Как происхождение передается в RDD в Apache Spark
Каждый RDD указывает на один и тот же график линии
или же
когда родительская СДР передает свою родословную новой СДР, копируется ли дочерний граф также дочерним графом, так что родительский и дочерний графы имеют разные графы. В этом случае не слишком ли много памяти?
2 ответа
Каждый СДР поддерживает указатель на одного или нескольких родителей, а также метаданные о том, какие у него отношения с родителем. Например, когда мы вызываем val b = a.map() в СДР, СДР b просто хранит ссылку (и никогда не копирует) своего родителя a Это родословная.
И когда драйвер отправляет задание, граф RDD сериализуется на рабочие узлы, так что каждый из рабочих узлов применяет серию преобразований (например, фильтр карты и т. Д.) В разных разделах. Кроме того, эта линия RDD будет использоваться для пересчета данных, если произойдет какой-либо сбой.
Чтобы отобразить происхождение СДР, Spark предоставляет метод отладки toDebugString() метод.
Рассмотрим следующий пример:
val input = sc.textFile("log.txt")
val splitedLines = input.map(line => line.split(" "))
.map(words => (words(0), 1))
.reduceByKey{(a,b) => a + b}
проведение toDebugString() на splitedLines СДР, выведет следующее,
(2) ShuffledRDD[6] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[5] at map at <console>:24 []
| MapPartitionsRDD[4] at map at <console>:23 []
| log.txt MapPartitionsRDD[1] at textFile at <console>:21 []
| log.txt HadoopRDD[0] at textFile at <console>:21 []
Для получения дополнительной информации о том, как Spark работает внутри, прочитайте мой другой пост
Когда вызывается преобразование (карта, фильтр и т. Д.), Оно не выполняется Spark немедленно, вместо этого создается линия для каждого преобразования. Родословная будет отслеживать, какие все преобразования должны быть применены к этому СДР, включая местоположение, откуда оно должно читать данные.
Например, рассмотрим следующий пример
val myRdd = sc.textFile("spam.txt")
val filteredRdd = myRdd.filter(line => line.contains("wonder"))
filteredRdd.count()
sc.textFile() и myRdd.filter() не выполняются немедленно, они будут выполняться только при вызове Action на RDD - здесь FilterRdd.count().
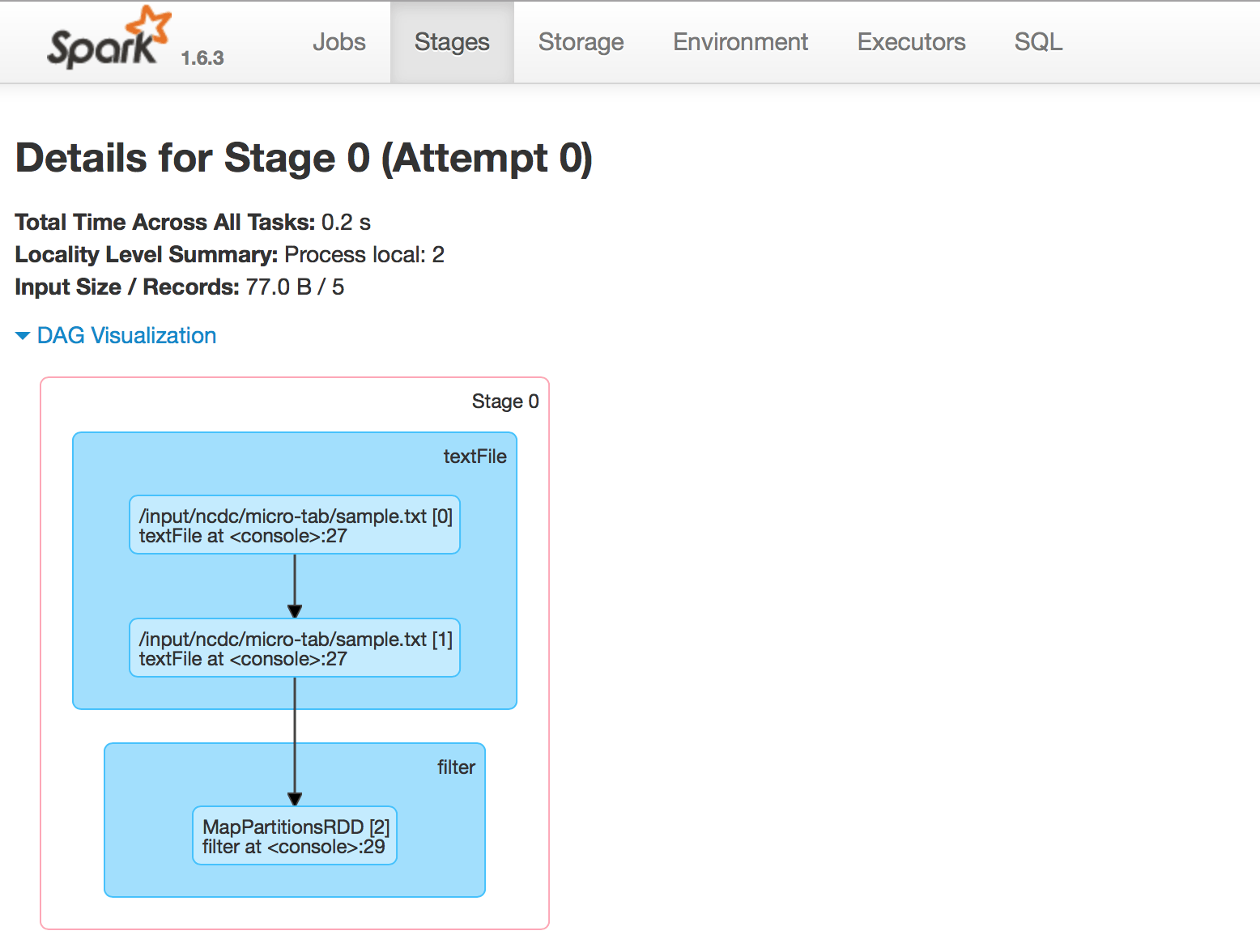
Действие используется для сохранения результата в каком-либо месте или для его отображения. Информация о происхождении СДР также может быть напечатана с помощью команды FilterRdd.toDebugString(здесь указано СДР). Кроме того, DAG Visualization показывает полный график очень интуитивно понятным образом: