information:
- 'all_data': A sorted list of words representing the character name.
- 'is_printable_letter': True if the character is a printable letter, False otherwise.
- 'is_printable': True if the character is printable, False otherwise.
- 'is_capital': True if the character is a capital letter, False otherwise.
- 'suggested': The suggested replacement for the character based on the provided criteria.
Example:
sen = "Montréal, über, 12.89, Mère, Françoise, noël, 889"
norm = ''.join([lookup(k, case_sens=True, replace='x', add_to_printable='')['suggested'] for k in sen])
print(norm)
#########################
sen2 = 'kožušček'
norm2 = ''.join([lookup(k, case_sens=True, replace='x', add_to_printable='')['suggested'] for k in sen2])
print(norm2)
#########################
sen3="Falsches Üben von Xylophonmusik quält jeden größeren Zwerg."
norm3 = ''.join([lookup(k, case_sens=True, replace='x', add_to_printable='')['suggested'] for k in sen3]) # doesn't preserve ü - ue ...
print(norm3)
#########################
sen4 = "cætera"
norm4 = ''.join([lookup(k, case_sens=True, replace='x', add_to_printable='ae')['suggested'] for k in
sen4])
print(norm4)
# Montreal, uber, 12.89, Mere, Francoise, noel, 889
# kozuscek
# Falsches Uben von Xylophonmusik qualt jeden groseren Zwerg.
# caetera
"""
# The name of the character l is retrieved using the unicodedata.name()
# function and split into a list of words and sorted by len (shortest is the wanted letter)
v = sorted(unicodedata.name(l).split(), key=len)
sug = replace
stri_pri = string.printable + add_to_printable.upper()
is_printable_letter = v[0] in stri_pri
is_printable = l in stri_pri
is_capital = "CAPITAL" in v
# Depending on the values of the boolean variables, the variable sug may be
# updated to suggest a replacement for the character l. If the character is a printable letter,
# the suggested replacement is set to the first word in the sorted list of names (v).
# If case_sens is True and the character is a printable letter but not a capital,
# the suggested replacement is set to the lowercase version of the first word in v.
# If the character is printable, the suggested replacement is set to the character l itself.
if is_printable_letter:
sug = v[0]
if case_sens:
if not is_capital:
sug = v[0].lower()
elif is_printable:
sug = l
return {
"all_data": v,
"is_printable_letter": is_printable_letter,
"is_printable": is_printable,
"is_capital": is_capital,
"suggested": sug,
}
Я придумал еще одно решение, которое также основано на словарях поиска и Numba, но исходный код слишком велик, чтобы публиковать его здесь. Вот ссылка на GitHub: https://github.com/hansalemaos/charchef .